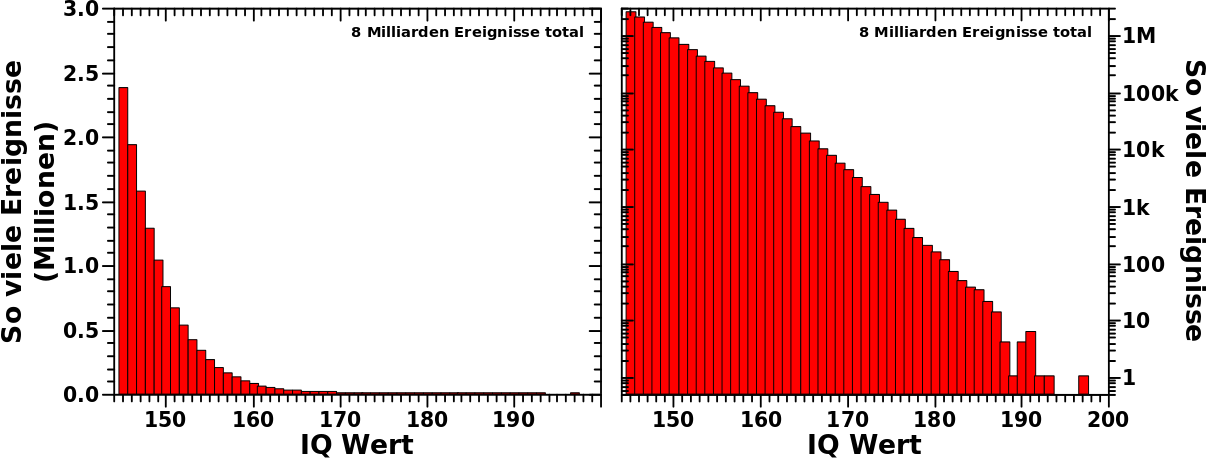
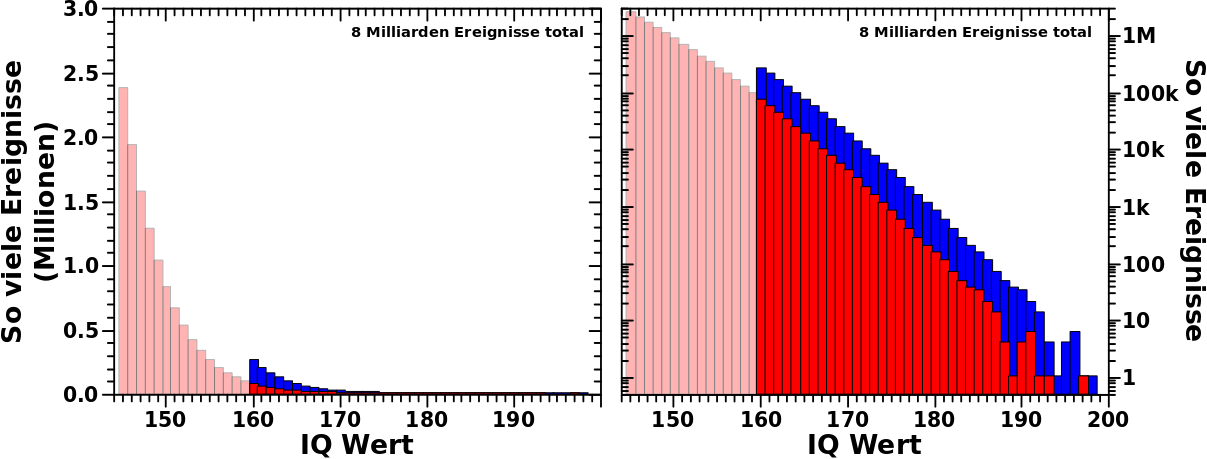
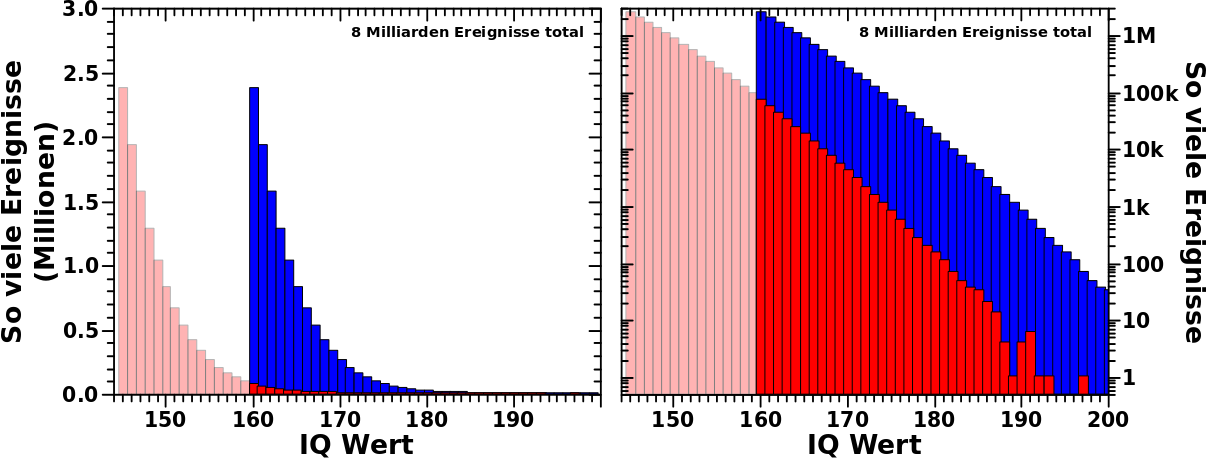
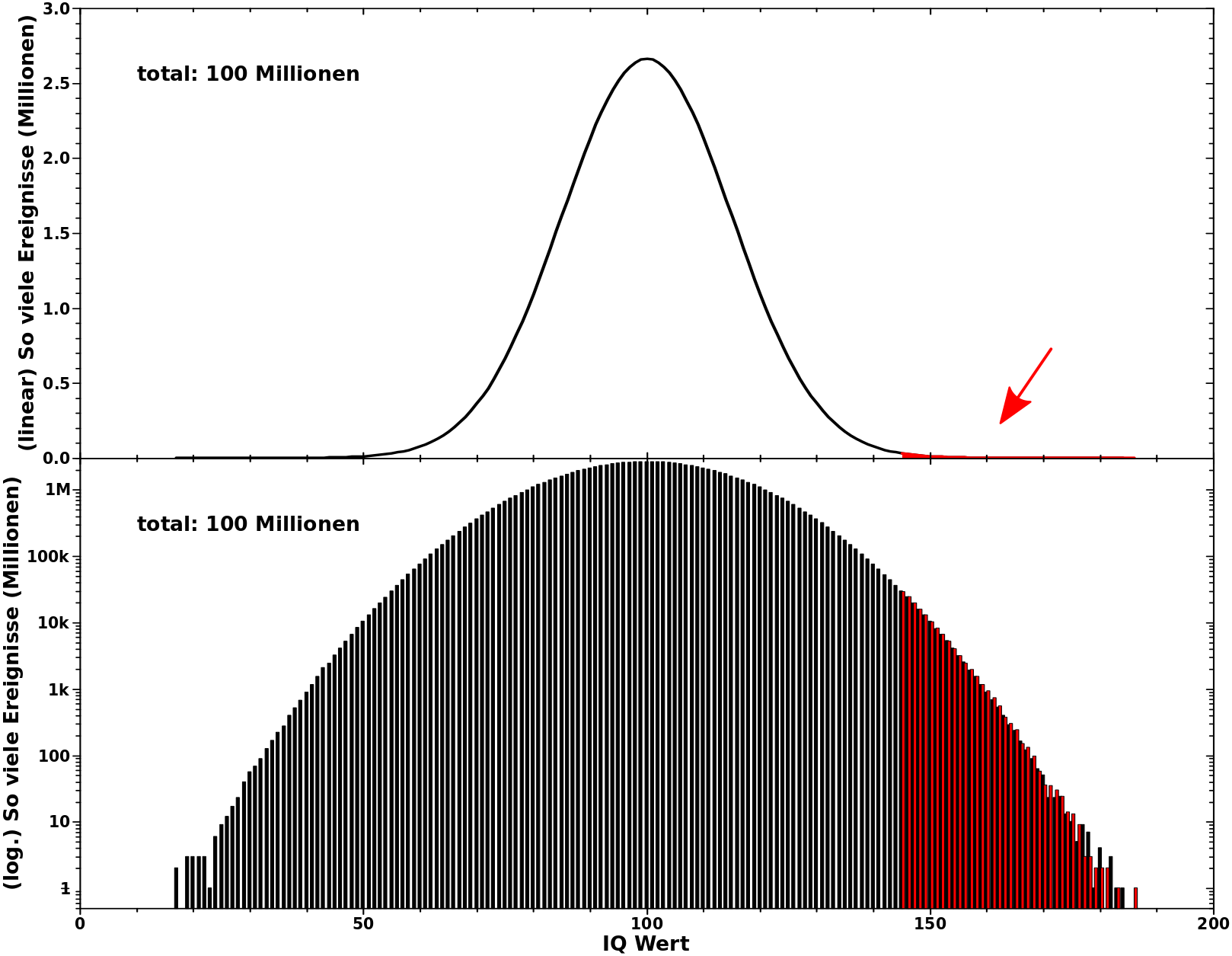
Es ist ja bekannt, dass die Intelligenz normalverteilt ist. Der Mittelwert liegt bei 100 und die Standardabweichung betraegt 15 Punkte.
Ach so, bevor ich fortfahre: wie (fast) immer laeszt die dtsch. Wikipedia sehr zu wuenschen uebrig. Deswegen ist so ziemlich alles was ich hier bespreche mehr oder weniger dem entsprechenden englischen Wikipediaartikel entnommen.
Bevor ich beim naechsten Mal dann endlich das bespreche, was ich eigentlich besprechen wollte, møchte ich hier ein paar wichtige Dinge anreiszen. Fuer eine volle Diskussion bin ich nicht qualifiziert.
