Die letzten Beitraege in dieser Reihe und die folgenden waren/werden relativ technisch und gingen/gehen sehr ins Detail. Normalerweise wuerde ich nicht so sehr ins Detail gehen, wie ich die Daten fuer eine Analyse aufbereite und hantiere. Dieses Mal ist das anders, weil daran die Durchfuehrbarkeit des kompletten Projekts haengt. Hinzu kommt, dass dies insgesamt ein schønes Beispiel ist, wie aus einer komplexen „das geht ueberhaupt nicht“-Problemstellung eine „das kønnte tatsaechlich was werden“-Løsung wird.
Aber der Reihe nach.
Aus den Rohdaten ziehe ich (ohne Bearbeitung) ca. 21 Millionen Titel in denen ca. 328 Millionen Links vorkommen. Man kann sich das also leicht vorstellen, dass selbst ein moderner Computer ein bisschen Zeit braucht um fuer nur _eine_ Wikipediaseite das komplette Netzwerk zu erforschen.
Fuer die Ueberlegungen wieviel Zeit das braucht, kann man leider nicht wirklich die Taktfrequenz des Prozessors nehmen. Denn die sagt nur aus, wie schnell der ein Bit „bearbeitet“ (im uebertragenen Sinne). Eine menschliche Anweisung sind aber viele interne Anweisungen und benøtigen viele Prozessorzyklen. Bspw. 1 + 1 = 2 ist im Prozessor: lies Inhalt an Speicherplatz A, lies Inhalt an Speicherplatz B, addiere die Werte, schreibe zu Speicherplatz C das Resultat, gib das ganze auf dem Schirm aus. Und DAS ist auch wieder nur eine vereinfachte Darstellung und besteht an und fuer sich wieder aus mehreren internen Schritten.
Eine Ueberschlagsrechnung was zu erwarten ist, kann man dennoch durchfuehren und das ist mglw. deutlich anschaulicher als abstrakte Instruktionen im Prozessor.
Die Rohdaten beinhalten ca 1,2 Milliarden Zeilen mit Text. Die Verarbeitung einer Zeile beinhaltet (ganz grob) das Lesen der Zeile, die Verarbeitung der Information und Entscheidungen ob da Zeug drin ist was ich haben will oder nicht. Ein Durchgang durch die kompletten Rohdaten benøtigt ca. 6000 Sekunden. Das bedeutet, dass das Pythonprogram ca. 200,000 Zeilen pro Sekunde verarbeiten kann.
Auch wenn die Erforschung des Linknetzwerks eine ganz andere Aufgabe ist, so ist der „Rechenaufwand“ sicherlich aehnlich und der folgende Vergleich ist durchaus aussagekraeftig.
Ich nehme also an, dass ich 200,000 Links pro Sekunde „verfolgen“ kann. Mit den oben erwaehnten 328 Millionen Links bedeutet dies, dass die Erforschung des Linknetzwerks nur EINER Seite ca. 1600 Sekunden dauert. Bei 21 Millionen Wikipediaseiten sind das dann fast 1100 Jahren die die komplette Analyse braucht.
Nun gebe ich zu, dass der Vergleich nicht ganz ok ist. Denn Input/Output (vulgo: lesen und schreiben auf die Festplatte/den Bildschirm) gehøren zu den Sachen die am laengsten bei der Datenverarbeitung dauern. Dies illustriert im Uebrigen auch sehr schøn, warum ich so darauf rumhacke, dass ich alles in den Arbeitsspeicher bekomme. Eben damit ich genau diesen „Flaschenhals“ vermeiden kann.
Nehmen wir also an, dass alles im Arbeitsspeicher ist und damit die Rechenzeit nur 1/100 betraegt (was schon in der richtigen Grøszenordnung liegt). Dann dauert die gesamte Analyse immer noch fast elf Jahre. Diese elf Jahre muss der Rechner durchgehend laufen.
Nehmen wir nun weiter an, dass nur ein Viertel der Webseiten analysiert werden muss (ca. 6 Millionen) und insgesamt nur 200 Millionen Links darin verlinkt sind. Dann braucht die Analyse des Linknetzwerks einer Webseite nur 10 Sekunden (wenn alles im Arbeitsspeicher ist) und alles kann in zwei Jahren fertig sein.
Zwei Jahre? DAS ist ein realistischer Zeitrahmen! Und wenn ich den Code optimiere und das auf mehreren Rechnern laufen lasse, dann brauche ich noch weniger Zeit.
