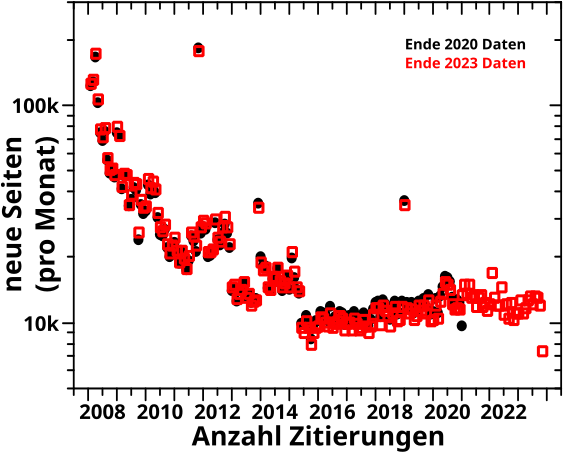
Wie beim letzten Mal versprochen gibt es diesmal Verteilungen … und das bedeutet natuerlich: 2D-Falschfarbenbilder, oder in kurz: Heatmaps.
Das ist zwar i.A. nix Neues, in diesem Zusammenhang aber schon. Deswegen erklaer ich heute alles ganz genau und benutze dafuer NUR die 2020 Daten. Die Reproduktion der Bilder folgt dann beim naechsten Mal. Ohne weitere Umschweife kann’s jetzt losgehen.
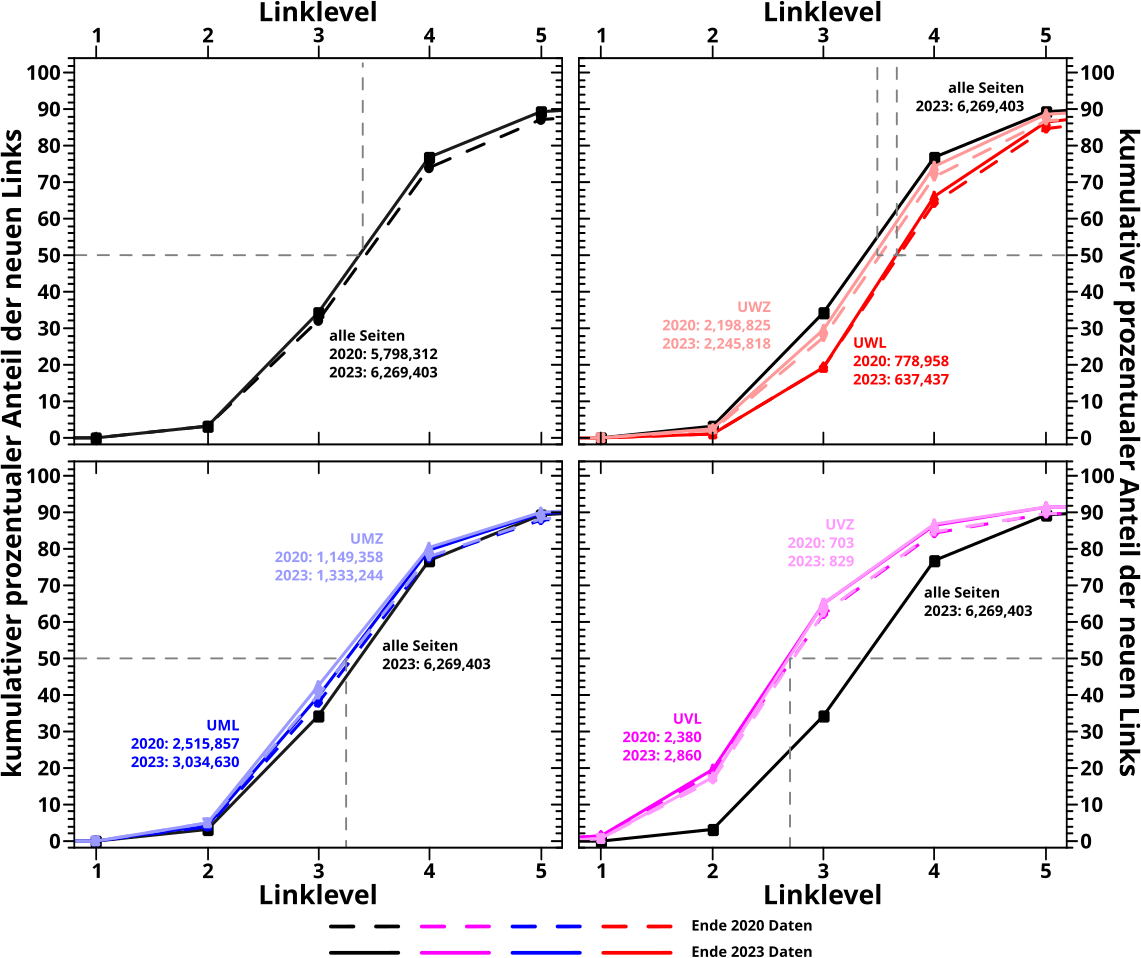
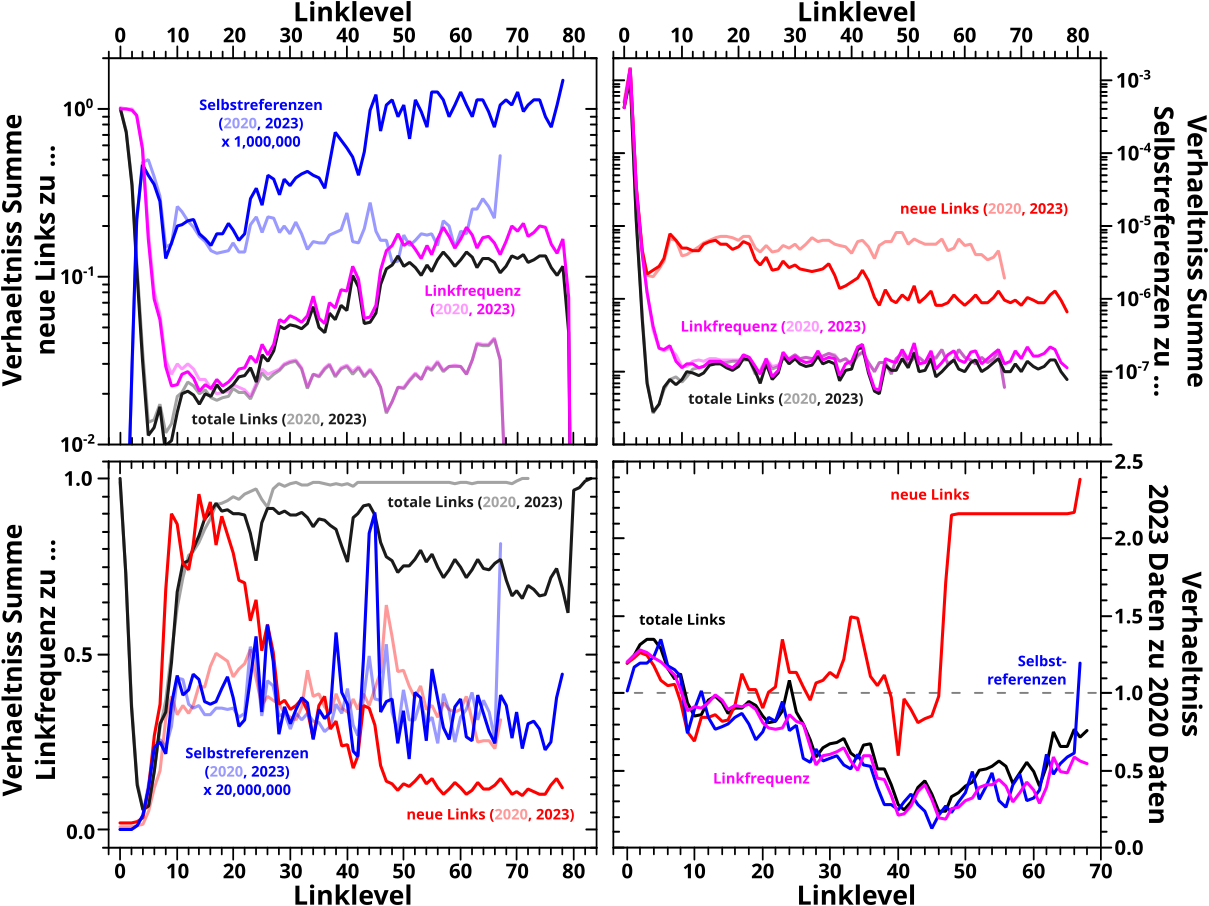
Die Durchschnitte beim letzten Mal waren zwei Summen und jeder Summe folgte eine Divisionen. Die eine Summe (und Division) war individuell fuer jede Seite und die wird beibehalten. Hierbei handelt es sich naemlich um den „kumulativen Teil“ im kumulativen, prozentualen Anteil (des neuen Links / Linkfrequenz Signals) — also das was betrachtet werden soll.
Die andere Summe (und Division) war der normale Durchschnitt ueber alle Seiten und das ist der heikle Teil.
Ein all zu simples Beispiel diesbezueglich: 9 Seiten haben auf LL0 fuenf Links, 1 Seite linkt zu allen Wikipediaseiten (nehmen wir wieder an es sind 5 Millionen). Dann sehen die