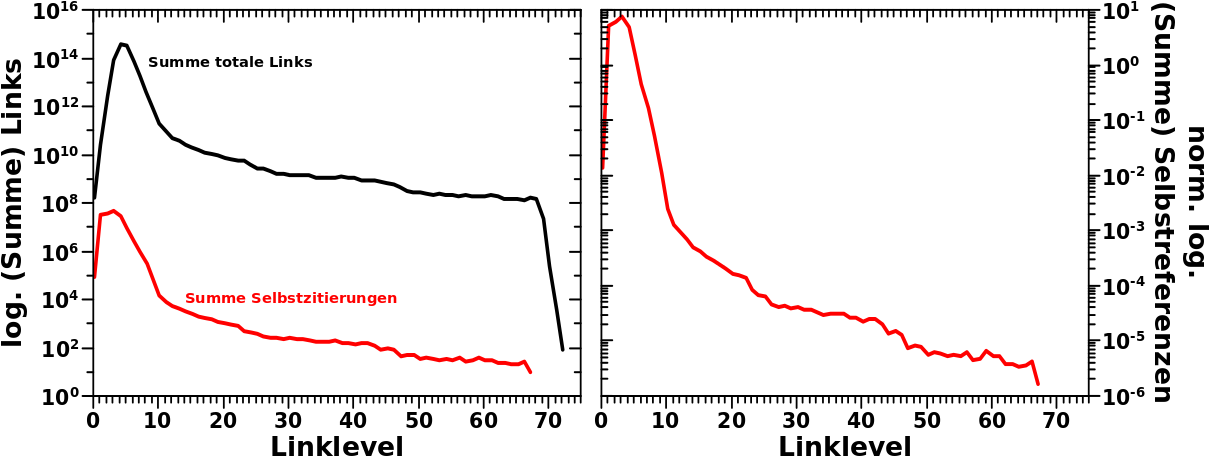
Das wird ein etwas merkwuerdiger Artikel, denn ich werde etwas bereits Bekanntes und Verworfenes nochmals aufgreifen, um dies dann schon wieder zu verwerfen. Aber der Reihe nach.
Alles fing damit an, dass ich beim letzten Mal erwaehnte, dass ich nochmal auf etwas zurueck kommen werde. Dies fuehrte dazu, dass ich mir mal das Verhaeltnis der totalen Links zu den Selbstreferenzen (pro Linklevel) anschaute. Das Ergebnis ist die rote Kurve in diesem Diagramm:
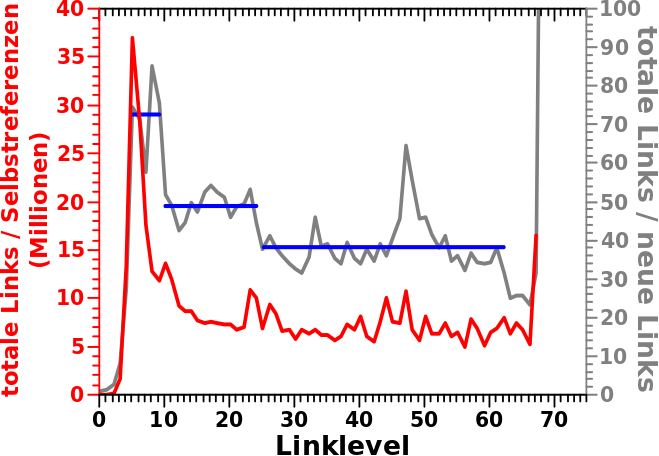
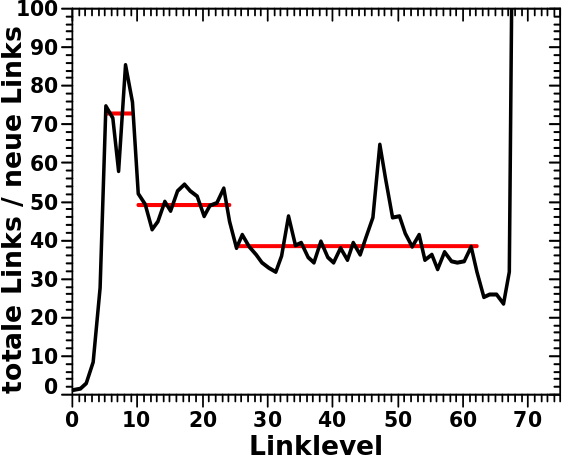
Eine aehnliche „Operation“ fuehrte ich bereits beim vorletzten Mal fuer die neuen Links aus und das dortige Resultat packte ich hier nochmals als graue Kurve dazu. Man beachte, dass jeweils _nur_ die linke Ordinate fuer die rote und _nur_ die rechte Ordinate fuer die graue Kurve gelten. Die horizontalen Linien sind die Mittelwerte der (beim vorletzten Mal erkannten, diskutierten und wieder verworfenen) „Abschnitte“ der grauen Kurve.
