Beim letzten Mal ging ich auf „komische Sachen“ in der Darstellung der komprimierten Daten ein. Dabei handelte es sich im Allgemeinen um helle oder dunkle Streifen und Gebiete die irgendwie nicht ins Gesicht passten. Ich versuchte auch kurz darzulegen, warum es so wichtig ist, dass man sowas diskutiert — damit man Fehler in der Analyse erkennt und nøtigenfalls berichtigen kann, damit die Resultate am Ende kein Humbug sind.
Im selben Artikel sieht man einen „Blob“. Um die Besprechung dieses Blobs zu vereinfachen, rede ich heute ueber eine weitere Anomalie. Denn wenn ich diese zuerst behandel, dann sind die „Vorgaenge“ die zum Blob fuehren etwas besser zu verstehen (hoffe ich). Historisch war die Bearbeitung dieser zwei Sachen aber umgekehrt.
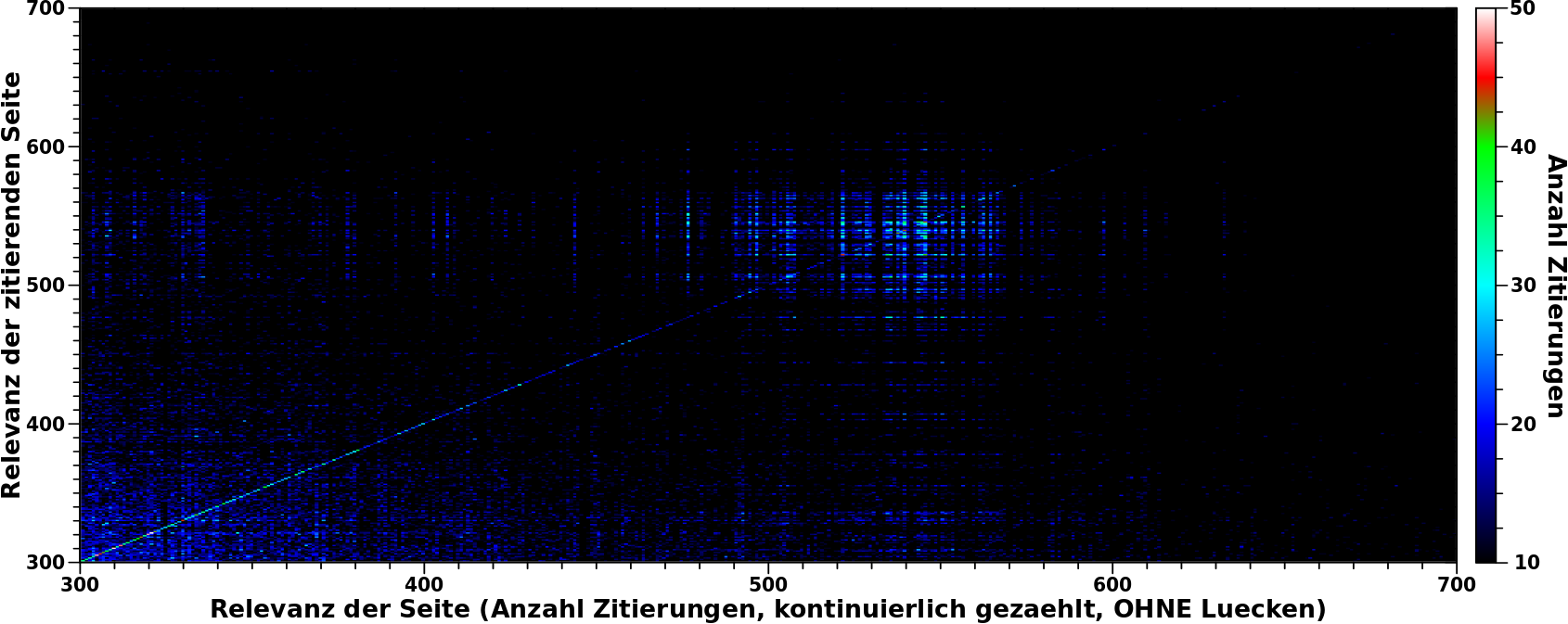
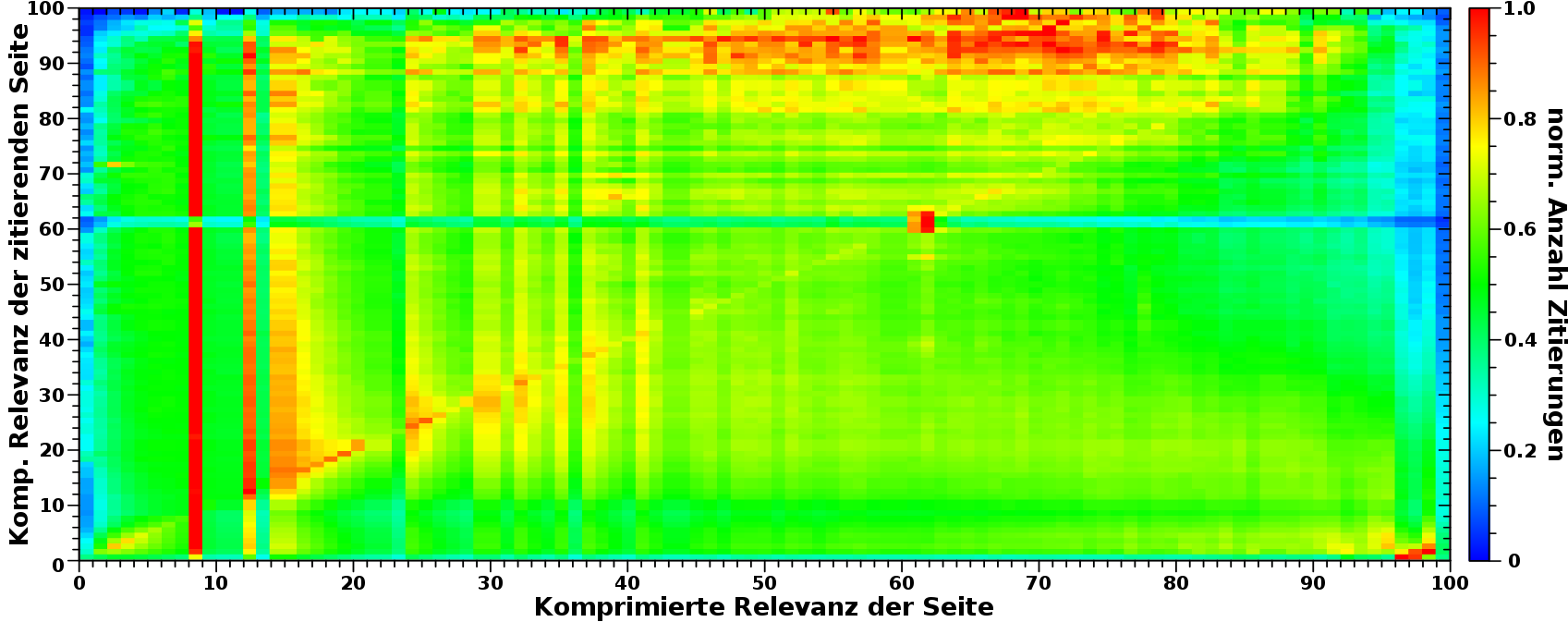
Wieauchimmer, bei meinen Untersuchungen zu den „komischen Sachen“ in den komprimierten Daten, schaute ich mir auch nochmal die nicht komprimierten Daten an. Und wenn man sich das vierte Bild im dazugehørigen Beitrag genau anschaut, dann sieht man da eine helle duenne Linie um einen Relefanzwert von ca. 2500 „hochlaufen“. (Und auch eine um einen Relevanzwert von ca. 4000 (und kuerzere Linien bei anderen Werten), aber die bei ca. 2500 ist mehr prominent.) Hier habe ich hereingezoomt:
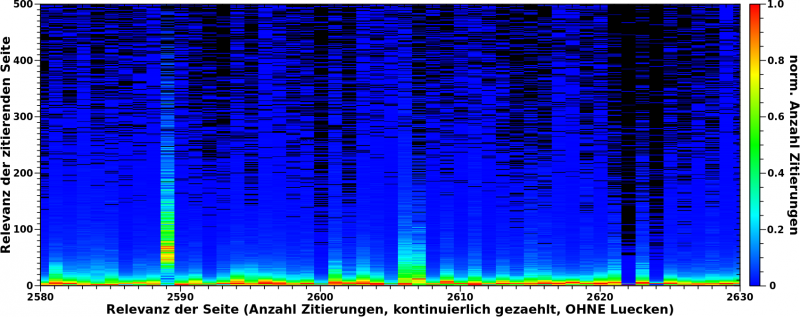
.oO(Nanu? Was ist denn das?) dachte ich da und wollte gerne herausfinden, worum es sich hierbei handelt.
