Mit dem vorigen Beitrag møchte ich die „formalen“ Betrachtungen in der Kevin Bacon Maxiserie nach (heute auf den Tag genau) zwei Jahren und elf Monaten abschlieszen. Aber keine Sorge, die drei Jahre kriege ich sicherlich noch voll, denn zwei zu Kevin Bacon gehørende Sachen habe ich noch. Die kommen aber in den „Anhang“, denn bzgl. des Wikipedialinknetzwerkes werde ich nix Neues anfangen.
Zum Einen bin ich vor kurzem auf eine Datenquelle gestoszen, in der fuer jede Seite die tatsaechlichen „so-oft-wurde-ich-angeschaut“-Zahlen zu finden sind. Damit kann ich schauen ob meine Vermutung, dass die Anzahl der (internen) Zitate die eine Seite erhaelt (wie oft diese also auf andenen Seiten verlinkt ist), mit der „Beliebtheit“ (oder auch „Wichtigkeit“) korreliert, stimmt.
Zum Anderen muss ich schauen, ob die Resultate i.A. reproduzierbar sind. Dafuer habe ich mir zum Einen die Wikipedia nochmal beschafft (das war schon im Dezember, also ziemlich genau drei Jahre spaeter). Auszerdem gehe ich gerade durch die vielen (Analyse)Programme welche ich im Zuge dieses Projektes schuf durch und schreibe die nochmal neu aber (hoffentlich) klarer, strukturierter und allgemeiner (oder spezifischer, falls gegeben) … also i.A: besser (hoffentlich). Ebenso verpasse ich den Programmen eine ausfuerhliche Dokumentation. Damit ich das dann auch mal der Welt zur Verfuegung stellen kann.
Beides zusammen genommen ist also eine gute Gelegenheit den neuen Code auf seine Richtigkeit und die vorherigen Ergebnisse auf ihre Reproduzierbarkeit zu ueberpruefen. Das werde ich dann aber i.A. nur noch kurz zeigen à la „Hier ist alt, hier ist neu, passt schon“.
Wieauchimmer, das ist Zukunftsmusik. Der heutige Beitrag soll die Serie „im Geiste“ abschlieszen mittels eines zusammenfassenden Rueckblicks.
Los ging alles mit einer fixen (und definitiv NICHT konkreten) Idee und ich dachte damals, dass das Ganze in sechs Beitraegen fertig wird … HAHA!
Die fuer die Realisierung der Idee nøtigen Rohdaten waren schnell gefunden und in den Beitragen III bis VII sortierte ich all den Kram raus, der fuer die Analyse irrelevant war. Am Ende blieben 5,798,312 Seiten zur Analyse uebrig und so schnell ging’s (mehr als) sechs Beitraege zu schreiben. Dabei hatte ich noch nicht mal angefangen mich damit zu beschaeftigen, womit ich mich urspruenglich beschaeftigen wollte. Auszerdem konnte hier zum ersten Mal ein Phaenomen beobachtet werden, welches im weiteren Verlauf der Maxiserie mit schøner Regelmaeszigkeit auftauchte: eine weitere Unterteilung der „Kapitel“, wenn ein Thema zu viel wurde fuer einen einzigen Beitrag.
Aber dann ging’s endlich richtig los … ich „sprang“ in die Daten um zu schauen, was die mir so erzaehlen … und wurde sofort abgelenkt vom urspruenglichen Ziel, denn ich schaute mir zunaechst an, was man machen kann ohne dass man das Linknetzwerk aller Seiten „abschreitet“.
Die Analyse der Laenge der Titel fand zwar alles unter dem selben rømischen Numeral statt, umfasste aber sechs Beitraege … und brachte mir sogar eine „Superabschweifung“ in Form eines Geburtstagsbeitrags ein :) .
