Beim letzten Mal habe ich aufgrund der Laenge den Artikel zu einem Ende gebracht. Es fehlt aber noch das hier:
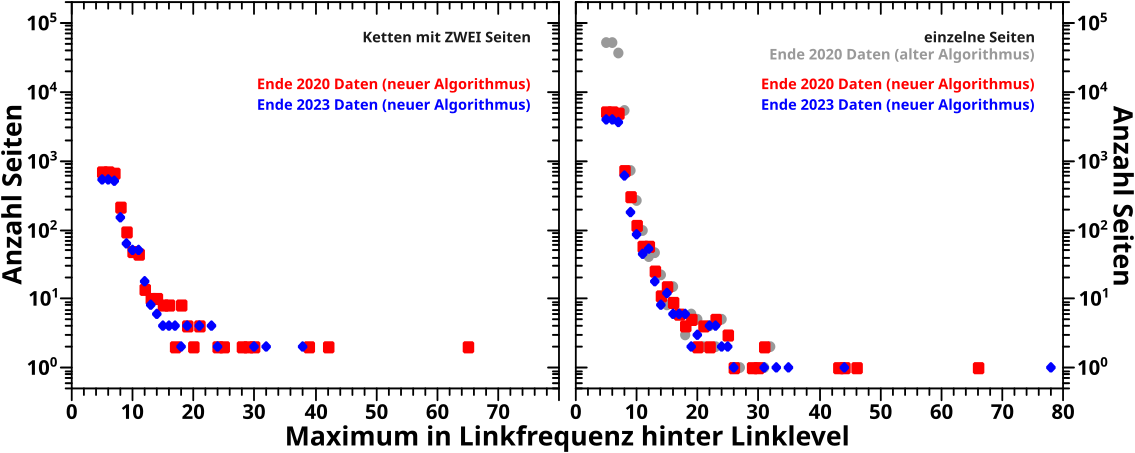
Im linken Diagramm sieht man die Anzahl der Seiten in Ketten mit zwei Seiten. Man erinnere sich, dass diese eine wichtige Rolle spielten, um beim letzten Mal Unterschiede zwischen dem alten und dem neuen Algorithmus zu erklaeren.
Nun sieht man hier, dass die mittels des neuen Algorithmus gefundenen Resultate fuer die 2020 Daten (rote Punkte) reproduziert werden von den Resultaten der 2023 Daten (blaue Punkte).
Man baechte, dass ich das nicht mit dem alten Algorithmus vergleichen kann. Denn der hat das nicht gesondert betrachtet und solche Seiten direkt in die Familien mit reingepackt (wo ich die in den aggregierten Daten nicht mehr identifizieren kann).
„Ketten“ mit einer Seite wurden vom alten Algorithmus auch nicht gesondert betrachtet. Aber die kann ich einfach ausrechnen, wenn man von der Gesamtzahl der potentiellen Kettenseitenkandidaten alles abzieht das betrachtet wurde (denn was uebrig bleibt konnten weder Familienseiten noch Anhaenger sein). Und wie man im rechten Diagramm sieht, stimmt das alles im Wesentlichen mit dem was der neue Algorithmus produziert ueberein und auch die neueren Daten reproduzieren das Ganze. Warum das am Anfang unterschiedlich ist wurde ausfuehrlich beim letzten Mal diskutiert.
Mehr gibt’s dazu nicht zu erzaehlen. Zusammenfassend bzgl. der Ketten sei das Folgende gesagt: Waehrend „laufender Untersuchungen“ (auch wenn es nur die Reproduktion war) wurde der Algorithmus geaendert. Das sollte man nicht machen, selbst wenn man die selben Ergebnisse bekommt. aber wenn man’s macht, dann ist es wichtig die Unterschiede zu diskutieren. Deswegen wurde der letzte Artikel so lang.
In diesem Fall kann ich sagen: Reproduktion geglueckt, sowohl zwischen alten und neuen Daten, als auch zwischen altem und neuem Algorithmus. Alle Unterschiede finden eine Erklaerung entweder im geaenderten Algorithmus und dessen geaenderten Parametern, oder in einer (zum Teil extrem) geaenderten Datenlage.
Mit letzterem meine ich natuerlich die „Meshir-Kette“ die ein weiteres Kommentar verdient. Was ich gestern diesbezueglich sagte kønnte ich prinzipiell im Code anpassen. Das waeren aber spezielle Faelle und die machen mich immer etwas unruhig. Lieber habe ich es, dass man „Fehler“ in den Daten sieht und dann versteht wo die herkommen. Denn so bekommt man die eingeordnet um dann (hoffentlich) zu sehen, dass die eigtl. nix Besonderes sind. Und wenn doch, dass man dann neues cooles Zeuch entdeckt. Diese Herangehensweise ist besser, als das vor den Nutzern im Code zu verstecken … erwartet von besagten Nutzern dann aber auch, dass sie mitdenken und neugierig sind.
Leave a Reply