Mir ist sehr bewusst, dass der IQ auf individuellem Niveau ein eher grobes „Messinstrument“ ist. Dennoch zeigt es gar nicht mal all zu schlecht in die richtige Richtung. Denn wenn man ehrlich ist, so erwartet man nicht, dass jemand mit einem IQ von 85 Professor fuer theoretische Physik wird, selbst wenn bei einem anderen Test ein IQ von 96 heraus kommt. Aber so Aussagen wie „Wenn das Baby gestillt wird, dann erhøht das den IQ im Schnitt um drei Punkte“ sind albern und groszer Quatsch auf individuellem (!) Niveau.
Eine andere Sache ist, dass es verschiedene Intelligenztests gibt. Das macht aber im Grunde nix, denn das Ergebnis jedes Intelligenztests, die Verteilung der (testabhaengigen) IQ-Werte, wird auf die oben erwaehnte Normalverteilung projiziert.
In der Praxis hat man also bspw. mehrere Fragen mit mehreren Antworten (von denen auch mehrere richtig sein kønnen). Jede richtige Antwort gibt einen Pluspunkt, jede falsche Antwort gibt einen Minuspunkt. Am Ende hat man eine Verteilung bei der die geringste Gesamtpunktzahl ich sag jetzt Mal 23 Punkte und die høchste Gesamtpunktzahl 69 Punkte sind. Das hat nun aber nix mit dem ganz oben erwaehnten „Mittelwert von 100, Standardabweichung von 15“ zu tun. An der Stelle kommt es dann zu besagter Projektion auf diese Normalverteilung.
