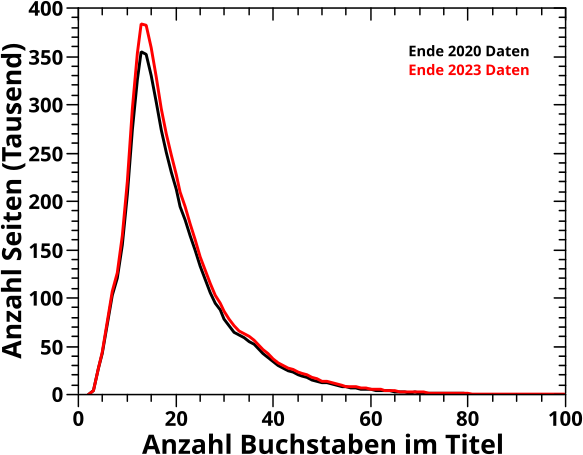
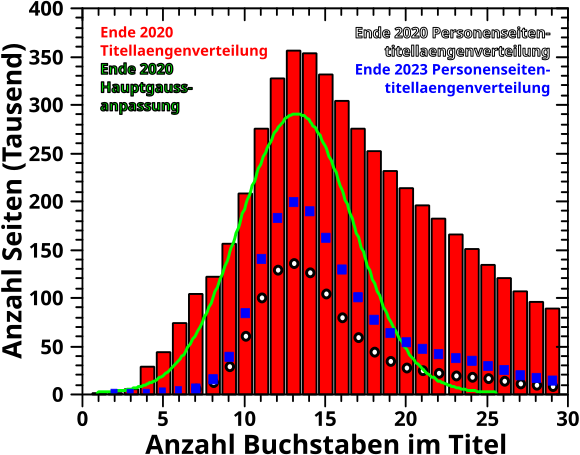
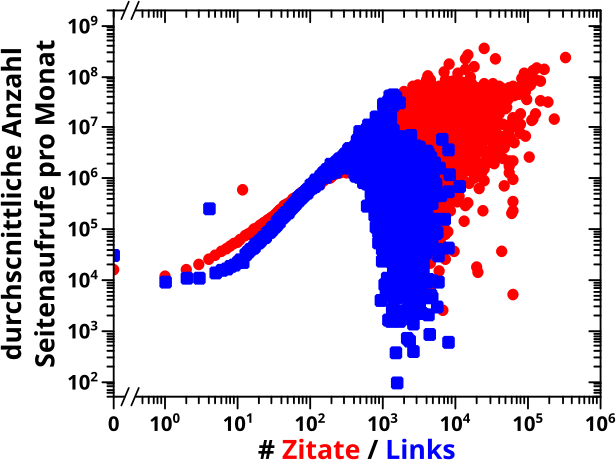
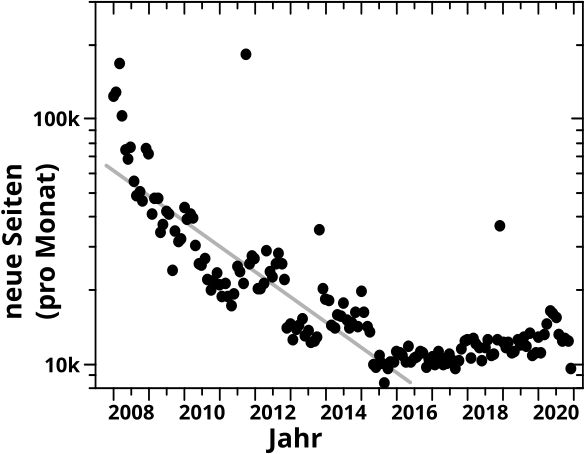
Beim letzten Mal war ich mir noch unsicher, ob ich versuche die Relevanzbetrachtungen zu reproduzieren. Ich dachte, dass man da ohnehin nix sieht. Aber dann packte mich (mal wieder) mein Ehrgeiz und es passierte etwas Aehnlichs wie bei der Simulation von Namen.