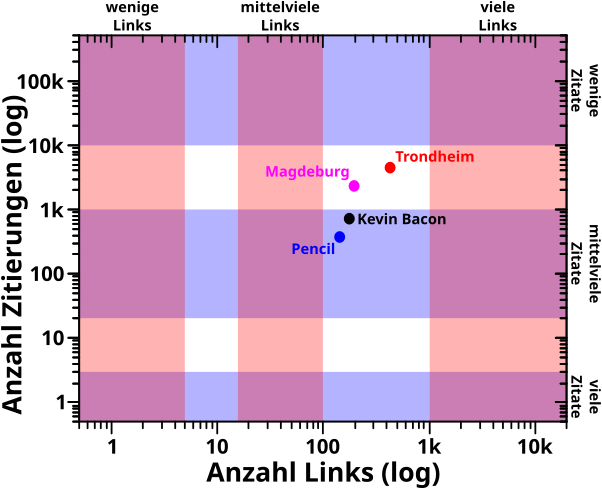
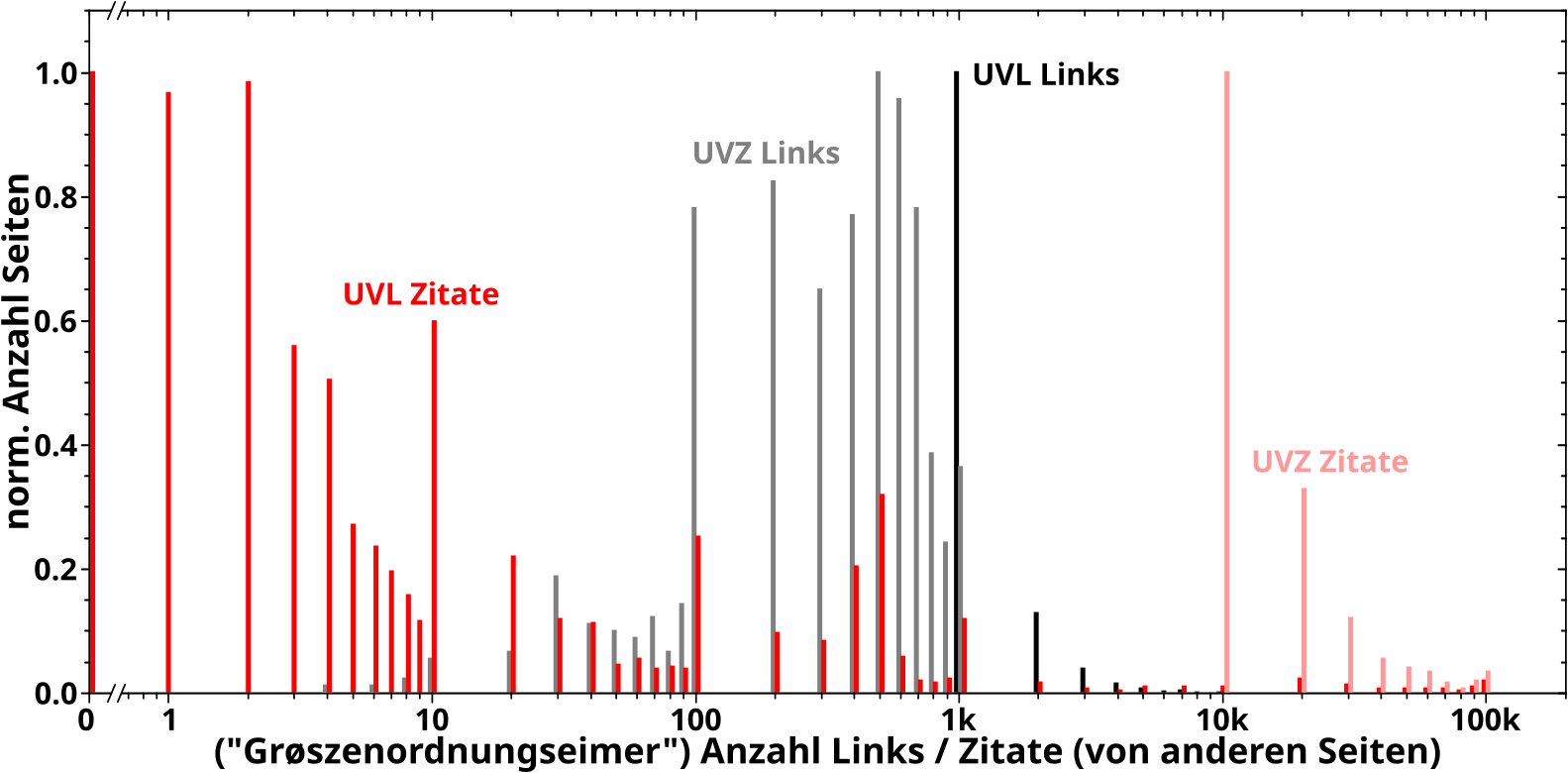
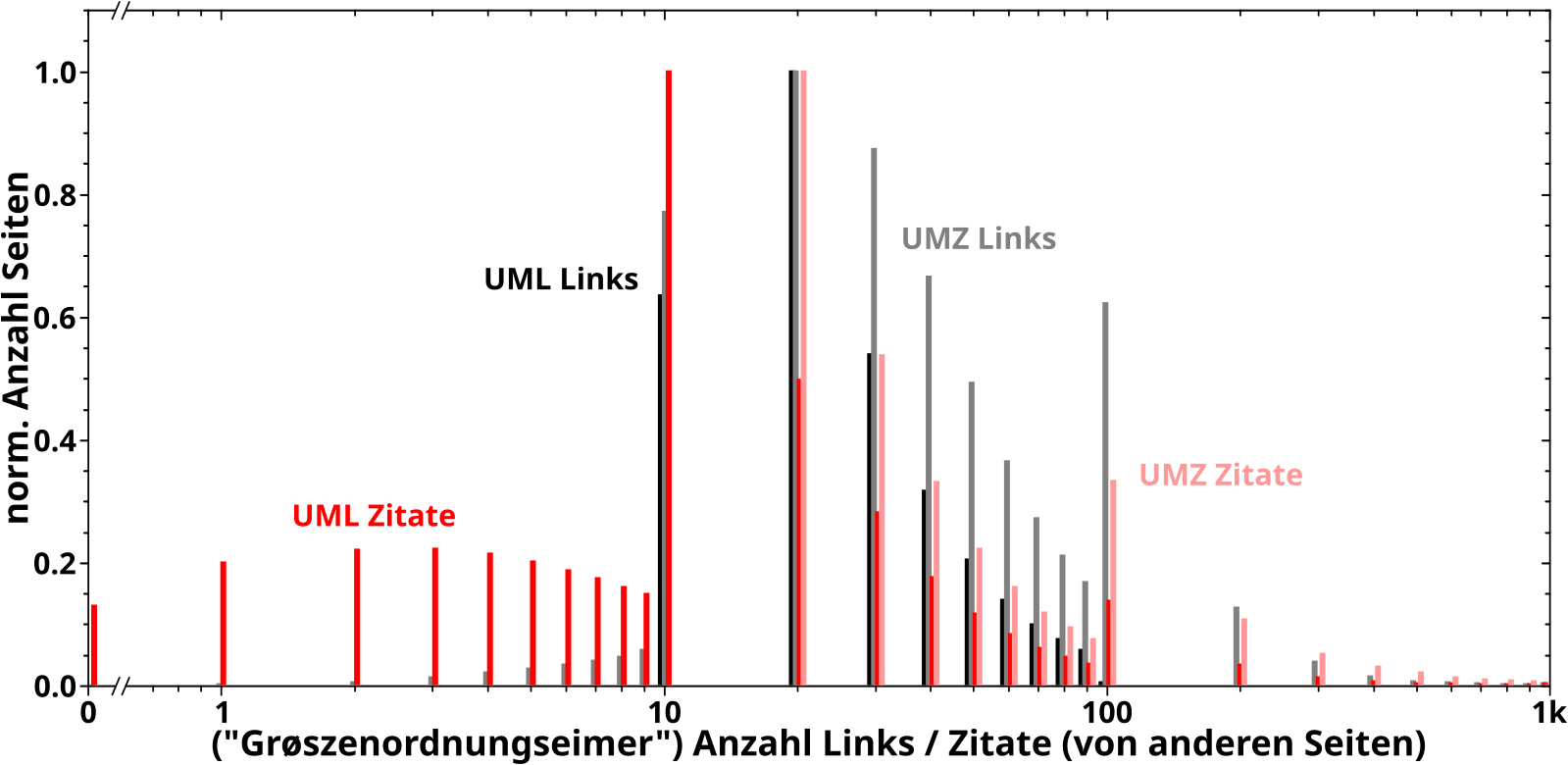
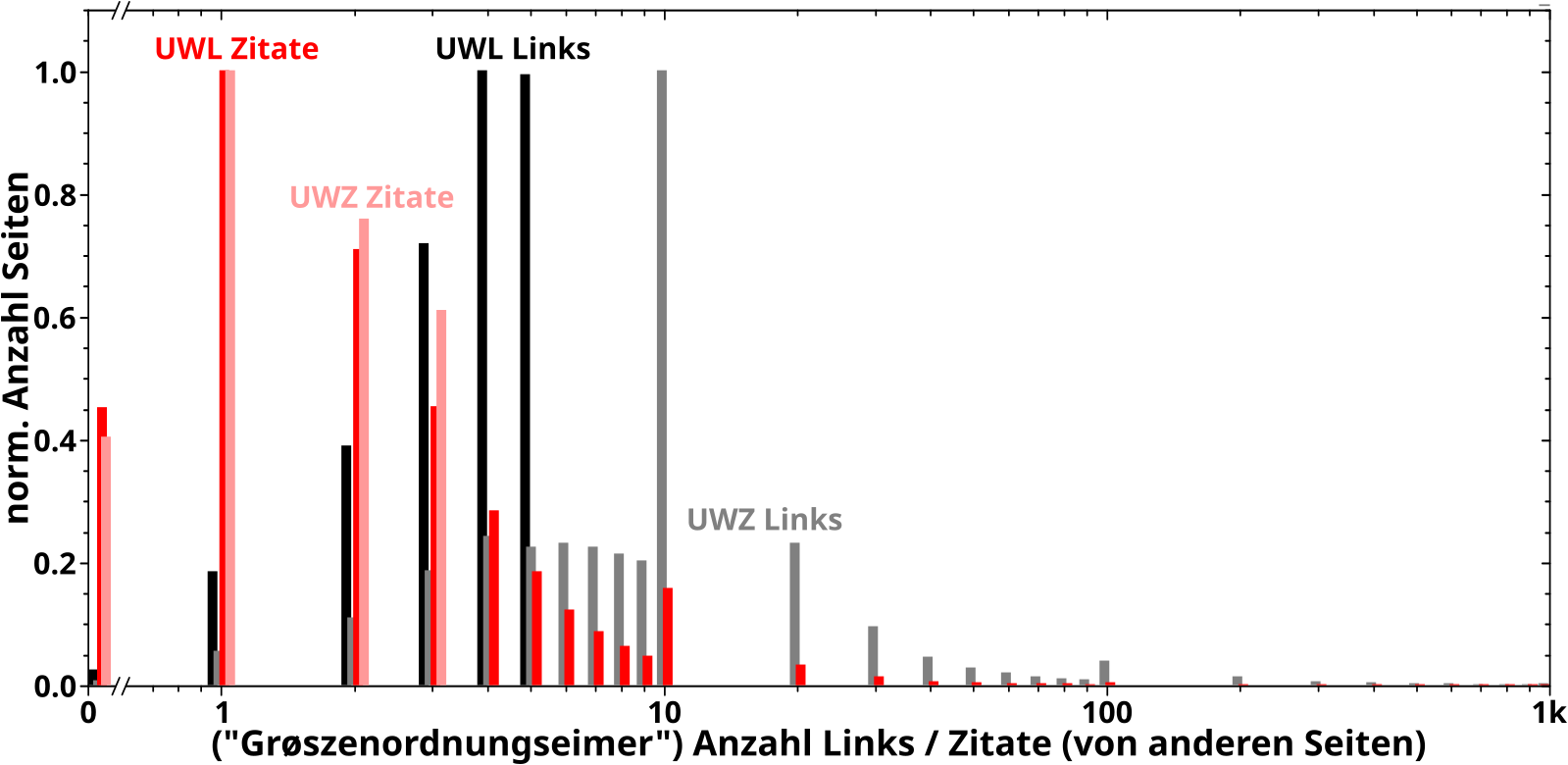
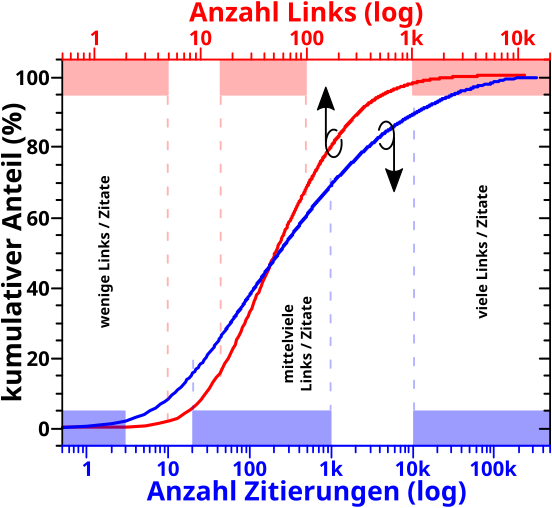
Bei der Analyse wie oft eine Seite (intern) von anderen Seiten zitiert machte mich sofort auf zwei Phaenomene aufmerksam, welche im weiteren Verlauf der Maxiserie immer wieder zur Erklaerung anderer Phaenomene herangezogen wurden. Zum Einen, dass ein paar wenige Seiten urst krass viel øfter zitiert werden als die „durchschnittliche Seite“. Zum Anderen, dass es Seiten gibt die kuenstlich aufgeblaeht sind, einfach weil jemand bspw. zu allen „Dørfern“ eines Landes eine Wikipediaseite mit zwei Saetzen erstellt hat, welche dann immer das lokale Wort fuer „Dorf“ verlinken. Die Wichtigkeit dieser Beobachtungen war mir zu dem Zeitpunkt aber natuerlich noch nicht bewusst.
Desweiteren traten bereits hier doppelllogarithmischer Diagramme und (ein) maechtige(s) Gesetz(e) auf … deren Bedeutsamkeit sich durch die ganze Serie zog und nicht unterschaetzt werden darf!
Unter rømisch zehn tat ich das Gleiche fuer die Anzahl der Links und sehr aehnliche Resultate.
Was mich auf die Idee brachte dies „zusammen zu ziehen“ und die „Relevanzdiskussion“ mal mit Zahlen anzugehen weisz ich nicht mehr. Dabei traten aber zwei Dinge zutage, welche sich ebenso mehr als ein Mal bemerkbar machen sollten.
Zum Einen, dass die Analyse und das Verstaendniss der Daten oft relativ grosze Abstraktionsgrade erfordert. Der Sprung von der Anzahl der Zitate einer Seite zum (lueckenlosen) „Relevanzwert“ einer Seite war da noch recht einfach … was mglw. fuer die kurz darauf folgende „komprimierte Relevanz“ nicht mehr gesagt werden kann.
Zum Anderen, dass es Anomalien in den Daten gibt, die gesonderte, detaillierte Betrachtungen erfordern um sie erklaeren zu kønnen. Zum Glueck bin ich so „gestrickt“, dass mir sowas keine Ruhe laeszt und derartige, oft (eigtl. immer) zeitaufwaendige „Abschweifungen“ von der Masse der Daten hin zu „Minoritaeten“, sollte mir im Weiteren Verlauf der Serie die besten Erlebnisse und Entdeckungen bescheren … wenn auch oftmals nach vielem Haareraufen.
Dann ging es aber endlich weiter … naja … nicht so richtig, denn das Linknetzwerk musste ja erstmal „abgeschritten“ werden, bevor ich mich der urspruenglichen Idee widmen konnte. Dafuer „mathematisierte“ ich von „Kapitel“ XII bis XV das Problem und der einzige „technische“ Artikel der ganzen Serie ist dem „Geniestreich“ gewidmet, der das „Abschreiten“ (und damit die Realisierung der Idee) ueberhaupt erst møglich machte.