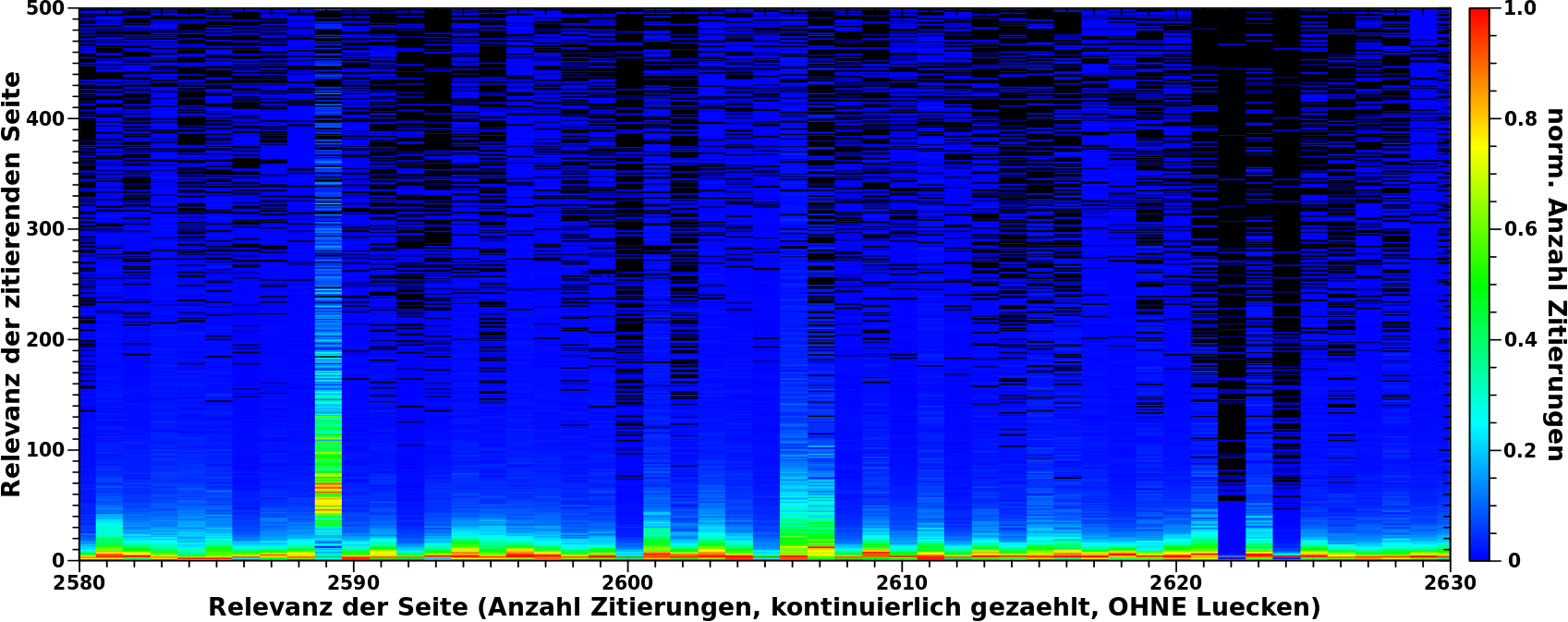
Als erstes konnte ich hier erkennen, dass der wahre Relevanzwert nicht „ca. 2500“ ist, sondern ganz genau bei 2589 liegt. Da Relevanzwert und Anzahl Zitierungen bei diesen Werten nicht mehr uebereinstimmen, ist zu sagen, dass dies bedeutet, dass alle Seiten die zum Signal beitragen jeweils 2622 mal zitiert wurden.
