In einem komplizierten Verhaeltniss mit der ungenutzten Arbeitskraft vom letzte Mal steht die Rate der Personen die am Erwerbsleben teilnehmen. Kurz gesagt ist das der Quotient aus allen Menschen die Arbeit haben oder (inklusives oder) arbeiten wollen und allen Menschen im „arbeitsfaehigen Alter“.
Der Nenner ist etwas salopp formuliert und ist eigtl. die Grøsze der jeweiligen Alterskohorte. Der Nenner enthaelt also ALLE Leute. Im Zaehler hingegen sind Menschen NICHT mitgezaehlt wenn diese nicht arbeiten wollen und dadurch aus der Arbeitslosenstatistik raus fallen … ich diskutierte das etwas detaillierter beim letzten Mal.
Die (Rate der) Beteiligung am Erwerbsleben sieht fuer Japan nun so aus:
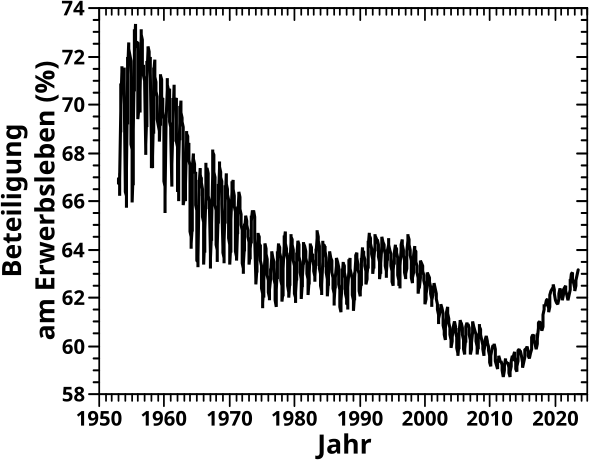
OI … das ist ja vøllig anders als die Arbeitslosenrate vom letzten Mal. Aber wenn man das der Reihe nach durch geht und die Geschichte mit in Betracht zieht ist die Kurvenform erklaerbar.
Zunaechst denke ich, ist es plausibel davon auszugehen, dass im kriegszerstørten Japan viele Frauen gar keine Wahl hatten und arbeiten mussten (das war ja bspw. in Dtschl. nicht anders). Deswegen hat die Kurve am Anfang hohe Werte.
Mit dem wirtschaftlichen Aufschwung wurden aber viele Frauen aus dem Arbeitsleben gedraengt. Und von allem was ich weisz (was zugegebenermaszen nicht viel ist und nur halb (oder weniger) richtig sein kann) erwartete die japanische Gesellschaft das von den Frauen. Wobei natuerlich auch zu bedenken ist, dass es gesamtgesellschaftlich nicht nur schlecht ist wenn so viel Reichtum ueber fast alle Einwohner verteilt ist, sodass nur die Haelfte der Leute arbeiten muss und das Geld trotzdem reicht. Leider bedeutet das in der Realitaet immer, dass die Maenner arbeiten gehen und die Frauen zu Hause bleiben. Wenn ich auf Ersteres hinweise, dann bedeutet das natuerlich NICHT, dass ich die wirtschaftliche Abhaengigkeit der Frauen von den Maennern befuerworte; GANZ IM GEGENTEIL! … Aber ich schweife ab, das Thema ist deutlich komplizierter und darueber will ich gerade nicht schreiben.
Der Prozess den ich eben beschrieb fuehrt aber NICHT dazu, dass die Frauen dann arbeitslos sind. Das zeigt ein Blick auf das Diagramm vom letzten Mal: die Arbeitslosenrate bleibt niedrig. Die Frauen „fallen raus“ aus den Personen im Zaehler des Quotienten (weil die japanische Gesellschaft eben erwartete, dass sie sich NICHT arbeitssuchend melden). Im Nenner sind sie aber noch mit dabei … oder anders: der Quotient wird kleiner und das ist genau das was man sieht.
Ca. Anfang der 70’er Jahre ist der beschriebene Prozess zu Ende und die Werte der Kurve unterliegen keinen wesentlichen Aenderungen bis zum Ende des 20. Jahrhunderts. … … … Wait! … What? … in der „verlorenen Dekade“ haette ich erwartet, dass mehr Leute gezwungen sind sich Arbeit zu suchen (auch wenn sie die nicht unbedingt finden), der Nenner somit grøszer wird und die Kurve wieder ansteigt. Aber dem ist anscheinend nicht so … vielmehr setzt sich auch hier wieder ein Trend fort, der 20 Jahre vorher begann.
Was mich zurueck zum Anfang des Arguments bringt was ich oben nicht weiter verfolgte: anscheinend ging es der Gesellschaft auch in der „verlorenen Dekade“ weiterhin so gut, dass es reichte, wenn nur die Maenner arbeiten gegangen sind. … Mhmmmm … dann kann die Zeit ja gar nicht so „verloren“ gewesen sein … finde ich.
Das soll reichen fuer heute. Zum Abschluss sei nur noch schnell der Rest der Kurve erklaert.
Ab 2000 schlaegt die Demographie wieder zu: die vielen Leute aus den vorhergehenden Jahren fangen an in Rente zu gehen. Der Zaehler nimmt also ab (waehrend der Nenner weiter waechst, wenn auch langsam) und die Werte der Kurve werden kleiner. … … … Was natuerlich auch wieder gegen mehrere „verlorene DekadEN“ spricht, denn das sieht mir hier mitnichten nach „Alterarmut“ aus, die ich damit in Verbindung bringe … meiner Meinung nach.
Ab 2010 sieht man das Umgekehrte: Rentner fangen an zu sterben. Der Zaehler bleibt im Wesentlichen gleich, waehrend der Nenner abnimmt und die Kurve steigt wieder an.
Das sind aber alles lang anhaltende Trends die keiner singulaeren Erklaerung beduerfen.
Obiges ist natuerlich komplizierter (und vermutlich auch langweiliger fuer die meisten Leute) als _ein_ Grund der sich gewaltig (und zunaechst sogar plausibel) anhørt.
Jetzt habe ich geschaut _ob_ die Leute arbeiten, beim naechsten Mal schaue ich mir an wieviel Arbeit es ueberhaupt gab.