Bereits frueh stiesz ich auf das damals so benannte „São-Paulo-FC-Artefakt“ und es begegnete mir innerhalb des Kevin Bacon Projekts immer und immer wieder. Artefakt deswegen, weil ich zunaechst dachte, dass es durch die Behandlung der Daten vor der eigentlichen Linknetzwerkanalyse zustande kam. Weitere Untersuchungen zeigten aber, dass das gar kein Artefakt ist, sondern ein Phaenomen innerhalb der Wikipedia welches sich allgemeiner beschreiben laeszt.
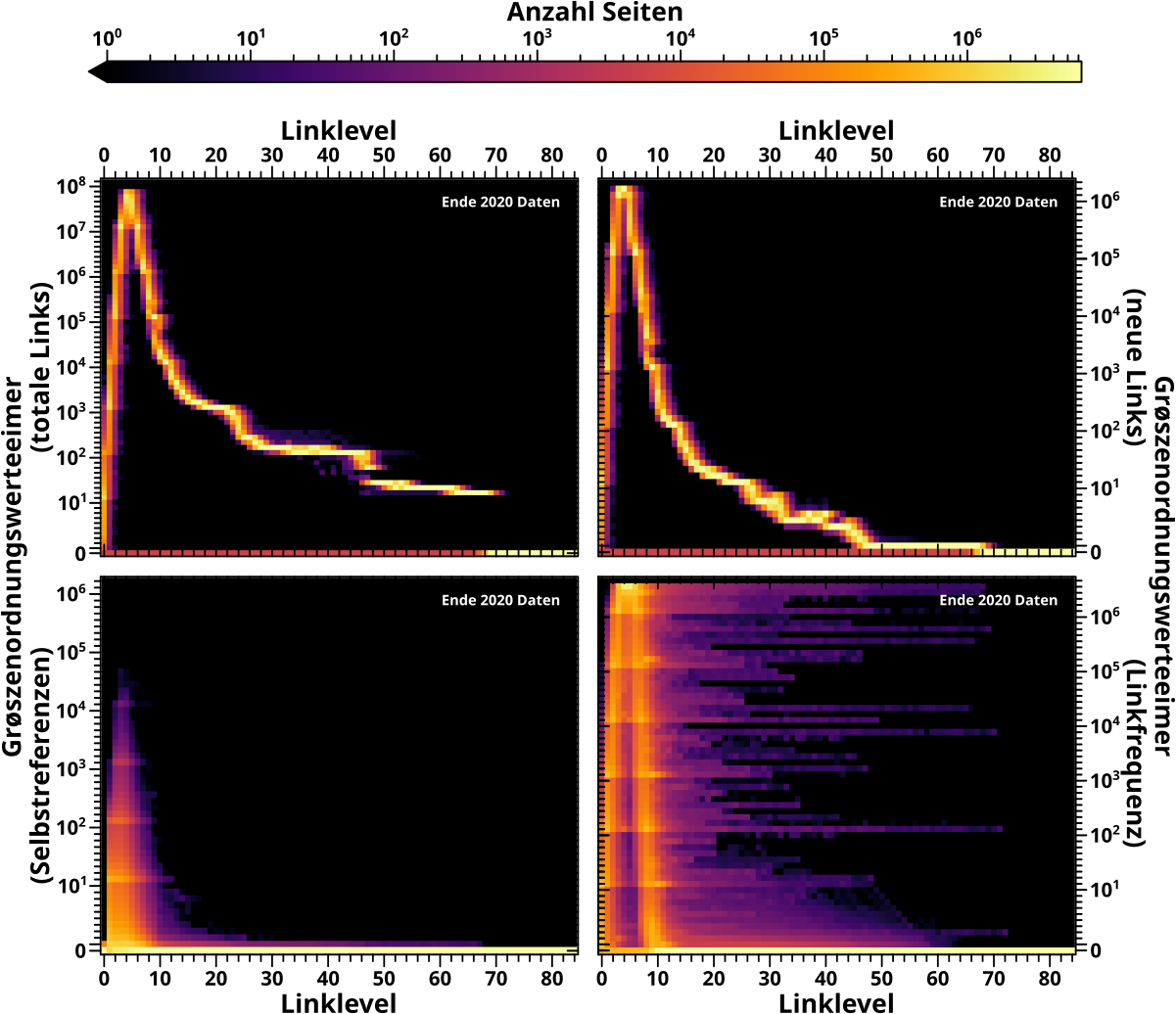
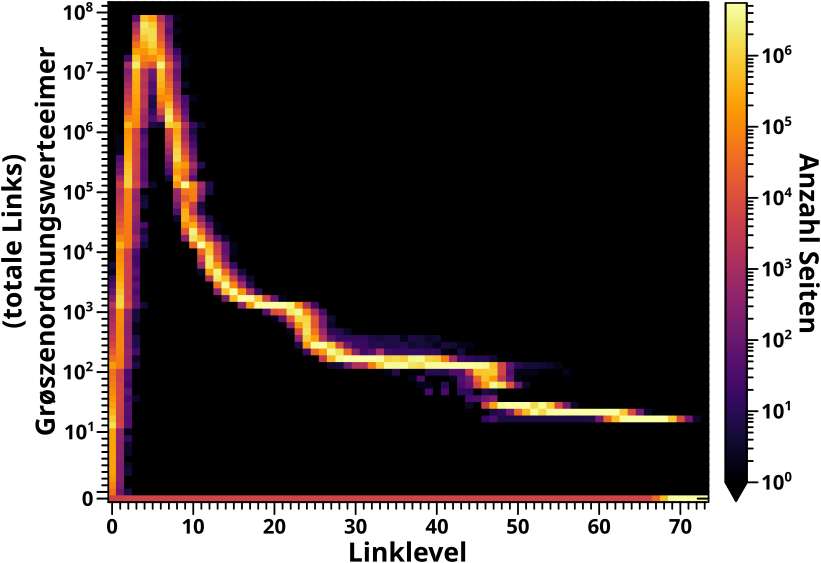
Zur Auffrischung und ganz kurz, handelt es sich dabei um thematisch zusammenhaengende Seiten die (mehr oder minder, aber oft buchstaeblich) chronologisch sortiert sind und bei der eine Kettenseite jeweils nur die direkt nachfolgende (oder vorhergehende, aber das ist nicht zwingend) zitiert. Das bedeutet, dass bei der Linknetzwerkanalyse alle anderen (nicht zur Kette gehørenden) Seiten ein Kettenglied nach dem anderen „durchschreiten“ muessen. Dies wiederum erklaert andere Beobachtungen. Insbesondere den langen „Schwanz“ in den gemessenen Grøszen, obwohl die allerallerallerallermeisten Seiten bereits nach weniger als 10 Linkleveln den allerallerallerallergrøszten Teil ihres Linknetzwerks gesehen haben.
Ich setzte mich dann daran solche Kettenseiten systematisch zu finden und das hab ich im Zuge der Reproduktion natuerlich nochmal neu gemacht.
Das Wichtigste zuerst: in den neueren Daten (von Ende 2023) gibt es das „São-Paulo-FC-Artefakt“ noch … da freue ich mich, denn es ist mir irgendwie ans Herz gewachsen. Es ist aber nicht mehr die laengste Kette sondern nur noch die viertlaengste und bereits auf LL35 hørt man das letzte Mal von ihr. Das ist natuerlich keine Kuerzung der Kette an sich ist, sondern kommt sicherlich durch eine bessere Verlinkung der Seiten zustande.
