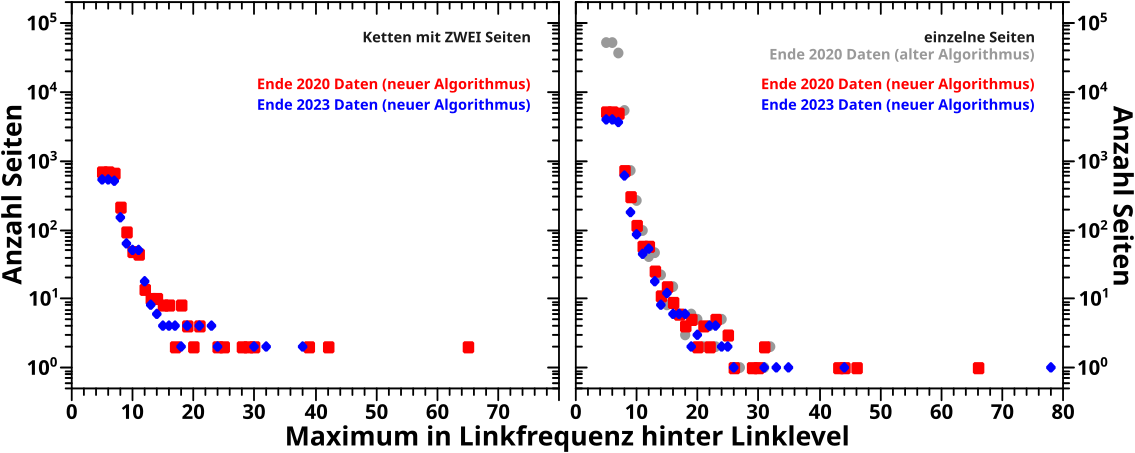
Nach den theoretischen Vorbetrachtungen zu den Aenderungen bzgl. der Reproduktion der thematisch zusammenhaengenden Ketten vom letzten Mal, kann ich heute ohne Umschweife sofort mit den Resultaten loslegen.
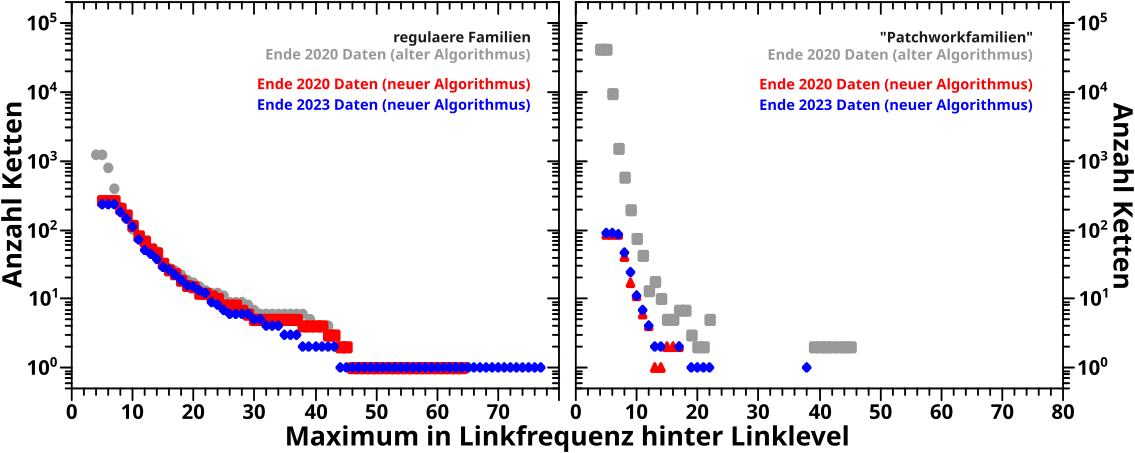
Im linken Diagramm …
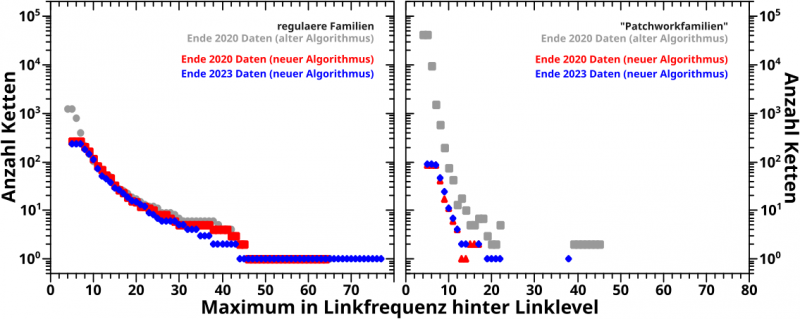
… sieht man die Anzahl der „regulaeren Familien“, also solche Ketten von Wikipediaseiten die alle (fast) den gleichen Titel haben (welcher im Wesentlichen dem Thema der Kette entspricht).