ersten neun Seiten 0.0001 Prozent aller Seiten und die letzte Seite sieht 100 Prozent. Im Durchschnitt sieht jede der Seiten 10 % aller anderen Seiten … das ist „nur“ eine Grøszenordnung von der letzten Seite entfernt, aber 5 Grøszenordnungen von den ersten neun. Ich denke das veranschaulicht das Problem.
Man kønnte anstatt des Durchschnitts den Median nehmen. Der sagt oft mehr (und andere Sachen) aus, aber ist letztlich auch nur eine Zahl die nicht alles erfasst. Im Beispiel liegt der Median 6 Grøzszenordnungen von der letzten Seite entfernt; der grøszte Unterschied zwischen der Zahl die das System beschreiben soll und einem Mitglied dieses Systems wird also um einen Faktor zehn verschlimmert. Auszerdem traegt diese eine Seite sicherlich krass zur gesamten Dynamik bei und das wird durch den Median noch weniger dargestellt. Desweiteren sagt der Median was ueber „50 % der Seiten liegen unter diesem Wert“ aus … aber die 9 Seiten entsprechen 90 % der Seiten und die liegen nicht drunter sondern drauf.
Wieauchimmer, es gibt Gruende, warum ich Histogramme bevorzuge in denen die Verteilung der Grøsze von Interesse ueber alle Seiten dargestellt werden.