Der neue Kettenkønig sind die Tage des Meshir (ein Beispiel) … Huh? 30 Tage sind doch gar nicht lang genug. Wie kann das bis LL78 durchhalten? Die Erklaerung liegt darin, dass dies nur eine Teilkette ist, die rueckwaerts gehend mit den Tagen des Tobi (ein Beispiel) und dann des Koiak (ein Beispiel), und irgendwie vorwarts gehend aber mlgw. parallel (?) mit den Tagen des Paremhat (ein Beispiel) eine zusammenhaengende Kette bildet. Wobei die Verlinkungen sicherlich komplizierter sind als beim „São-Paulo-FC-Artefakt“ (welches der Tradition wegen weiterhin von mir als „Artefakt“ bezeichnet wird). Letzteres endet naemlich wie erwartet in 1930, …
[…] the first competitive season of São Paulo Futebol Clube […]
… waehrend der neue Kettenkønig hingegen bereits bei Meshir 18 stoppt. Es gibt da sicherlich auch ’ne Art „Archipelstruktur“ zwischen den einzelnen Seiten und wie angedeutet besteht eine Kette mglw. aus mehreren teilweise parallel laufenden, mehr oder weniger langen „Straengen“. Insgesamt aendert das aber nichts am Phaenomen an sich, solange die sich mehr oder weniger immer noch nur der Reihe nach zitieren und (vom Einstieg in die Kette abgesehen) nicht von Seiten auszerhalb der Kette zitiert werden … Kette ist Kette.
Die Verbindung von Teilketten zu einer langen Kette (was ja letztlich dann doch nur eine Kette ist) bringt mich zu einem wichtigten Punkt: Aenderungen im Algorithmus um Kettenseiten zu finden. Denn natuerlich schrieb ich den dazugehørenden Code nochmal neu und implementierte dabei einen vernuenftigeren Algorithmus … und das fuehrt natuerlich zu Unterschieden (wenn auch nicht all zu groszen) in den Resultaten.
Der damalige Algorithmus war ein „Kind seiner Entstehung“. Man sieht ueberall wie ich mit einer Idee anfing und im Laufe der Zeit immer mehr ueber dieses Phaenomen lernte. Dieses neue Wissen flosz dann stueckchenweise in den Code zurueck, ohne vorherigen Ablaeufe wesentlich zu aendern..