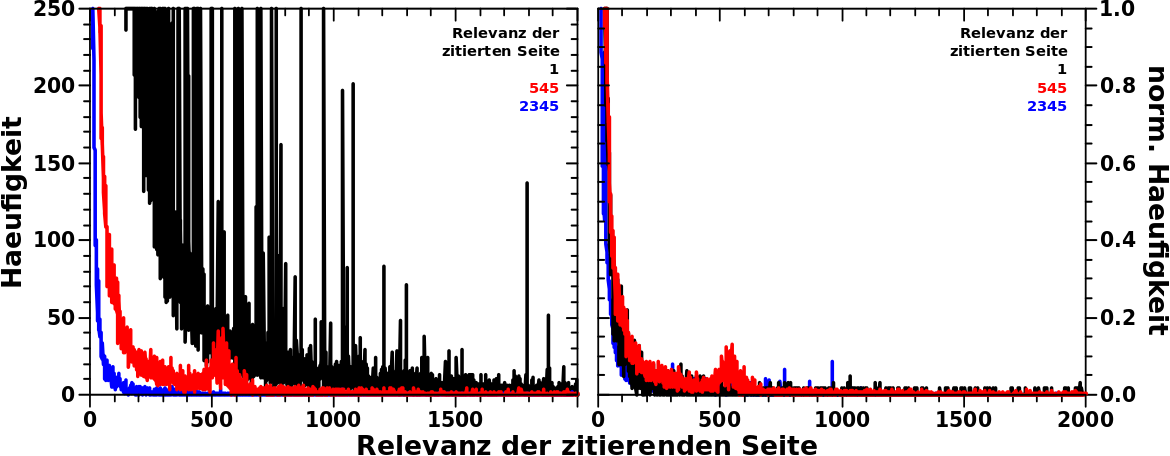
Ich war mir ziemlich sicher, dass das echt ist, aber ein „ich bin mir ziemlich sicher“ kann einen gehørig in die Irre fuehren. Deswegen schaute ich mir die Daten mal im Vergleich zu Relevanzwerten an, die in der Naehe liegen …
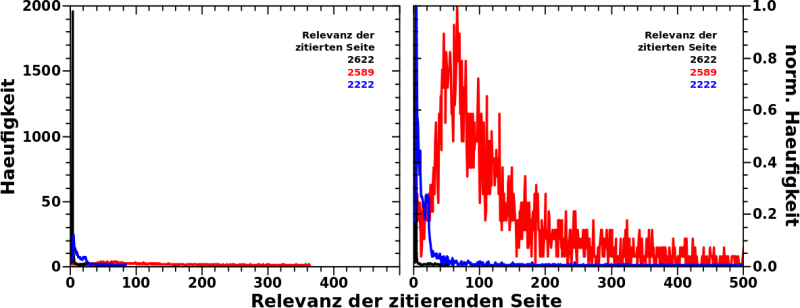
… und siehe da, das war tatsechlich anders (und tatsaechlich echt).
Ich gebe zu, dass der Relevanzwert (!) der schwarzen Kurve mit 2622 aeuszerst unguenstig gewaehlt wurde. Ist doch dieser Wert genauso grosz wie die Anzahl der Zitierungen (!), welche die Seiten die zum Signal beim Relevanzwert 2589 beitragen erhalten haben. Es gibt natuerlich einen Grund warum ich diesen Wert waehlte und darueber spreche ich ganz am Ende. Insgesamt bedeutet das, dass ich dann halt immer sagen musswas ich meine, wenn die Zahl 2622 auftaucht. Andererseits verdeutlicht dies nochmals den Unterschied zwischen diesen beiden Grøszen.