Die grauen Punkte sind die alten Resultate und von (sehr) kleinen Linkleveln abgesehen, reproduziert der neue Algorithmus bei selber Datenlage (rote Punkte, Ende 2020 Daten) die alten Resultate (mit geringsten Unterschieden ueber den Rest der Kurve … ich komme darauf zurueck). Und die neueren Daten (blaue Punkte, Ende 2023 Daten) wiederum reproduzieren im Wesentlichen die alten Daten.
Im Diagramm deutlich sichtbar ist, dass der alte Algorithmus ’ne Grøszenordnung mehr regulaere Familien um LL5 aufsammelt. Ich komme auch darauf zurueck.
Die „Patchworkfamilien“ nun werden bei selbem (neuen) Algorithmus reproduziert; das rote Signal hat im Wesentlichen die gleiche Staerke und den gleichen Verlauf wie das blaue Signal.
Aber man sieht einen sichtbaren Unterschied zu den mittels des alten Algorithmus produzierten Resultats. Auch darauf komme ich zurueck.
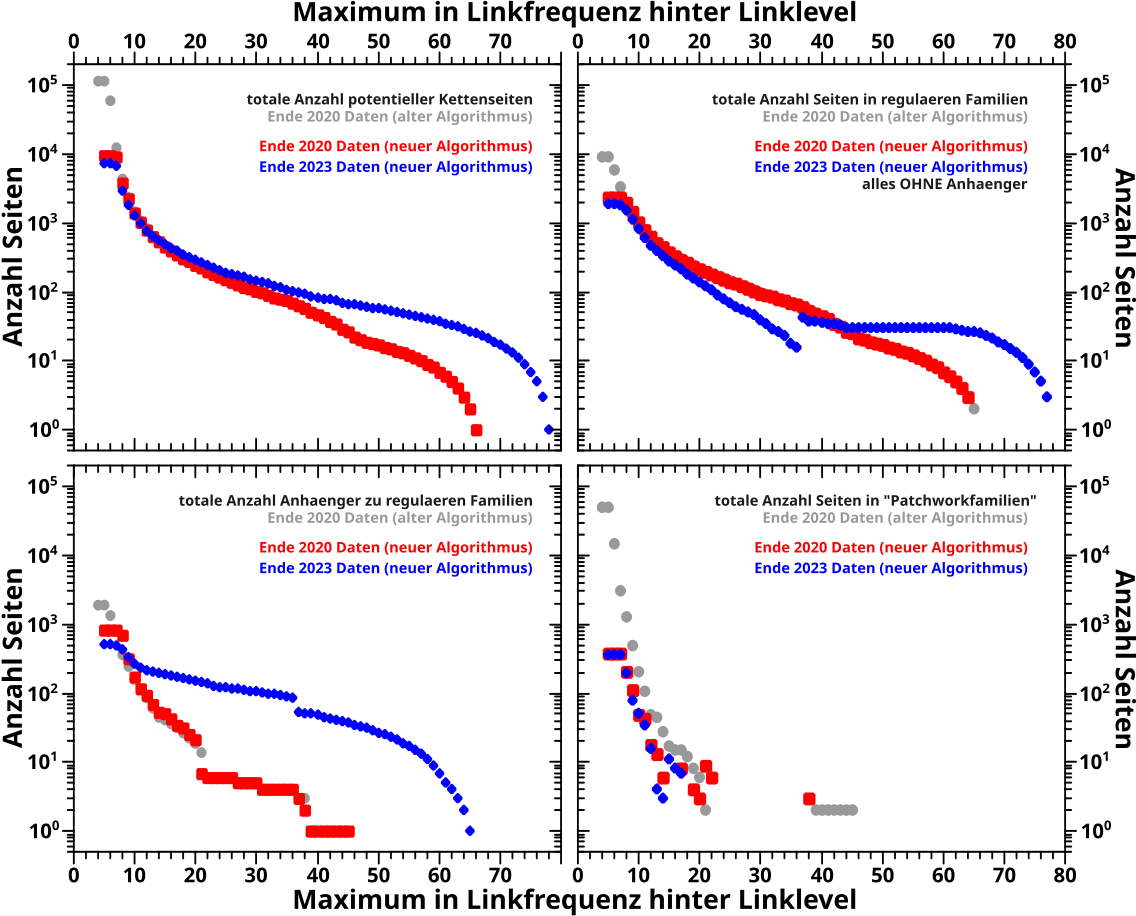
Die Grundlage einer Familie sind die Kettenseiten an sich und deren Entwicklung per Linklevel fuer die Daten aus verschiedenen Jahren und verschiene Algorithmen sieht man hier:
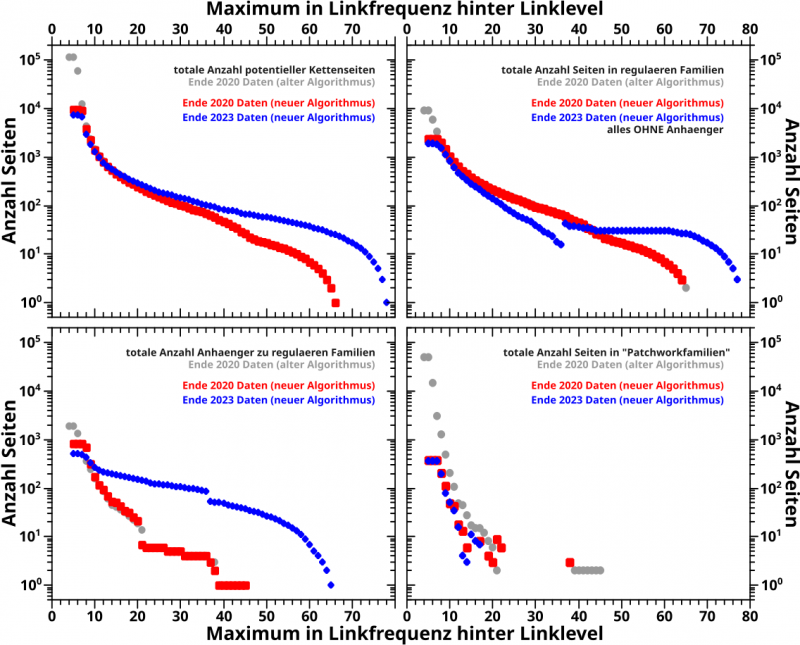
Ich beginne mit der Diskussion des linken, oberen Diagramms; der totalen Anzahl an potentiellen Kettenseitenkandidaten. Der gewaltige Unterschied zwischen der roten und blauen Kurve kommt durch die (deutlich) gaenderte Datenlage zustande. Ich hatte das bereits kurz beim letzten Mal anklingen lassen (siehe der Kettenkønig … die Tage des Meshir, Tobi, Koiak und Paremhat, die es in den 2020 Daten noch nicht gab) und werde das im Zuge zweier andere Diagramme genauer beleuchten.
Der neue Algorithmus reproduziert mit den 2020-Daten im Wesentlichen die Resultate des alten Algorithmus es gibt aber wieder eine signifikanten Abweichung bei (sehr) kleinen Linkleveln. Das ist einfach zu erklaeren: die Suchparameter wurden leicht veraendert. Wenn ich mit dem neuen Algorithmus die alten Suchparameter benutze, komme ich auf die selbe Anzahl an potentiellen Kettenseitenkandidaten fuer alle Linklevel. Das war zu erwarten (aber es ist wichtig, dass ich das geprueft habe). Ab LL19 waren die Ergebnisse ohnehin die selben, auch bei geaenderten Parametern.