Das wahrhaft technische habe ich euch, meinen lieben Leserinnen und Lesern, gar nicht „angetan“ und „versteckte“ es in nur einem einzigen Beitrag. Ich wollte aber wenigstens einen Beitrag haben bzgl. der tatsaechlichen Umsetzung des „Geniestreichs“ in funktionierenden Code, war es doch das, was mir in diesem langen Projekt die grøszte Zufriedenheit brachte. Ich musste naemlich so viele Sachen lernen, von denen ich vorher nicht die geringste Ahnung hatte um sehr spezifische, sehr technische Probleme zu løsen von denen ich vorher noch nicht mal wusste, dass es die gibt. Der Weg zum besagten, nicht nur funktionierenden, sondern auch praktikabel schnellen (!) Code war so befriedigend, dass ich ernsthaft ueberlegte, das Projekt an der Stelle zur Ruhe zu legen … dachte ich doch, dass das nicht getoppt werden kønnte … damit lag ich zwar richtig, aber zu dem Zeitpunkt konnte ich natuerlich noch nichts von den Entdeckungen (und weiteren, zu ueberkommenden Problemen) ahnen, welche mir fast genausoviele intellektuelle Orgasmen bescheren sollten :) .
Ach ja, an der Stelle sollte ich nochmal erwaehnen, dass erst dieser Code die praktische Durchfuehrbarkeit des Projektes ermøglichte. Der „Geniestreich“ machte es prinzipiell møglich, aber erste Implementierungen haetten ein halbes Jahrhundert gebraucht um zu Ergebnissen zu gelangen. Durch besagten Code konnte das auf ca. vier Monate Gesamtrechenzeit reduziert werden (und ca. 2 Monte tatsaechliche Rechenzeit, weil ich mehr als einen Laptop 24/7 damit beschaeftigt hielt).
Und ja, ich bin da bis heute maechtig stolz auf mich … meiner Meinung nach durchaus berechtigt denn bevor ich damit anfing dachte ich immer, dass ich gewisse erwartete Probleme nie im Leben løsen kønnte, weil ich dafuer nicht genug Kompetenz habe … und dann hab ich mir die Kompetenz zu eigen gemacht und das doch geschafft … toll wa :) .
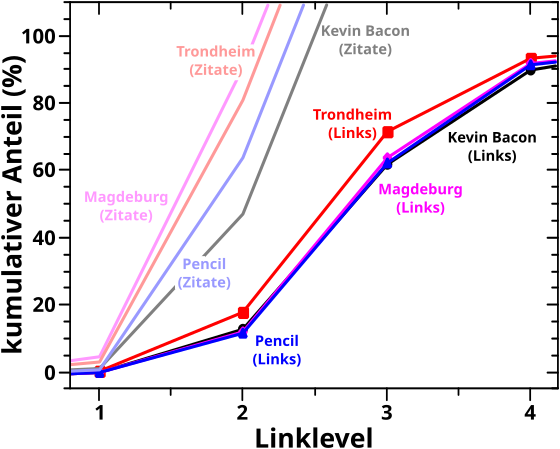
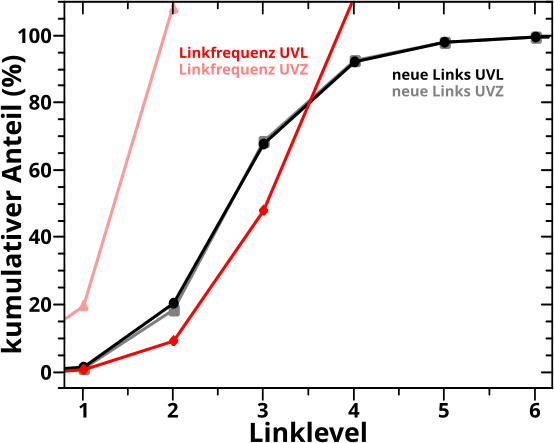