Oder vielmehr passierte viel mehr, denn ich schrieb nicht nur den entsprechenden Programmcode neu. Denn beim Neuschreiben verallgemeinerte ich auch alles und entdeckte dabei, dass die Relevanzdiskussion nur ein spezifischer Fall ist, wie die Daten auf diese Art betrachtet werden kønnen. Deswegen der Reihe nach …
… und los geht’s gleich mit dem was eigentlich betrachtetet wird.
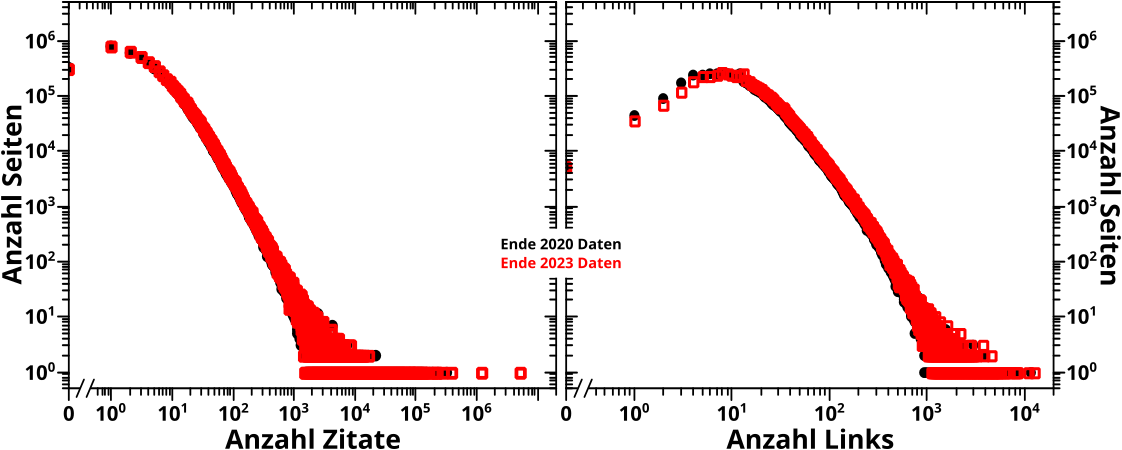
Damals interpretierte ich die Anzahl der Zitate die eine Seite von anderen Seiten erhielt als ein Masz fuer die „Relevanz“ einer Seite. In den zweidimensionalen Falschfarbenbildern repraesentierten die Spalten der Abzsisse und auch die Reihen der Ordinate besagte Anzahl an Zitaten.
Ein Beispiel zur Veranschaulichung: man denke sich eine Seite die insgesamt 3 Zitate erhalten hat. Diese Zitate kamen von einer Seiten die selber nur einmal zitiert wurde, einer Seite mit 23 Zitaten und einer Seite mit 23517 Zitaten. Die erste Zahl entscheidet wo man auf der Abzsisse „landet“; in diesem Fall in Spalte #4 (die Zaehlung geht bei Null los, denn es gibt Seiten die keiner zitiert). Nach oben in dieser Spalte geht der Zaehler in den Zellen #2, #24 und #23518 um eins hoch, denn diese Zellen liegen in den Reihen auf der Ordinate die einem, 23 und 23517 Zitaten (welche die Seiten haben die die allererste Seite zitieren) entsprechen.
Wenn man das fuer alle Wikipediaseiten macht, dann baut sich das zweidimensionale Falschfarbenbild der Reihe nach auf. Bei manchen Zellen geht der Zaehler viele Male um eins nach oben (und die wurden damals rot im Falschfarbenbild) und bei anderen (den meisten) gar nicht (die blieben damals blau).