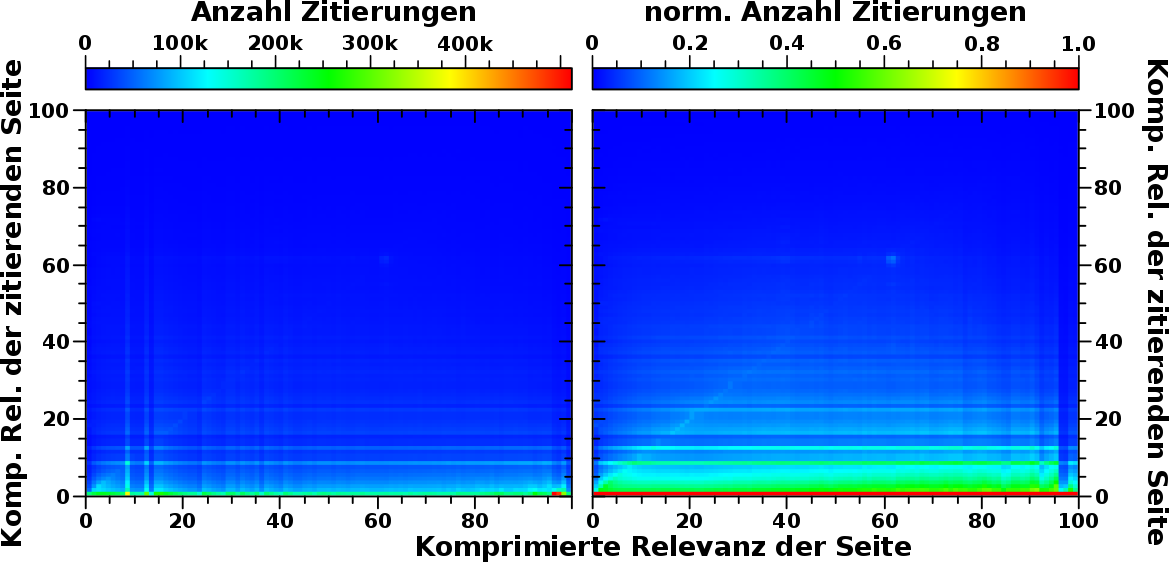
Wieauchimmer, erwartet haette ich sowas wie die schwarze oder blaue Kurve: (mehr oder weniger) grosze Werte um kleine Relevanzwerte, sowohl in den normierten, als auch in den NICHT normiert Haeufigkeitskurven. (Im Grunde genommen sind obige Kurven Histogramme, nur eben als Kurven und nicht als Balken.)
Anstatt dessen ist die nicht normierte Kurve der Anomalie (rot) super flach, aber langgestreckt. Ein kleiner „Huppel“ (bei dieser Skalierung der Ordinate) scheint bei Relevanzwerten (der zitierenden Seite) von ca. 50 zu liegen. Und tatsaechlich, in der normierten Darstellung tritt der „Huppel“ deutlich hervor.
Das ist also gleich zweifach ungewøhnlich. Zum Einen, dass sich die 2622 Zitierungen so breit ziehen ueber viele viele verschiedene Relevanzwerte (der zitierenden Seiten). Zum Zweiten, dass das Maximum nicht bei kleinen Werten liegt, sondern zwischen Relevanzwerten (der zitierenden Seiten) von 30 bis ca. 130.
SPANNEND!
Zunaechst schaute ich mir an, welche Seiten denn genau 2622 mal zitiert wurden. Und siehe da, es war nur eine einzige Seite: CinemaScore.
Das ist gut, macht es den Rest doch gehørig einfacher.
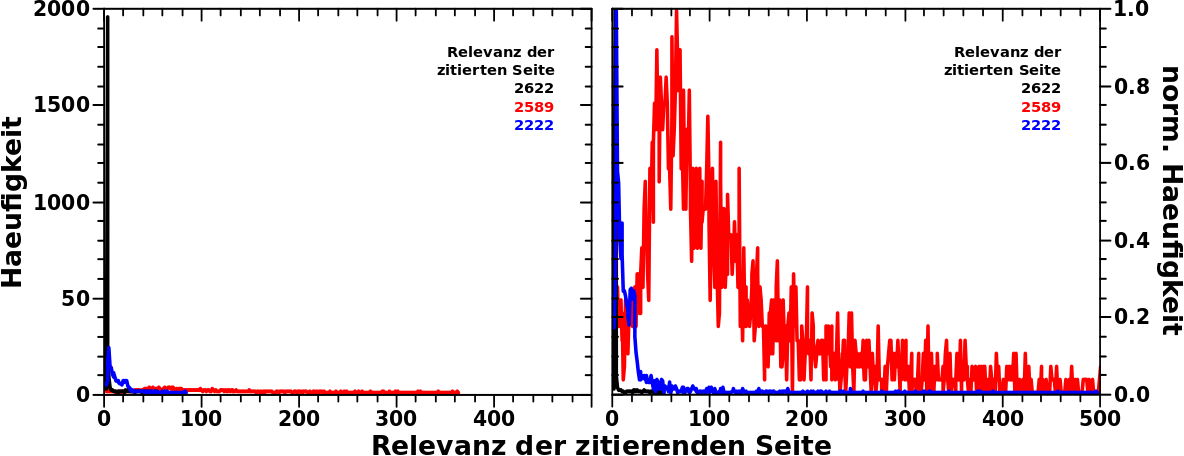
Nun schaute ich, welche Seiten diese Seite zitieren. Von Interesse sind eigentlich nur Seiten die zum Peak im rechten Diagramm beitragen. Die Grenzen dieses Peaks setzte ich (durch scharfes Hingucken) bei Relevanzwerten von 30 bzw. 130 fest. Innerhalb dieser Grenzen liegen mehr als 1800 der 2622 Zitate. Dass mich nur der Peak interessiert liegt daran, dass dieser Peak ja gerade die Anomalie ist. Sehr viele Wikipediaseiten werden von (meist wenigen) (anderen) Seiten mit Relevanzwerten von weniger als 30 oder mehr als 130 zitiert … das ist also das „Normalsignal“ … aber ich bin ja gerade an dem nicht normalen Signal interessiert.