Auf den ersten, fluechtigen Blick scheint man in beiden Faellen ungefaehr die gleiche Anzahl an totalen Links (pro Linklevel und relativ zur gemessenen Grøsze) zu haben … ja 40 ist ungefaehr 100. Das ist natuerlich Quatsch, denn das Resultat beim letzten Mal war ja bereits, dass man im Durchschnitt (deutlich) weniger als 10 Selbstreferenzen pro Linklevel hat. Des Raetsels Løsung liegt in der Skalierung der linken Ordinate. Da steht „Millionen“ in Klammern. Die Zahlen auf der linken Seite muessen also alle mit eine Million multipliziert werden.
Wie beim letzten Mal vermutet, sieht man am Anfang der roten Kurve (bis LL5), dass die Anzahl der totalen Links viel schneller zunimmt, als die Anzahl der Selbstreferenzen. Somit ist die dortige Erklaerung fuer das relativ breite Maximum der zugrundeliegenden Verteilung als plausibel anzusehen.
Zu meiner Ueberraschung kann man ab ca. LL22 durchaus einen konstanten Wert fuer das Verhaeltnis dieser beiden Grøszen annehmen. Ich haette erwartet, dass das stetig abnimmt. Es gibt keinen Grund, warum eine Seite bspw. 60 Linklevel nach dem Ursprung noch besagten Ursprung zitieren sollte.
Andererseits sind wir hier in einem Bereich, wo die Anzahl der Selbstreferenzen sowieso nur ein paar hundert und darunter (zum Ende hin eine ganze Grøszenordnung darunter) liegt. Bei immer noch ueber 10 Milliarden totalen Links (ueber alle Linknetzwerke aller Seiten). Das ist also so ’ne Art „Grundzustand“ bzw. erklaerte ich bereits beim letzten Mal, wie das ausfuehrlich besprochene Artefakt zu einem „Grundbeitrag an Selbstreferenzen“ zum Ende hin fuehrt.
Wenn ich aber diesen „Grundzustand“ als richtig annehme, dann sehe ich in der roten Kurve einen Bereich von LL5 bis LL9, der definitiv darueber liegt. Dieser Bereich faellt mit dem ersten Abschnitt der grauen Kurve zusammen. Danach befinde ich mich zwar im Bereich des „Zappelns um den Grundwert“, aber bis ungefaehr LL22 zappelt das nur wenig und es scheint vielmehr stetig nach unten zu gehen; als ob da ein Mechanismus ueber den zufaelligen Schwankungen liegt.
Um Letzteres zu veranschaulichen, denke man sich eine Ente, einen Elefanten, einen Tyrannosaurus welcher im Zickzack ueber einen Fluss ohne Strømung schwimmt … auch wenn ein Flusz ohne Strømung mglw. kein Fluss mehr ist:
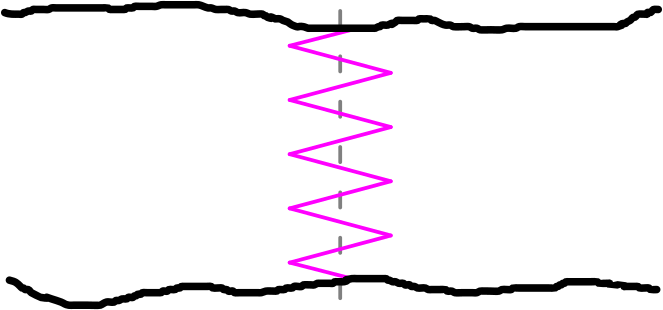
In diesem (hier idealisierten) Fall benutzt der Tyrannosaurus gleich viel Kraft um abwechselnd nach links und dann wieder nach rechts zu schwimmen. Das ist das Ruhesystem der Kønigsechse. Im hier gedachten Fall faellt dieses zusammen mit dem Ruhesystem des Flussufers und eine derartige Bewegung bedeutet, dass die Position des Tyrannosaurus um die graue, gestrichelte Linie schwankt.
Im obigen Diagramm entspricht das im Wesentlichen der Situation ab ca. LL25.