Oder anders: ich schaute damals wie „relevant“ die Seiten waren, die (andere) Seiten mit einem gegebenen „Relevanzwert“ zitiert haben und hier hatte ich das im Detail besprochen.
Nun ist die Anzahl der Zitate aber nur eins (von zwei) Merkmalen die eine Seite kennzeichnen. Das andere ist die Anzahl der Links.
Zur besseren (wenn auch definitiv nicht richtigen) Veranschaulichung, kønnte man sich besagte Anzahl der Links als eine Art „Recherchewert“ vorstellen. Je mehr Links eine Seite hat, um so besser ist diese recherchiert.
Dann kønnte man schauen, wie gut die Seiten recherchiert sind, die (andere) Seiten mit einem gegebenen „Relevanzwert“ zitiert haben. Man wuerde hier also die Anzahl der Links ueber der Anzahl der Zitate auftragen.
Dieses Diagramm ist aber nicht symmetrisch, denn die Relation wie die Daten zustande kommen geht nur in eine Richtung — (die auf der Ordinate abgetragenen Seiten zitieren die auf der Abszisse abgetragenen Seiten). Man kann das „Links-ueber-Zitate“-Falschfarbenbild also nicht „rueckwaerts“ lesen, wenn man wissen will wie „relevant“ die Seiten waren, die (andere) Seiten mit einem gegebenen „Recherchewert“ zitiert haben. Um das zu untersuchen muss man „Zitate-ueber-Links“-Falschfarbenbild erstellen.
Als Letztes kann man dann auch noch schauen, wie gut die Seiten recherchiert sind, die (andere) Seiten mit einem gegebenen „Recherchewert“ zitiert haben. Das entspricht einem „Links-ueber-Links“-Falschfarbenbild.
Oder anders: die „Bedeutung“ der Achse kann sich aendern, je nachdem, was darauf abgetragen ist. Das wiederum ist ein maechtiges Werkzeug, mit dem man viel ueber die Daten herausfinden kann. Damals ist mir das entgangen und ich entdeckte das erst jetzt, beim nochmals drueber nachdenken.
Nun ist das Kevin Bacon Projekt aber eigentlich abgeschlossen und ich habe auch keine Lust mehr, das alles detailliert zu untersuchen. Andererseits møchte ich besagtes Werkzeug genau besprechen.
In den naechsten paar Beitraegen wird Letzteres passieren und dabei werde ich „zweigleisig“ Diagramme und Falschfarbenbilder praesentieren. Um der Reproduzierbarkeit gerecht zu werden, werde ich Falschfarbenbilder vergleichen, bei denen die „Bedeutung“ beider Achsen der Anzahl der Zitate entspricht, die aber zum Einen aus den Daten von 2020 und zum Anderen aus den Daten von 2023 generiert wurden.
Dies wird aber nur einen (relativ kleinen) Teil ausmachen, denn ich møchte auch die Falschfarbenbilder aller anderen Achsenbedeutungskombinationen vorstellen. Auch dabei werde ich den Vergleich anfuehren, allerdings sind solche Bilder ja auch dann neu, selbst wenn sie mit Daten aus dem Jahre 2020 entstanden sind.
Bei all dem (denn das wird schon genug), werde ich nicht (nochmal) alles genau anschauen. Im Wesentlichen habe ich vor, nur besagte Falschfarbenbilder rein zu stellen als Veranschaulichung dessen, was das Werkzeug kann und ich habe vor den Fokus der Diskussion auf Letzteres zu legen.
Andererseits muss ich auch auf ein paar Dinge im „Dunstkreis“ dieses Werkzeugs eingehen. Auch hier habe ich vor 2020-Daten mit 2023-Daten zu vergleichen.
Das soll reichen fuer heute. Und weil’s systematisch vonstatten gehen soll, muss ich beim naechsten Mal zunaechst den „Relevanzwert“ nochmals genauer betrachten (und dabei zum „Bedeutungswert“ verallgemeinern).