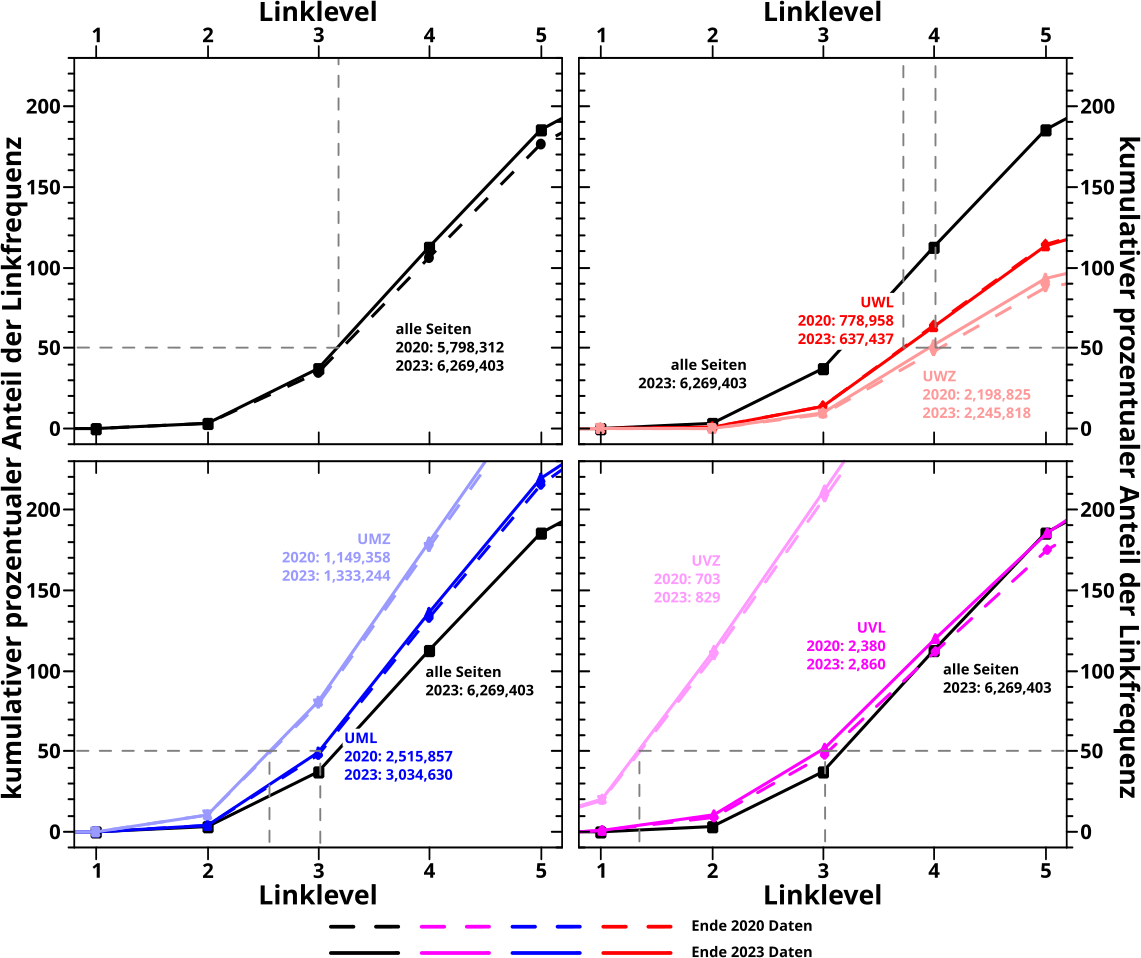
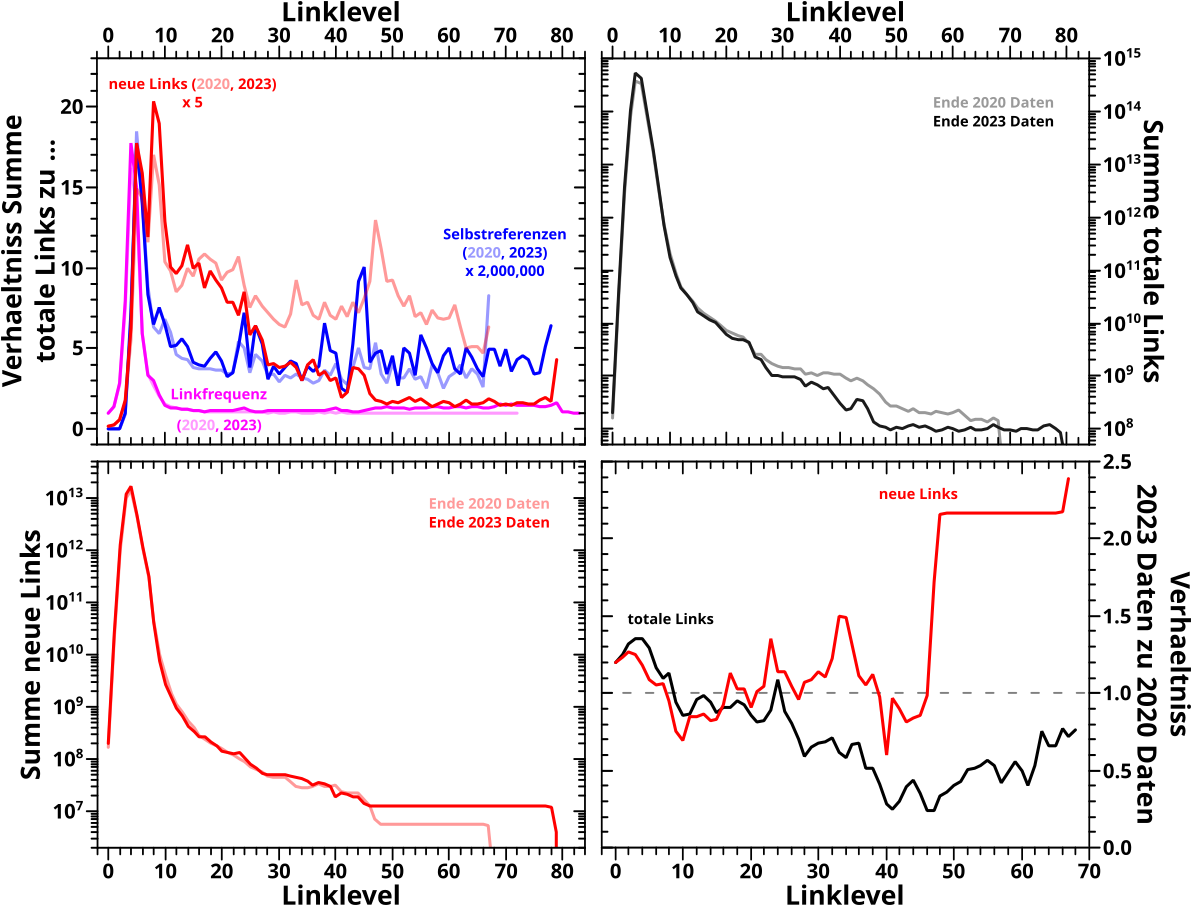
Die Grøsze von Interesse ist hier der kumulative, prozentuale Anteil. Auf einem gegebenen Linklevel rechne ich den fuer jede einzelne Seite aus und der „Zaehler“ im Histogramm geht bei den entsprechenden Werten pro Seite um eins nach oben. Jedes Linklevel hat ein eigenes Histogramm und ich stelle alle zusammen in einer Heatmap dar. Wobei ich hier nur LL0 bis LL10 darstelle (weil nur da wirklich was passiert) und auch nur bis zu einem kumulativen, prozentualen Anteil bis 100 Prozent. Letzteres ist nur bei der Linkfrequenz von Interesse und es ist nicht ganz uninteressant was bei høheren Linkleveln und jenseits von 100 % passiert. Das muesste eigentlich genauer untersucht und erklaert werden um zu verstehen wo das herkommt … aber wir naehern uns endlich dem Ende dieses Groszprojekts und da mach ich das nicht mehr … in kurz ist’s eh alles nur ein Effekt der Mehrfachzaehlungen im Linkfrequenzsignal.