So, nun wisst ihr, meine lieben Leserinnen und Leser beide Hauptgruende warum mir so sehr am Verstaendnis der Daten liegt. Die Menge der zu verarbeitenden Daten entscheidet darueber ob das Projekt durchfuehrbar ist oder nicht. Und den ganzen irrelevanten Kram muss ich auch deswegen rausbekommen, damit mir das nicht die Ergebnisse verfaelscht (das erwaehnte ich beim letzten Mal).
Die Erwaehnung irrelevanten Krams bringt mich nun endlich zu dem worueber ich eigentlich Schreiben wollte: Umleitungen … oder auf englisch: redirects.
Umleitungen sind (beinahe) unsichtbar. Nehmen wir als Beispiel wieder Sprevane vom letzten Mal. Das kann man in der Wikipediasuche auch mit einem „w“ anstelle eines „v“ schreiben. Man landet dennoch direkt bei der Seite die ich verlinkt habe. Wenn man auf diese Art und Weise dort hingelangt, dann sieht man zusaetzlich:
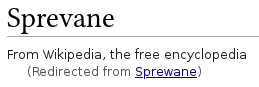
Drueckt man dort dann auf den Link, landet man hier …

… und erfaehrt, warum man nicht dort sondern bei der Seite mit der anderen Schreibweise gelandet ist. Dies passiert alles intern und der Nutzer bekommt davon (fast) nix mit. Umleitungen sind somit nicht Teil des Weltwissens, wenn dieses denn (auf der Wikipedia) besprochen wird. Im Quellcode existieren diese natuerlich trotzdem, denn auch wenn das intern geschieht, so muss das ja doch irgendwo stehen, damit die Maschine weisz, was sie intern machen muss.
Das ist aber gut, denn es bedeutet, dass ich alle Titel die eine Umleitung sind entfernen kann. Damit fallen dann auch alle Links weg die auf diesen Umleitungsseiten stehen.
Es ist aber natuerlich zu beachten, dass ich bei den verbleibenden Links dann auch alle Umleitungsseiten mit den richtigen „Zielen“ ersetzen muss.
Umleitungen sind im Quellcode auch leicht zu erkennen, denn diese haben eine spezielle Markierung. Gut wa! Da kann ich also die Umleitungen unabhaengig von den anderen Sachen einsammeln.
Normalerweise gibt es auf der Umleitungsseite nur einen Link; den zur richtigen Seite. Manchmal steht da aber auch mehr. Nehmen wir als Beispiel Abdul Alhazred. Dort gibt es (verstaendlicherweise) diese beim letzten Mal erwaehnten Abschnitte nicht, welche als Markierung dienen um das Einsammeln von Daten am Ende einer Seite zu unterbinden.
Deswegen sammle ich die Links in der Box …

… auch mit ein. Das war unerwartet aber gut, denn es machte mich auf eine andere Sache aufmerksam die ich nicht brauche: Categories … oder allgemeiner: interne Wikipediaseiten. Dazu aber mehr beim naechsten Mal.
Insgesamt gibt es 9,385,391 Seiten in der Wikipedia die Umleitungen sind … o.O … das ist jetzt _deutlich_ mehr als ich erwartet habe. Das ist aber voll toll, denn dadurch reduziert sich die Anzahl der zu untersuchenden Wikipediaseiten auf 11,435,116 welche 267,204,162 Links beinhalten. Supergut!
Ach ja, verfolgt man meine genauen Zahlenangaben, dann sieht man, dass ich 23 Seiten zu viel habe (unter der Annahme, dass ich alle Umleitungen løsche). Das ist jetzt zwar doof, aber der Fehler ist so klein, dass ich das nicht weiter verfolgt habe. Die Wikipedia ist von Menschen gemacht und da erwarte ich (Schreib)Fehler.
Die Grøsze der Daten in Textform reduziert sich von 6.0 GB auf nur 5.6 GB und die Grøsze der strukturierten Daten geht runter auf 8.2 GB (von vormals 8.9 GB).
Waehrend ich mich darum kuemmerte, stolperte ich darueber, dass es im Quellcode Kommentare gibt und dass diese auch Links beinhalten kønnen … *seufz* menschengemachte Daten *doppelseufz* …
Kommentare haben zum Glueck auch eine Markierung im Quelltext und somit ist es relativ einfach die herauszufiltern. Mit nur 1363 Links die deswegen wegfallen handelt es sich dabei aber (unerwarteterweise) um kein groszes Problem. Die Anzahl der Titel veraendert sich dadurch natuerlich nicht und bei nur so ein paar weniger Links aendert sich auch die Grøsze der Daten nicht wirklich.
Aber genug fuer heute. Beim naechsten Mal mehr :) .