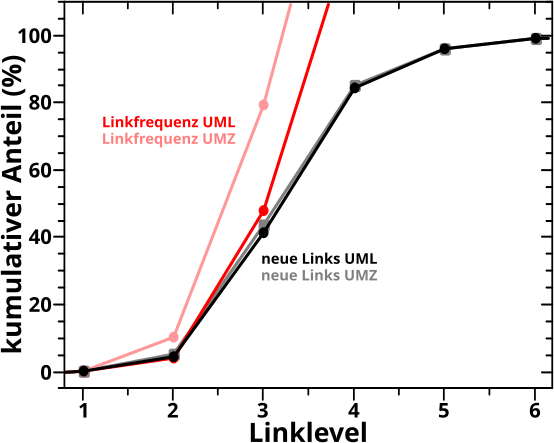
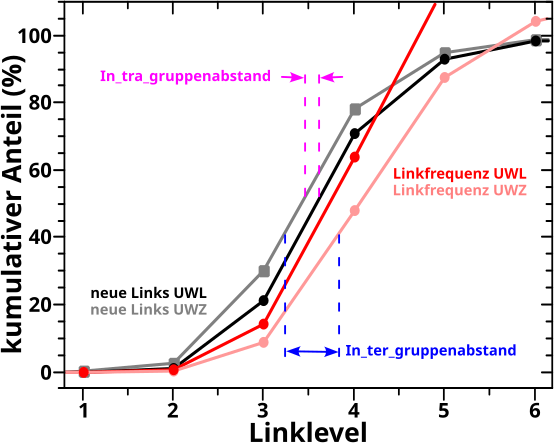
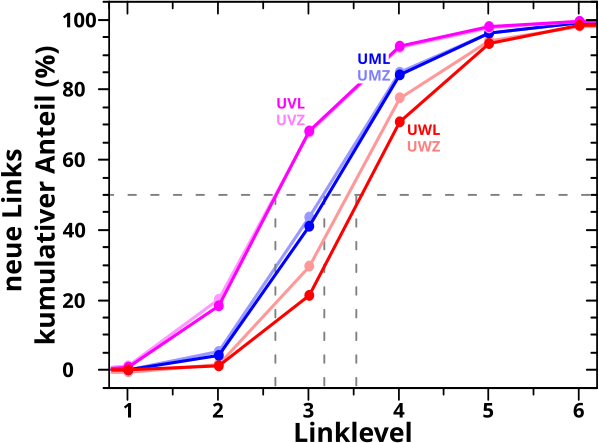
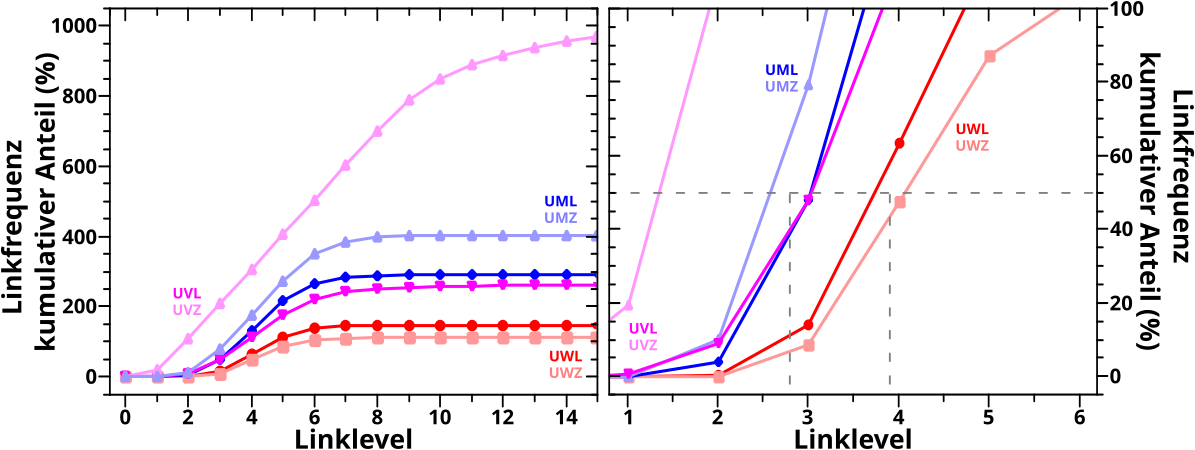
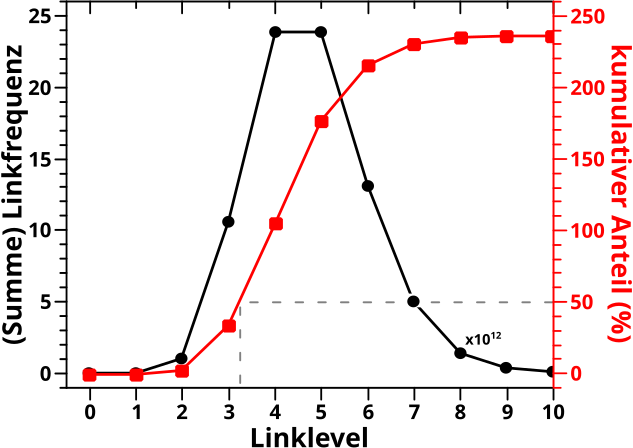
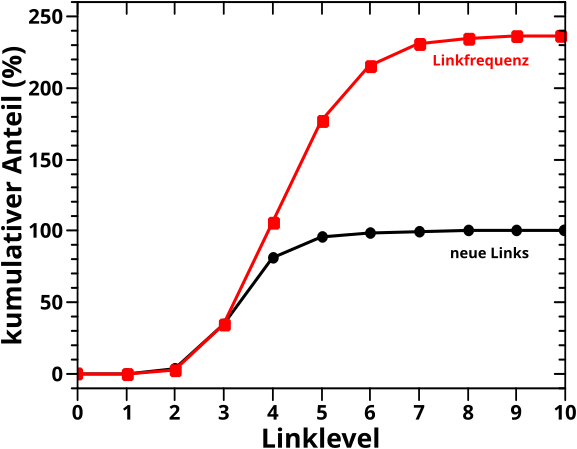
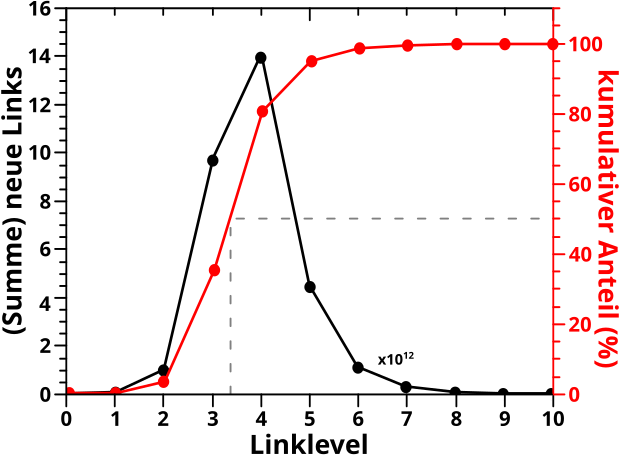
Bevor es dann mit den Untersuchungen der Resultate des „Abschreitens“ des Linknetzwerks aller Wikipediaseiten los gehen konnte, stellte ich in Kapitel XVII die Grøszen vor, deren Entwicklung bei besagter Linknetzwerkanalyse ueberhaupt untersucht wurden. Am schwierigsten … oder eher abstraktesten war dabei die Grøsze, die ich „Linkfrequenz“ nannte. Spaeter stellte sich heraus, dass es sehr gut war, dass ich das mit untersuchte, denn war diese doch sehr sehr „fruchtbar“.
An dieser Stelle breche ich fuer heute ab und fuege dem (urspruenglichen) Titel ein „rømische I“ hinzu. Wie so oft gibt’s mehr zu erzaehlen als in einen Artikel passt … aber es war ja auch (bzw. ist immer noch) eine sehr langanhaltende Serie.