Beim letzten Mal unterzog ich die Daten einer mathematischen Transformation um aus dem „Rauschen“ noch mehr Information heraus zu holen. Weil der Artikel schon so lang war verschob ich die Diskussion der zeilenweise normierten Daten …
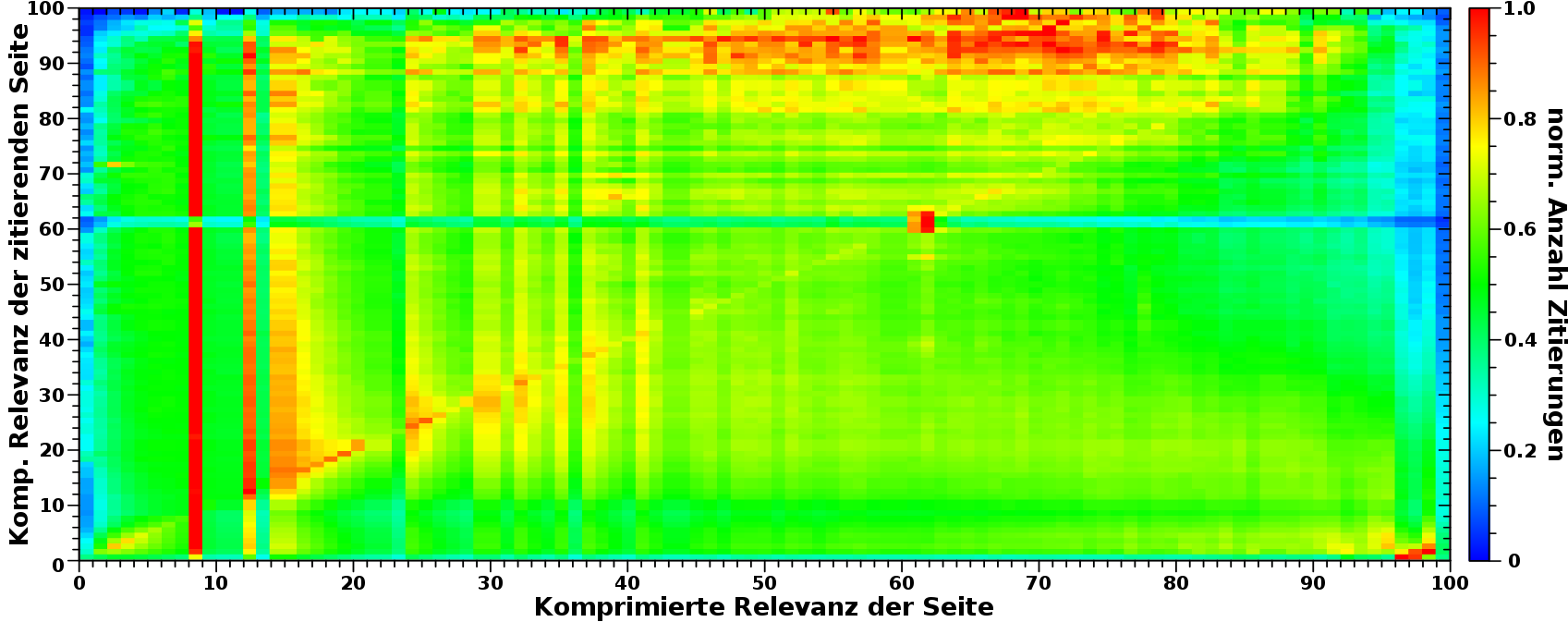
… auf einen anderen Beitrag (diesen hier), denn durch diese Darstellung muss ein vorheriges Resultat etwas modifiziert werden.
Aber der Reihe nach. Zunaechst springt einem die rote und ueberhaupt die vertikalen Linien ins Gesicht. Das sind wieder besagte Artefakte der Komprimierung. Das ist ueberhaupt nicht schlimm, denn wir wissen ja, wie diese Linien entstehen: Zusammenfasung der Werte zweier Spalten die mehr Zitierungen repraesentieren als „normale“ Spalten. Dadurch sind besagte (zusammengefasste) Werte grøszer als im Durchschnitt in den anderen („normalen“) Spalten. Das extreme Beispiel der roten Linie kommt durch die Komprimierung zweier (urspruenglicher) Spalten zustande (alle Seiten mit 9 oder 10 Zitierungen, siehe die Tabelle vom letzten Mal). Die Farbe Rot entspricht nun dem Wert 1. Wenn ich das halbiere (wg. zwei urspruenglichen Spalten), lande ich bei 0.5 und das wuerde der Farbe Gruen entsprechen und in die Umgebung passen. Alles ist also knorke.
Analog kann man fuer alle vertikalen Linien argumentieren, nur muss man aufpassen, dass man nicht die Anzahl der urspruenglichen Spalten betrachtet, sondern die Anzahl der Zitierungen, die diese repraesentieren.
Als naechstes sind die „invertierten Artefakte“ am linken und rechten Rand zu besprechen. Diese Spalten sind blaeulich, reprasentieren also geringe Werte. Das ist dadurch zu erklaeren, das der erste und letzte Wert auf der Abzsisse nur „halbe Prozente“ sind. Alles von 0.0 % bis 0.5 % wird zu Null komprimiert, waehrend fuer Eins alles von 99.5 % bis 100.0 % herangezogen wird. Dito zum Ende der Ordinate. Entsprechend weniger Gesamtzitate sind in diesen Spalten vereint und deswegen wir das blau in der zeilenweise normierten Darstellung.