An der Identifikation potentieller Kettenseitenkandidaten hat sich nix signifikantes geaendert. Weiterhin werden nur solche Seiten betrachtet, die im Linkfrequenzsignal zum Einen bei einem (sehr) niedrigen Linklevel ein (sehr) kleines Signal aufweisen und zum Zweiten das Maximum jenseits eines gewissen (mehr oder weniger) hohen Linklevels haben. Ich erhøhte bzgl. Ersterem das Linklevel nur um eins (von LL4 zu LL5) und erniedrigte den erforderlichen Wert (von 23017 (welches sowieso 23517 haette sein sollen) zu 420 … aber das sind sowieso relativ willkuerliche Werte, es kommt nur drauf an, dass die grosz genug sind).
Damals sortierte ich dann von allen Kandidaten diejenigen aus, die den gleichen „Titelstamm“ (vulgo: „Familienname“) hatten (also bspw. „São Paulo FC season“ und das entsprechende Jahr am Anfang der jeweiligen Titel). Seiten die derart zusammengefasst werden konnten nannte ich „regulaere Familien“. Hier sieht man bereits, dass diese Herangehensweise NICHT den obigen (neuen) „Kønigskette“ zutage geførdert haette, denn dort kommen mehrere „Familien“ zu einer Kette zusammen. Alle derartig identifizierten Seiten wurden dann in den nachfolgenden Schritten nicht mehr mit einbezogen.
Bei den Kandidaten die nicht „regulaeren Familen“ zugeordnet werden konnten schaute ich dann, ob die von anderen, ebenso nicht „regulaeren Familen“ zugeordneten Kandidaten, zitiert wurden. War dies der Fall, wurden solche Seiten als potentiell zu „Patchworkfamilien“ zugehørig angesehen. War dies nicht der Fall, wurden sie als potentielle „Anhaenger zu regulaeren Familien“ eingeordnet.
Letztere wurden zu „echten“ „Anhaengern zu regulaeren Familien“ wenn diese auch von Seiten in „regulaeren Familien“ zitiert wurden. Der Rest wurde komplett aussortiert.
Als letztes schaute ich bei potentiell zu „Patchworkfamilien“ zugehørigen Kandidaten rueckwaerts (und NUR rueackwaerts) rekursiv, von wem die Seiten zitiert werden. Dabei wurden nur andere potentiell zu „Patchworkfamilien“ zugehørige Kandidaten beruecksichtigt. Auf diese Weise habe ich „Patchworkfamilien“ rekonstruiert.
Nun zum wichtigsten Unterschied im neuen Algorithmus: Ketten werden ZUERST via des erwaehnten rekursiven Algorithmus rekonstruiert. Dabei gehe ich jetzt aber rueckwaerts UND vorwaerts die Kette entlang. Ich folge also wieder von wem eine Seite zitiert wurde (rueckwaerts) aber neuerdings auch wen die besagte Seite selbst zitiert (vorwaerts). Das faengt zum Einen alle „Kettenglieder“ auf und erlaubt somit die Rekonstruktion der neuen Kønigskette. Zum Zweiten werden sofort alle „Anhaenger“ einer Familie als eben dieser Familie zugehørig erkannt (und zugeordnet). Und zum Dritten muessen „Patchworkfamilien“ nicht in einem extra Schritt zusammengebaut werden.
Danach sortiere ich „Ketten“ mit zwei oder gar nur einer Seite aus und schaue bei allen anderen Ketten ob diese „Kettenglieder“ mit einem gemeinsamen „Familiennamen“ enthalten. Ist dem so, so nehme ich (im Wesentlichen wie vorher, nur auf eine andere Art) eine Unterteilung in „Kernkettenmitglieder“ (vulgo: die „Familie“) und Anhaenger vor.
Die Resultate sind im Wesentlichen die gleichen, es kommt im Speziellen aber natuerlich zu mehr oder weniger groszen Abweichungen … die Diagramme dazu dann aber beim naechsten Mal.
Ach so, das noch: die Meshir-Kette gab es in den 2020 Daten noch nicht; ich habe die damals also mitnichten „uebersehen“.
Und das auch noch: Die Begriffe „Kette“ und „Familie“ sind im Wesentlichen synonym und werden in diesem und den nachfolgenden Beitraegen auch in dem Sinne benutzt. Das „im Wesentlichen“ ist aber wichtig. Bspw. ist es oft sinnvoller den Begriff „Familie“ in vielen Zusammenhaengen zu verwenden, weil das die zugrundeliegenden Konzepte besser veranschaulicht. Das Ganze ginge aber auch mit dem Begriff „Kette“, waere nur etwas umstaendlicher.
Es gibt aber auch ein paar Situationen wo es doch einen Unterschied macht. Wo „Familie“ doch nicht das Gleiche vermittelt wie „Kette“ und auch nicht ganz richtig waere. Ich werde das dann nicht extra erwaehnen, das sollte sich aber aus dem Kontext erschlieszen.