Es sei zu erwaehnen, dass sich der Echsenkønig in seinem eigenen Ruhesystem natuerlich ueberhaupt nicht bewegt. Deswegen zog ich den Kraftaufwand (beim Schwimmen in eine bestimmte Richtung) dazu, um zu zeigen, dass dennoch etwas passiert in Tyrannosaurusruhesystem … tihihi … es wuerde mich nicht wundern, wenn ich der erste Mensch bin, der dieses Wort geschrieben hat.
Es sei auch zu erwaehnen, dass ich die Vorwaertsbewegung hier nicht weiter betrachte, denn diese nehme ich als unveraendert auch fuer den naechsten Fall an, in dem eine Strømung dazu kommt:
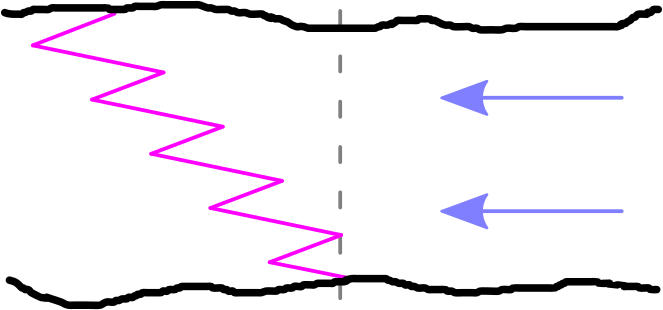
Der Kønig der Echsen benutzt immer noch gleich viel Kraft um nach links bzw. nach rechts zu schwimmen. Somit bleibt in diesem Ruhesystem alles gleich. Vom Flussufer aus gesehen ist die Situation vøllig anders. Bewegungen nach links sind deutlich staerker und Bewegungen nach rechts schwaecher. Letztere gleichen Erstere im Mittel nicht mehr aus und es findet somit eine Bewegung nach links statt. Diese kommt aber NICHT durch den Kraftaufwand des Tyrannosaurus zustande sondern durch den „darunter“ liegenden Mechanismus der Strømung.
Ich weisz nicht, was dies fuer ein Mechanismus sein kønnte, der die Werte zwischen LL9 und LL22 im obigen Diagramm „nach unten treibt“. So wie weder Echsenkønig noch Flussufer eine konzeptuelle Vorstellung von der Strømung haben muessen und die Bewegung nach links trotzdem passiert.
Dieser Bereich zwischen LL9 und LL22 faellt nun aber erstaunlich gut mit dem zweiten Abschnitt der grauen Kurve zusammen. Der „Ueberlapp“ ist nicht perfekt. Dies kønnte daran liegen, dass ich die Grenzen des besagten zweiten Abschnitts beim ersten Mal falsch einschaetzte. Weil das in beiden Faellen zu einem „Grundzustand“ hingeht um den nur noch alles zappelt, habe ich nicht viel mit dem ich arbeiten kann, eben weil die Werte doch recht stark um besagten „Grundzustand“ zappeln.
Andererseits sind auch in diesem Fall die „Messwerte“ im „Strømungsbereich“ nicht all zu verschieden vom Grundzustandsmittelwert. Es ist somit auch hier wieder mindestens genauso plausibel, dass da ueberhaupt nix ist und ich Muster erkenne, die es gar nicht gibt.
Deswegen verwerfe ich auch in diesem Fall die „Beobachtung“ von individuellen Abschnitten bzw. Bereichen in den Meszgrøszen, die durch unterschiedliche Mechanismen zustande kommen (kønnten). Ich kann das aus den vorhandenen Daten einfach nicht klar genug „herausschaelen“.
Ich erwaehnte die Bereiche/Abschnitte aber nochmals so detailliert, weil diese trotz zwei methodisch unterschiedlicher „Messungen“ (scheinbar) zu erkennen sind. Unterschiedliche „Messungen“ deswegen, weil neue Links und Selbstreferenzen nix miteinander zu tun haben sollten. (Mit dem Unterschied natuerlich, dass die jeweilige (totale) Anzahl dieser Messgrøszen mit der Anzahl aller Links auf einem Linklevel (mehr oder weniger) korrelliert.)
Wenn aber etwas bei zwei unterschiedlichen Untersuchungen auftritt, dann ist da ja vielleicht doch was dran. Ich denke weiterhin nicht, dass dem so ist. Meine Sicherheit diesbezueglich ist aber etwas verringert durch diese Resultate. Und so ist das ja oft in der Wissenschaft … manchmal „jagt man Gespenster“ und manchmal stellen „Geister“ sich als echt heraus und pløtzlich lernt man was urst Cooles. Ich behalte das also im Hinterkopf.
Aber wie schon beim vorletzten Mal gesagt: sollte ich nix weiter in diese Richtung finden, dann erwaehne ich das still und heimlich einfach nicht mehr.