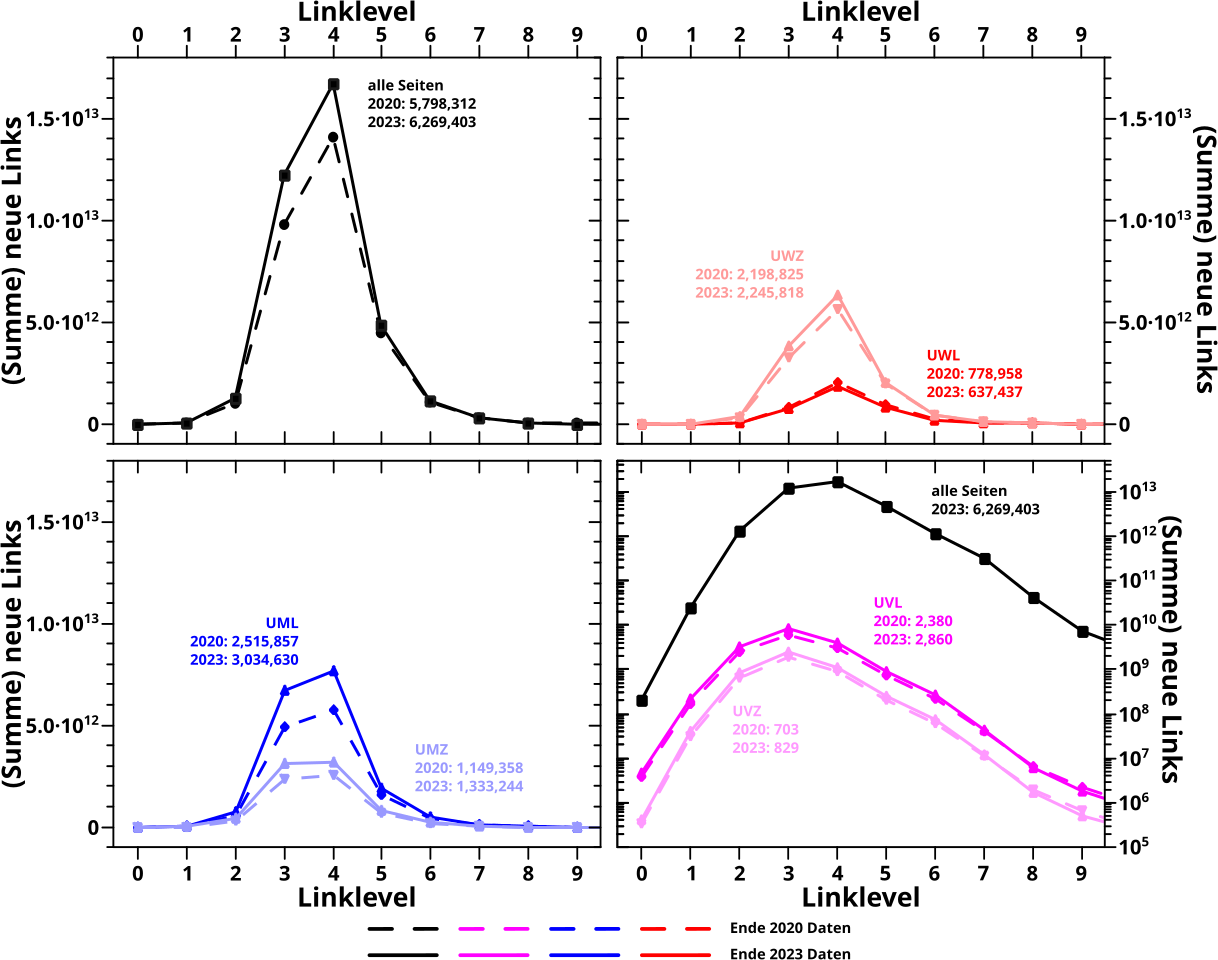
Hier nun die entsprechende Heatmap fuer die neuen Links:
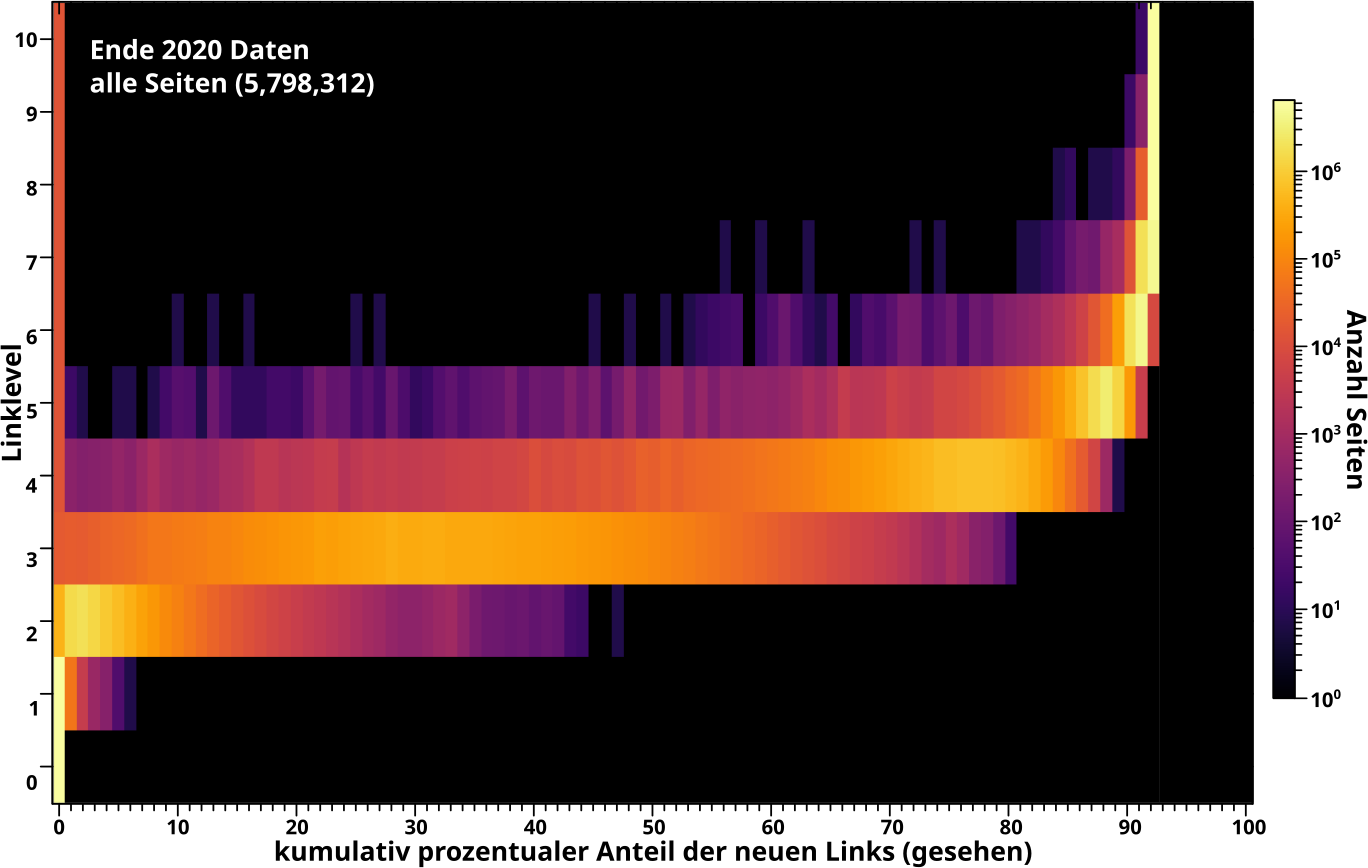
Man beachte, dass das Linklevel ausnahmsweise auf der Abzsisse abgetragen ist; das war sinnvoller. Auszerdem ist die Farbskala (wieder) logarithmisch, damit man nicht nur in den Extremen was sieht.
Wenn man das mit den Ergebnissen vom letzten Mal vergleichen will, muss man die „Schwerpunkte“ der Streifen betrachten. Auf LL3 „verschmiert“ sich alles relativ breit zwischen null und ca. 80 Prozent. Aber