Dann ist es so, dass zumindest frueher viele IQ-Tests zu viel kulturelles (Hintergrund)Wissen voraussetzten. Als (schlechtes) Beispiel kønnte ich mich selbst nehmen. Mein Vokabular englischer Vokabeln ist nicht grosz genug, um bei Wortassoziationsaufgaben gut abzuschneiden. Ich muesste da dann natuerlich dtsch. Wortassoziationsaufgaben vorgelegt bekommen, aber dies verdeutlicht den kulturellen Aspekt von Fragen eigtl. ganz gut denke ich.
Und letztlich ist da auch noch der Fakt, dass es verschiedene „Intelligenzen“ gibt. Man denke bspw. an sprachliche, mathematische oder soziale Intelligenz. Wenn man das genauer untersucht, gibt es Menschen die wirklich gut sind bei der einen Sache, aber normalverteilt bei den anderen. Das ist aber laenglich durchzufuehren und wuerde (so weit ich das verstanden habe) letztlich dennoch zu einer erhøhten Gesamtpunktzahl fuehren.
Auf gesellschaftlichem Niveau hingegen ist die IQ-Verteilung, also NICHT nur der Durchschnittswert (!), durchaus von Interesse. Und genau deswegen ist das Thema in der Wissenschaft leider „entzuendet“.
Aufgrund verschiedenster historischer Ursachen ist es naemlich so, dass bestimmte Gruppierungen von Menschen in Intelligenztests im Durchschnitt weniger Punkte erhalten, als die „weisze Ober- und Mittelschicht“.
DAS ist meiner Meinung nach ganz stark den schlechten Lebensumstaenden geschuldet. Zum Beispiel ist seit langem bekannt … *hust*, […]
[…] that there is a straight-line relationship between the amount of lead in the body and careful measures of disturbed behavior and learning problems.
Wer lebt nun in bleiverseuchten Umgebungen, in Windrichtung der Fabrikschornsteine? Richtig! NICHT die weisze Ober- und Mittelklasse. Natuerlich ist das nicht nur Blei sondern es gibt da ganz viele andere Sachen mit aehnlichen (oft noch nicht mal erforschten) Effekten. Und das beschraenkt sich nicht nur auf Chemikalien, sondern auch auf soziologische Aspekte wie schlechte Schulen oder dass man als Kind arbeiten gehen muss (zu Letzterem siehe auch (mal wieder) viele Seiten in Marx‘ Das Kapital).
Diese Luecke in den IQ-Werten, oder richtiger: dieser Unterschied in der Verteilung der IQ-Werte verschiedener gesellschaftlicher Gruppierungen, wird nun (natuerlich) von menschenverachtenden Spinnern genommen um zu sagen, dass bspw. nicht-weisze oder arme Menschen genetisch minderwertig seien.
Deswegen ist entsprechende grosz angelegte Forschung diesbezueglich verpønt und findet nicht statt. Anstatt das zu machen um die Ursachen fuer den IQ-Abstand besser zu verstehen und zu beseitigen.
Einschub: Forschung die letzten Jahrzehnte zeigt, dass besagter IQ-Abstand zwischen farbigen und weiszen Gemeinschaften in den USA stetig geringer wird. Das ist natuerlich auf die allgemein besseren Lebensumstaende (verglichen mit den 40’er, 50’er, 60’er Jahren) zurueck zu fuehren und entbløszt die menschenverachtenden Spinner als genau solche.
Achtung: das heiszt nicht, dass Intelligenz NICHT von den Genen abhaengt. Dem ist mit ziemlicher Sicherheit so. Hier Ich schrieb bzgl. der Ashkenazijuden etwas dazu und um uns herum sehen wir ja selber, dass schlaue Menschen oft auch schlaue Kinder haben. Aber das ist natuerlich nicht Alles, denn selbst wenn jemand keine schlauen Eltern hat, kann ein Individuum in der groszen Genverteilungslotterie gut abgeschnitten haben. Und Letztere sind ja u.A. worauf ich hinaus will mit dieser kleinen Serie.