Ich schaute zwar nicht alle ueber 1800 Seiten an, aber es stellte sich heraus, dass alle die ich anschaute zu Filmen gehørten. Und na klar, das ist ja sinnvoll, dass Filme CinemaScore zitieren.
Zur Sicherheit im schaute ich dann doch noch auf die Seiten auszerhalb dieser Grenzen und es stellte sich heraus, dass es sich bei den Stichproben auch ausschlieszlich um Filme handelte. … naja … das war eigentlich nicht mit Absicht, sondern ich hatte einen logischen Fehler im Programm weswegen ich mir das anschaute … aber das Resultat stellte sich ja dann als „hey gute Extrainformation“ heraus … noch mal Glueck gehabt ;)
Dann fragte ich mich aber, wer zitiert eigentlich Filme so oft. OK, 30 Zitate kann ich mir durchaus vorstellen: (mehr oder weniger) beruehmte Leute wirken in Filmen mit und auf deren Seiten wird dann der Film genannt. Und sehr beruehmte Filme werden bestimmt auch øfter als 130 mal zitiert. Aber die Mehrzahl der Filme ist ja eben mehr als 30 und weniger als 130 mal zitiert worden.
Das machte mich stutzig und ich nahm (ziemlich zufaellig ) drei Stickproben: The Astronaut Farmer (31 Zitierungen), America’s Sweethearts (81 Zitierungen) und The Faculty (130 Zitierungen).
Es stellte sich heraus, dass die Seiten welche diese Filme zitieren grob gesagt in drei Kategorien eingeordnet werden kønnen:
1.: Zeug, welches direkt dem Film zuzuordnen ist und eine eigene Wikipediaseite hat. Das sind natuerlich Schauspieler, Regisseure und andere Menschen die am Film mitwirken. Aber dazu gehøren auch die verschiedenen Studios, einzelne Songs (es gibt echt viele Lieder die ihre eigene Wikipediaseite haben), Drehorte und so’n Zeug halt.
2.: Im wesentlichen Listen, in denen der Film auftaucht. Das ist so trivial wie 2007 in home video oder List of films shot in Las Vegas kann aber auch sowas nicht ganz so offensichtliches wie Deaths in June 2014 oder List of films featuring extraterrestrials sein. Und dann natuerlich auch die Filmografien der beteiligten Leute (oder manchmal auch die Diskographien von Musikern, wenn die am Soundtrack mitgewirkt haben).
Bei all meinen Untersuchungen zur Wikipedia ist das eine der Sachen die mir am wenigsten bekannt waren: wie krass viele (teils bizarre) Listen es auf der Wikipedia gibt.
3.: Anderes Zeug wie bspw. andere Werke (meist Buecher) die den Film beeinflusst haben oder Filme deren Einkommen an der Kinokassen mit dem Film in Frage verglichen werden. Manchmal wird der Film auch einfach nur erwaehnt (und beim schnell drueber schauen habe ich den Zusammenhang zum Film nicht unbedingt erfassen kønnen) oder eine Sache mit Wikipediaseite passiert so selten, dass deren auftreten in einem Film von Interesse ist (bspw. Fatsuit).
Der Anteil dieser Kategorien an den Zitaten ist erstaunlich konstant (zugegeben, meine Stichprobe ist aeuszerst klein!).