besagter Schwerpunkt liegt um 30 Prozent wuerde ich sagen. Fuer LL4 dann ist die Intensitaet bei Werten unter 50 Prozent schon relativ schwach und die meisten Seiten „tuemmeln“ sich um ca. 75 Prozent … *nachschau* … was ziemlich gut mit dem Ergebnissen vom letzten Mal ueberein stimmt.
Nun fuer die nach der Anzahl der Links eingeteilten Untergruppen:
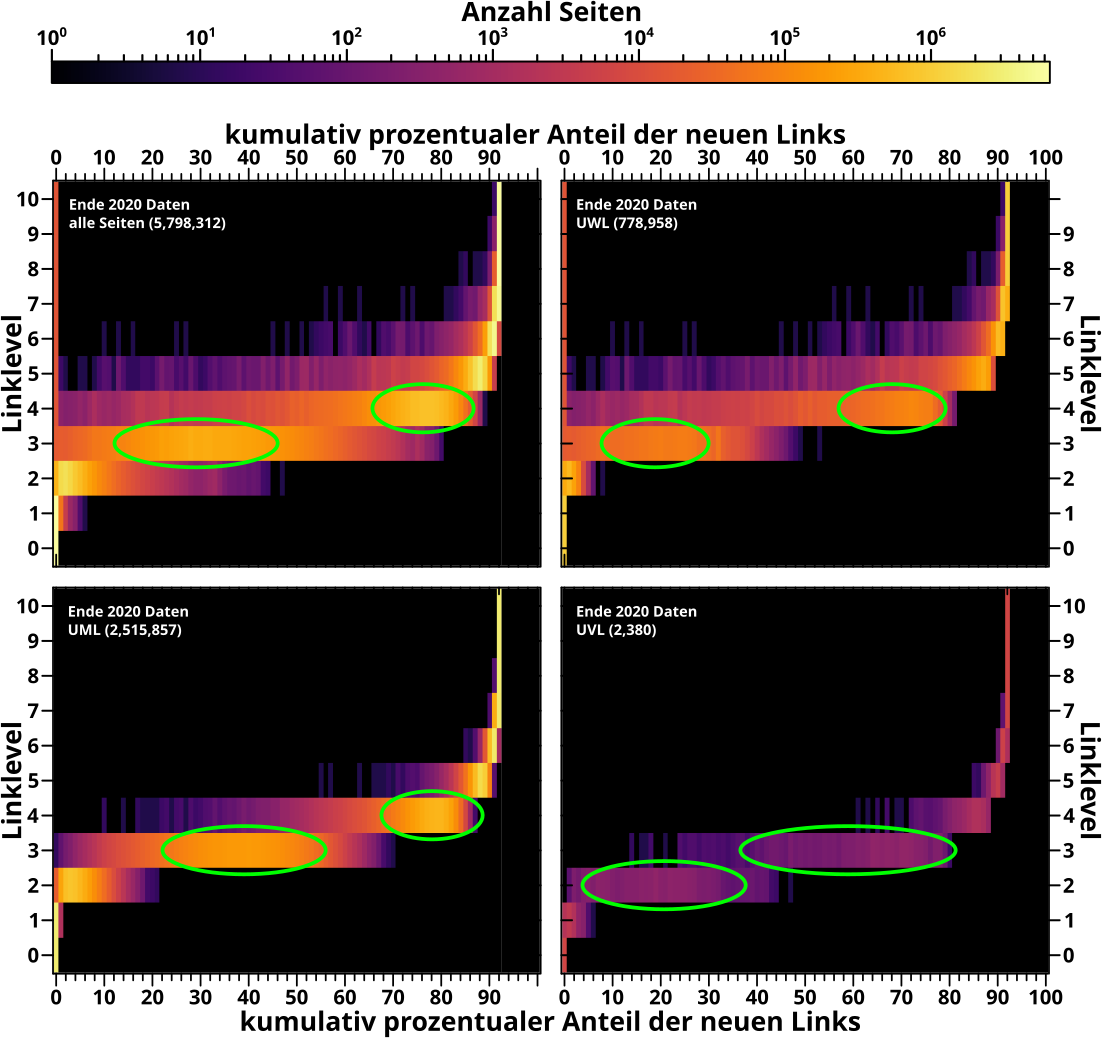
Man beachte, dass die Farbskala fuer alle Diagramme die Selbe (!) ist; deswegen ist’s so dunkel fuer die UVL, denn da gibt es insgesamt nur so wenige Seiten.