Soweit zu den Sachen die mindestens kurz angesprochen werden muessen, wann immer man IQ-Verteilungen diskutieren will.
Wie ich nunmal bin, versuchte ich also Rohdaten von grosz angelegten Intelligenzverteilungsuntersuchungen zu finden. Ich dachte mir, dass es die doch geben muss. So sehr wie die linke Seite des politischen Spektrums eben solche verteufelt … bzw. so sehr wie die rechte Seite des politischen Spektrums versucht ihren menchenverachtenden Dreck damit zu rechtfertigen.
Aber da ist nuescht! Oder fast nix.
Es gibt alte Buecher, aus der Zeit als die ganze Forschung darum am Entstehen begriffen war. Und da findet man dann auch mal eine IQ-Verteilungen (Bild #2). Aber die Daten darin lassen sehr zu wuenschen uebrig. Zum Ersten, weil es nicht die Rohdaten an sich sind (die Kultur Messdaten zu teilen ist ja selbst heute nicht weit verbreitet … *seufz*). Zum Zweiten, weil alle oben erwaehnten Unzulaenglichkeiten des kulturellen Hintergrundwissens noch nicht bekannt waren und man versuchte die intrinsischen Fehler zu vermeiden. Und zum Dritten weil die Untersuchungen eher limitiert waren (es ist halt nur eine Studie pro Buch). Deswegen vermied ich solche alten Buecher.
Aus neuerer Zeit gibt es das OpenPsychometrics Projekt. Der Test und die Daten sind neuerer Natur und die Rohdaten sind verfuegbar und beinhalten mittlerweile ueber 3000 Teilnehmer (die Statistik waere also ganz gut). Aber auf der Testseite steht zu Recht:
WARNING: Every on-line IQ test is bad
… … … *seufz*.
Dann fand ich heraus, dass U.S. Bureau of Labor Statistics Querschnitssuntersuchungen macht. Und eine davon ist die National Longitudinal Survey Youth, 1979, mit ueber zehntausend Teilnehmern aus allen gesellschaftlichen Bereichen. Das ist zwar schon ein bisschen her, aber nicht all zu lange … und die Rohdaten sind verfuegbar … Hurra.
Es dauerte ein Weile, bis ich verstanden hatte, wie die Daten aufgebaut sind und wie deren Nutzergrenzschnitt zu bedienen ist … aber so ist das ja immer und was mache ich nicht alles, um an Rohdaten zu kommen.
Es stellte sich dann leider heraus, dass weniger als 1000 Leute IQ-Tests gemacht hatten … im Grunde genommen war das also auch nur eine Untersuchung … *seufz*.
Bei der (gleichen) Querschnitssuntersuchung aber im Jahre 1996 gab es dann gar keine IQ-Tests mehr … *doppelseufz* … das waere doch mal voll interessant gewesen.
Meine Suche fuehrte mich zu immer obskureren (wenn auch durchaus interessanten) Quellen (der Direklink funktioniert ohne, dass man da ein Profil haben muss). Aber auch dort wird nur auf ganz wenige, ziemlich alte und limitierte Untersuchungen (natuerlich ohne Rohdaten) verwiesen.
Das scheint also ein systemisches Problem zu sein, ich denke verursacht durch oben angesprochenes Tabu derartiger Forschung. Nach Stunden der erfolglosen Recherche sah ich ein, dass ich so nicht weiterkomme, um meine urspruengliche Aufgabenstellung zu bearbeiten.
Zum Glueck ist das nicht streng nøtig, da ja die Ergebnissse von Intelligenztests ohnehin auf eine klar definierte Verteilung projiziert werden. Das worauf ich eigentlich hinaus will, kann ich also auch mittels einer Simulation veranschaulichen. Aber dazu mehr beim naechsten Mal.