In Analogie zu obigen Aussagen kønnte man hier den „Blauwert“ verdoppeln und dann wuerde man auch wieder ungefaehr bei Gruen landen.
Nun eine kleine Peinlichkeit: die Linie die einmal quer uebers Bild geht bei Feldern wo der Wert auf der Ordinate, dem Wert auf der Abszisse entspricht; bspw. (23, 23). Diese Linie sieht man sogar schon in den urspruenglichen, nicht normierten Daten. Der Grund dafuer geht ganz weit zum Anfang dieser Untersuchungen zurueck, als ich versuchte so viel wie møglich uninteressante Sachen aus den Rohdaten zu løschen.
Dabei ist mir entgangen, dass manche Seiten (mit einem gewissen Wert auf der Abzsisse) sich selbst zitieren (was dem selben Wert auf der Ordinate entspricht). Oder vielmehr Abschnitte im selben Artikel zitieren, aber das kommt auf’s Gleiche hinaus. Ich wuerde sagen der Anteil der Seiten die das machen ist ca. 10 Prozent … ich schiebe das also in den Fehler … gebe aber zu, dass das eine Sache ist, die man heraushalten kønnte.
Das ist sehr wichtig solche Sachen zu besprechen, denn wenn man nicht weisz wo das herkommt, dann kønnte es sein, dass die Resultate an denen man interessiert ist selber auch nur ein Artefakt (und damit Humbug) sind.
Als Letztes dann der „rote Blob“ beim Wert (61, 61). Zunaechst dachte ich, dass dieser durch die zwei obigen Erklaerungen erklaert werden kønnte (Komprimierung + Peinlichkeit). Und waehrend diese beiden Dinge da sicherlich mit reinspielen, sollte deren Einfluss nicht so grosz sein, dass dieser Blob so krass dominiert in der Region. Also untersuchte ich das weiter und es stellte sich heraus, dass das KEIN Artefakt ist! Vielmehr ist das eine echte Anomalie und man sieht das auch in den urspruenglichen Daten, wenn man weisz wo man schauen muss. Ich brauchte drei Wochen um rauszufinden was das ist (zugegeben, unterbrochten durch total viel Sci-Fi Serien schauen und zocken). Und weil das laenger dauert zu erklaeren und dieser Artikel hier eh schon so lang ist wird die Erklaerung dieses Blobs auf’s naechste Mal verschoben.
Zieht man die Artefakte in Betracht und ignoriert erstmal den Blob, dann bleiben drei echte Beobachtungen zurueck:
1.: das Meiste ist gruen,
2.: im oberen Bereich hat man ein rotes Gebiet,
3.: in der rechten unteren Ecke ist’s rot und die entsprechenden Spalten werden blau zum oberen Ende hin.
Ersteres bedeutet, dass (relativ gesehen) unabhaengig vom Relevanzwert jede Seite gleich haeufig zitiert wird unabhaengig von der Relevanz der zitierenden Seite. Das deutete sich bei den urspruenglichen zeilenweise normierte Daten, bereits an, weil dort der gruen/rote „Streifen“ sich so verschmiert. Das ist mir an der Stelle nur nicht aufgegangen. Somit hat die Komprimierung nicht nur Information aus dem „Rauschen“ gezogen sondern auch dies deutlich gemacht.
Punkte 2 und 3 schraenken diese Aussage etwas ein. Das rote Gebiet bei Relevanzwerten ueber 80 auf der Ordinate und Relevanzwerten zwischen 30 und 90 auf der Abszisse deutet darauf hin, dass oft zitierte Seiten haeufiger ueber andere mittel und oft zitierte Seiten reden. Das ist die erwaehnte Modifikation des vormaligen Ergebnisses und genau das was ich meinte, als ich sagte, dass im „Rauschen“ noch was zu holen ist. Cool wa!
Aber Achtung: „irrelvante“ Seiten machen weiterhin einen signifikanten Teil des Signals in diesem Bereich aus.
Punkt 3 zeigt dann nochmals deutlich, dass die Relevanz insb. der meistzitierten Seiten nur dadurch kommt, dass diese von „extra irrelevanten“ Seiten ueberproportional haeufig zitiert werden. Das ist schon ein bisschen ironisch, nicht wahr.
Alles in allem kann die Relevanzdiskussion damit abgeschlossen werden. Man kann relevante Seiten nicht ohne „irrelevante“ Seiten haben. Und das ist voll messbar.
Aber ja, ich weisz, dass die Relevanzdiskussion eigentlich gar nicht darum geht.
Auch wenn dies damit erledigt ist, bin ich noch nicht fertig mit diesen Analysen. Beim naechsten Mal diskutiere ich eine weitere Anomalie in den (nicht komproimierten) Daten. Dieser erklaert die Methodik mit welcher ich den Ursprung besagter Anomalie aufklaeren konnte, aber am Beispiel nur einer Seite. Im Beitrag danach diskutiere ich den „Blob“ bei dem diese Methodik auf tausende (im Allgemeinen) bzw. hunderte (im Speziellen) Seiten gleichzeitig angewendet wird. Und dann kommen zwei Artikel mit anderen Kuriositaeten. Diese Daten sind voll ’ne Schatztruhe und ich stosze auf Dinge die ich nie erwartet haette. Aber dann bin ich damit fertig und es geht nach einem fast fuenfrmonatigen „Einschub“ endlich weiter mit den urspruenglichen Betrachtungen zum Linknetzwerk.
Leave a Reply