Ich habe die „Schwerpunktregionen“ markiert und wenn man das untereinander und mit den Durchschnittswerten vergleicht, dann haut das wieder alles hin. Aber der Informationsgehalt ist natuerlich viel grøszer in so ’ner Heatmap; insb. sieht man die Dynamik (der einzeilnen Untergruppen) viel besser.
Fuer die nach der Anzahl der Zitate (von anderen Seiten) eingeteilten Untergruppen sieht das so aus:
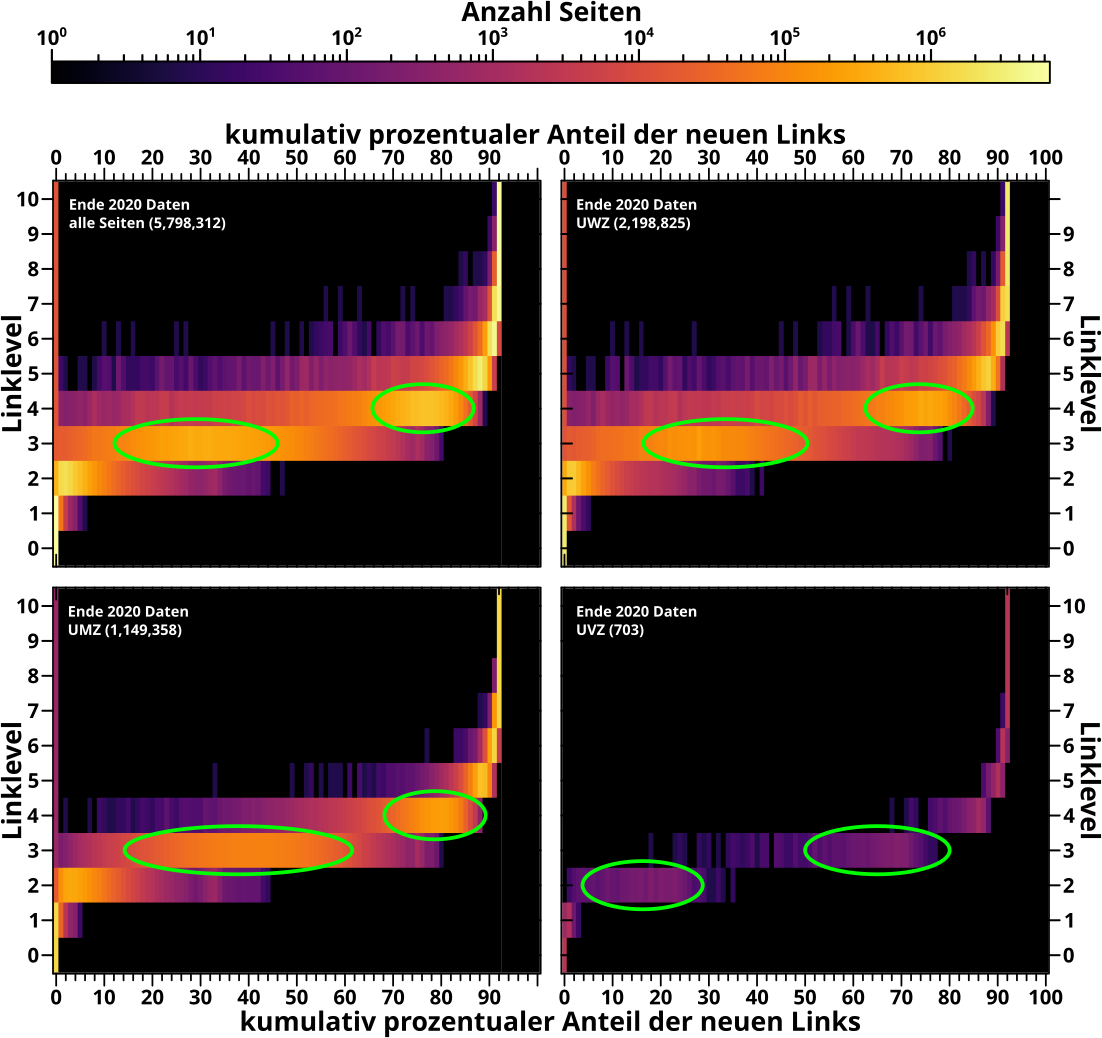
Da kann ich nur sagen: dito. Bzgl. der neuen Links ist alles relativ klar und einfach zu verstehen, weswegen ich die zuerst gezeigt habe.