Bei The Astronaut Farmer stammten jeweils 21, 7 und 3 Zitierungen aus den entsprechenden Kategorien. Bei America’s Sweethearts sind die Werte 57, 21 und 3 Zitierungen und bei The Faculty 75, 32 und 23 Zitierungen. Die Anteile sind in diesem, fuer diese Art von Information (beinahe) vøllig unbrauchbarem, Tortendiagramm zu sehen:
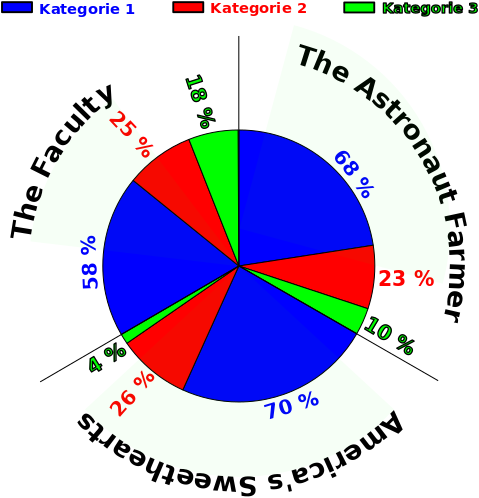
Hæhæ … JA, ich habe da extra Zeit reingesteckt um endlich auch mal diesen haesslichsten aller Diagrammtypen zu benutzen. Aber mit viel Muehe kann man sehen, was es ausdruecken soll.
Es geht also doch alles mit linken Dingen zu. Ich hatte mir nur nie Gedanken darueber gemacht, wie viele Leute (oder Orte, oder Songs etc.) bei selbst relativ unbekannten Filmen mitwirken. Ebenso dachte ich auch nie darueber nach, wie die Gesamtheit der an der Erschaffung dieses Werkes beteiligten „Objekte“ (im weitesten Sinne!) dann „zurueck wirken“ auf den Rest der Kultur.
Und da sage nochmal wer, dass Filme nur „wichtig“ sind, wenn sie was „Besonderes“ sind … siehe auch hier.
Im Endeffekt fuehrt das dazu, dass Filme eine Kuriositaet an sich sind. Dies deswegen, weil sie in ihrer Gesamtheit im Durchschnitt mehr Zitierungen auf sich vereinen als die „durschnittliche Wikipediaseite“ (was immer das auch sein mag). Denn Letztere wird eher selten zitiert.
All das fuehrt zur Anomalie, denn alle diese Film zitieren CinemaScore.
Und ich habe damit wieder ’n Stueck der Hintergrundzusammenhaenge in der (westlichen) Gesellschaft fuer mich sichtbar gemacht (vulgo: wieder was gelernt). Alles nur, weil es mir keine Ruhe gelassen hat, dass da was in den Daten war, was (erstmal) nicht rein zu passen schien.
Ganz zum Abschluss dann noch die dunkle Linie beim Relevanzwert (!) von 2622 (ich schrieb doch, dass ich darauf nochmal zurueck komme) . Dabei handelt es sich auch um nur eine Seite, naemlich: Świętokrzyskie Voivodeship. Soweit ich das verstehe, entspricht ein Land in Dtschl. geografisch drei Voivodeship in (nicht nur) Polen. Das sind also so ’ne Art Verwaltungsbezirke.
Wenn ich ehrlich bin, hatte ich schon vermutet, dass genau sowas hinter der „dunklen Anomalie“ liegt. Wusste ich ja von vorher, dass in Polen mal wer urst viele Wikipediaseiten geschrieben hat. Die zitierenden Seiten sind dann (beispielhaft) so wichtige Sachen wie Tomaszów, Gmina Opatów, Tomaszów, Gmina Tarłów oder Tomaszów, Pińczów County, die alle nur ein Zitat auf sich vereinen und Świętokrzyskie Voivodeship zitieren. Und weil das mehrere tausend Mal passiert, hat man dann den duennen roten Strich ganz dicht an der Abszisse in der Linie des Relevanzwertes (!) 2622 in der Falschfarbendarstellung … bzw. den langen duennen „Peak“ in der schwarzen Kurve in der Haeufigkeitsdarstellung.
Aber genug fuer heute. Dieser Beitrag ist schon wieder laenger als urspruenglich geplant. Aber ’s ist nunmal alles so spannend :)
Naechstes Mal wird’s ein bisschen komplizierter … aber nicht dolle.