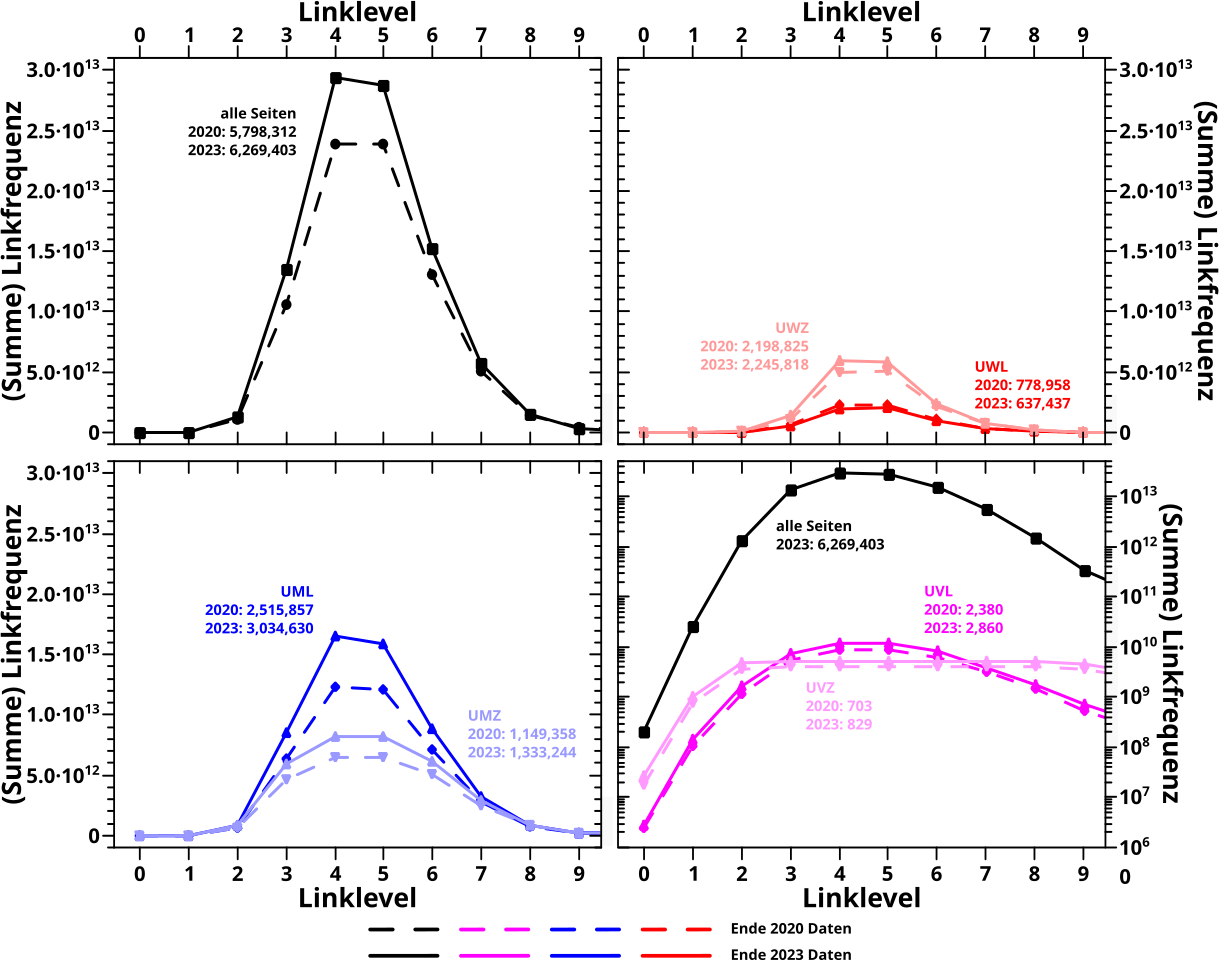
Fuer die Linkfrequenz gelten die selben Prinzipien, die Heatmaps sehen aber auf den ersten Blick deutlich anders aus (erstmal wieder nur die nach der Anzahl der Links sortierten Untergruppen), …
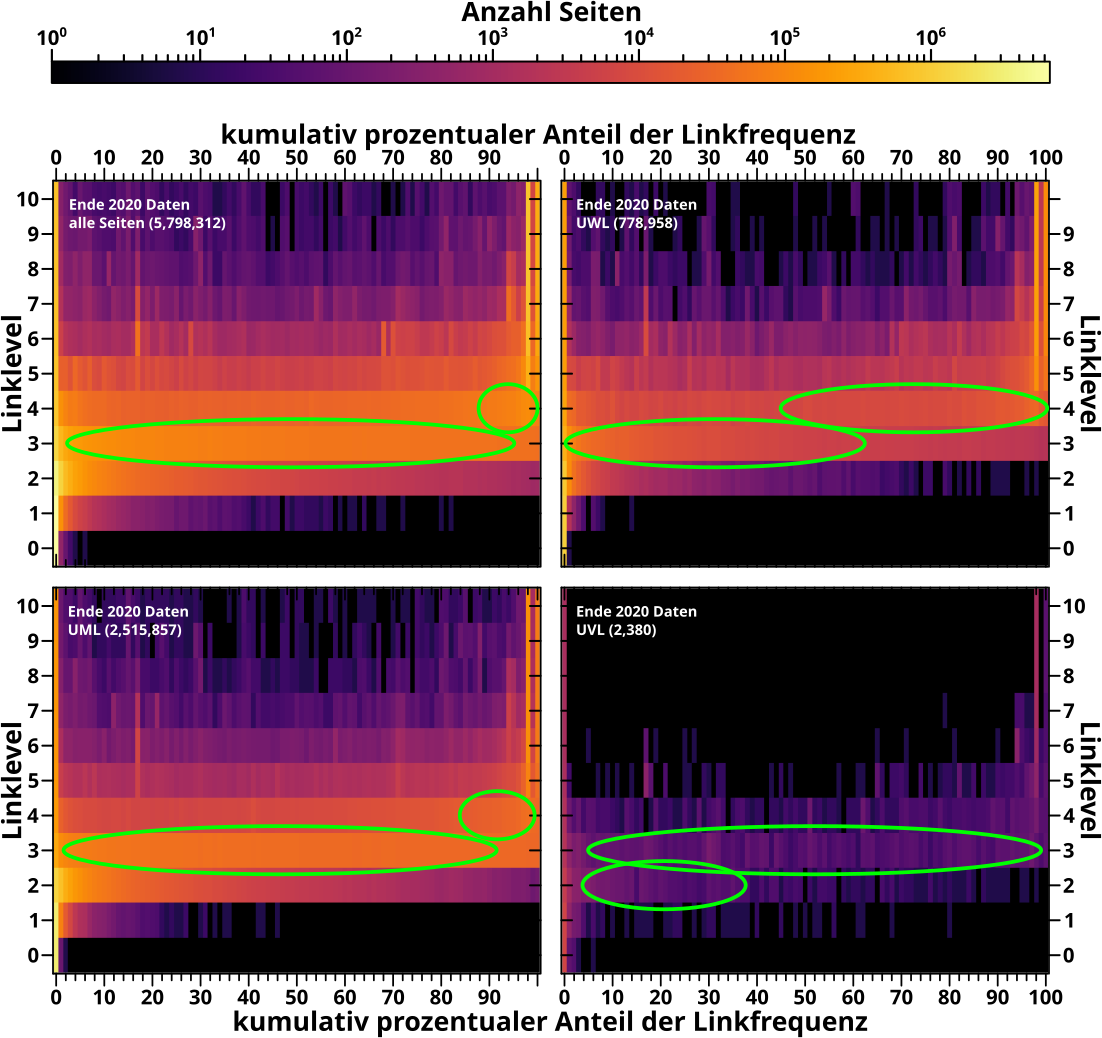
… aber wenn man genauer hinschaut ist’s gar nicht so anders und im Vergleich mit den durchschnittlichen Werten stimmt das wieder gut (genug) ueberein. Die Markierungen sind ’ne „Abschaetzung nach bestem Wissen“ … also was mein Bauchgefuehl mir sagt.
Hier „verschmiert“ sich alles viel mehr, die Lage ist also mitnichten so eindeutig wie bei den neuen Links oben. Das wusste ich nicht bevor ich die Bilder zum ersten Mal sah, ist ist aber genau der Grund warum ich meine, dass die Durchschnitte heikel sind.
Man sollte sich die Histogramme der einzelnen Linklevel im Detail ansehen um sicherere / genauere Aussagen treffen zu kønnen … aber das kann wer anders machen; mein Bauchgefuehl reicht mir an dieser Stelle zur Bestaetigung der vormaligen Ergebnisse und ich wollte ohnehin vor allem „nur“ die Machbarkeit und Nuetzlichkeit des Prinzips zeigen.
Fehlen noch die nach der Anzahl der Zitate (anderer Seiten) eingeteilten Untergruppen bzgl. der Linkfrequenz … Hier sind ’se:
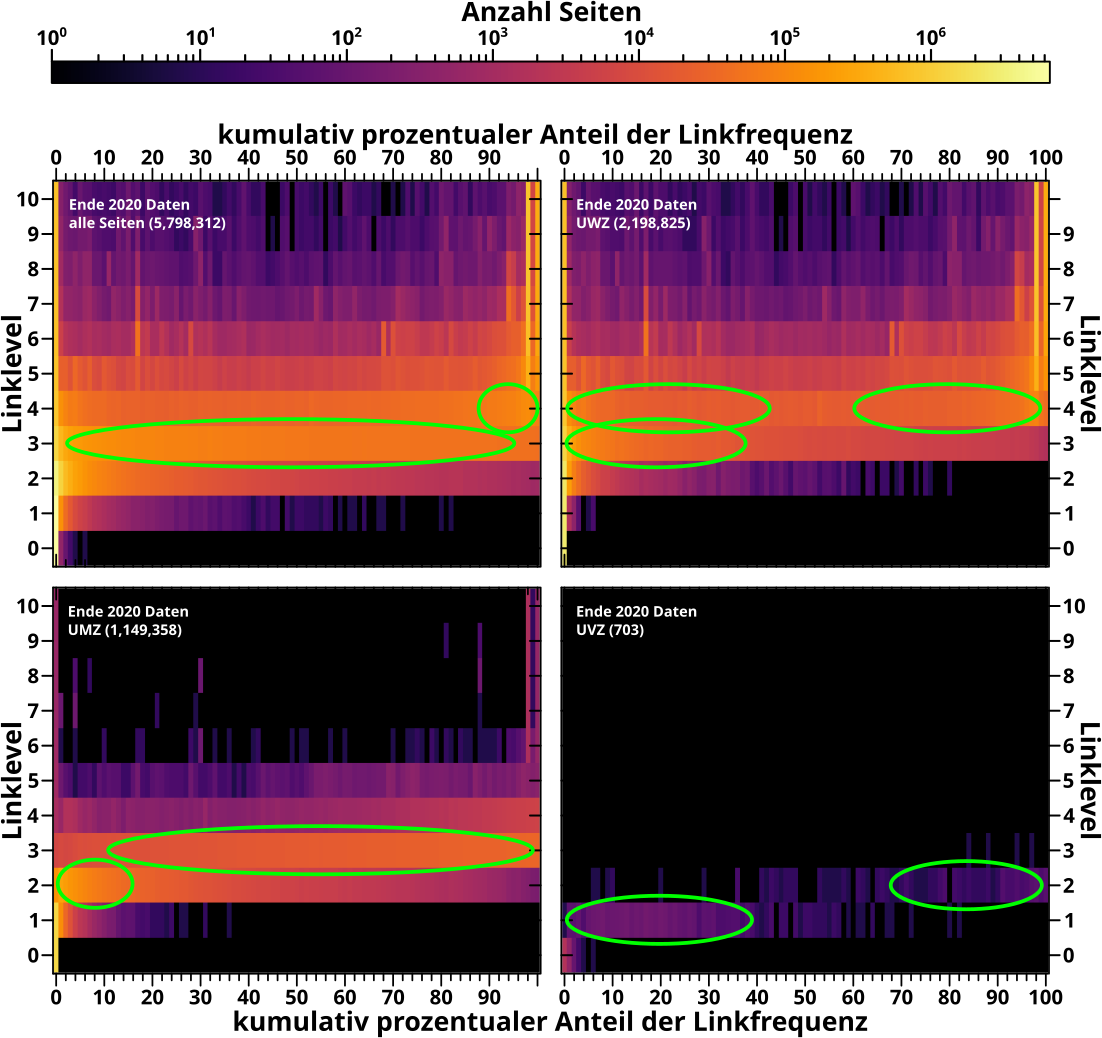
Bis auf eine Sache gibt’s nix anderes dazu zu sagen was nicht schon oben steht. Die eine Sache sieht man in der UWZ-Heatmap. Auf LL4 geht der Streifen mit relativ gleichmaesziger Intensitaet ueber die gesamte Breite. Aber wenn ich die Augen ein bisschen zukeife, dann sieht das so aus, als ob’s in der Mitte ein klein wenig dunkler ist — sich dort mglw. weniger Seiten tuemmeln als links oder rechts davon. Das waere dann eine „gespaltene Verteilung“, die im Durchschnitt ’ne „Zahl in der Mitte“ ergibt, welche aber nicht beschreibt wie die Seiten sich wirklich verhalten. Wieder: das kann wer anders mal genauer untersuchen, ich wollte aber drauf hinweisen … der Informationsinhalt sollte naemlich auch ausgenutzt werden.
Ich denke, dass ihr, meine lieben Leserinnen und Leser, das Prinzip verstandan habt. Damit soll’s fuer heute reichen und beim naechsten Mal kommt dann der Vergleich mit den 2023 Daten.