Oder anders: mit den urspruenglichen Parametern hab ich fuer (sehr) kleine Linklevel viele falsche positive Ergebnisse (vulgo: „Muell“) aufgesammelt. Was uebrigens der Grund war, warum ich die aenderte. Das heiszt natuerlich NICHT, dass der neue Algorithmus keinen „Muell“ mehr aufsammelt. Es ist nur deutlich weniger.
Damit ist das geklaert und das gilt in dem selben Linklevelbereich mal mehr („Patchworkfamilien“) mal weniger (bei den regularen Familien … aber nicht unbedingt null) fuer alle anderen Diagramme.
Damit geht es zu den regularen Familien und da kann ich die Resultate in „Kernfamilie“ (die mit dem gleichen „Familiennamen, also die eigentliche Kette; rechtes oberes Diagramm) und „Anhaenger“ zur Kette (also Seiten die einen anderen Titel haben, aber von den eigentlichen Kernkettenseiten zitiert werden; linkes unteres Diagramm) unterteilen.
Zunaechst die „Kernfamilien“. In den 2020 Daten ist der Grund fuer den Unterschied bei (sehr) kleinen Linkleveln zwischen den roten (neuer Algorithmus) und den grauen (alter Algorithmus) Punkten ein anderer als oben erklaert (wobei Obiges mglw. auch eine kleine Rolle spielt). Vielmehr kommt der Unterschied durch eine Aenderung im Algorithmus an sich zustande, denn Ketten mit zwei oder weniger Seite werden jetzt „rausgeschmissen“. Und tatsaechlich, wenn ich eine Stichprobe bei LL5 mache (das Maximum in der Linkfrequenz ist also NACH LL5), dann finde ich urst viele aussortierte Zwei-Seiten-Ketten mit dem gleichen „Familiennamen“. Ich hab das jetzt nicht nachgezaehlt, aber mein Bauchgefuehl sagt mir, dass das schon hinhaut.
Der selbe Prozess stoppt aber nicht bei høheren Linkleveln sondern passiert immer und immer wieder genau dann, wenn die Anzahl der „Mitglieder“ einer regulaeren Familie auf zwei zusammenschrumpft. Das sieht man aber natuerlich nicht im Diagramm, weil ein Unterschied von zwei Seiten von den dicken roten Quadraten ueberdeckt wird.
Jetzt erstmal schnell zu den „Anhaengern“ in den 2020 Daten: alter und neuer Algorithmus liefern die gleichen Resultate. Unterschiede ergeben sich aus dem eben Beschriebenen: wenn eine Familie zu klein wird, wird diese nicht mehr als Familie angesehen und ihr werden damit auch keine „Anhaenger“ zugeteilt.
Jetzt die 2023 Daten (blaue Punkte). Ich erwaehnte bereits, dass dies durch eine deutliche geaenderte Datengrundlage zustande kommt. Und ich muss eigentlich auch nur die Besonderheiten der „Meshir-Kette“ betrachten, um die Form der blauen Kurve im rechten oberen und linken unteren Diagramm zu erklaeren.
Der neue Algorithmus findet zunaechst alle Seiten einer Kette. Danach werden regulaere Familien daran erkannt, dass die den gleichen Titel haben. Der gleiche Titel wird via eines Histogramms der Wørter in ALLEN Titeln der Seiten der Kette bestimmt. Die Wørter mit den meisten „Treffern“ in besagtem Histogramm werden als der „Familienname“ angesehen. Danach werden die Seiten welche ALLE Wørter des Familiennamens im Titel haben der „Kernfamilie“ zugeordnet. Alle Seiten wo das nicht der Fall ist werden als Anhaenger angesehen. Das funktioniert sehr gut bei Familien die solch eine Namensstruktur haben wie unser guter alter Bekannter, das „São-Paulo-FC-Artefakt“ (alle Titel gleich, bis auf eine Jahreszahl). Die allermeisten regularen Familien verhalten sich auch tatsaechlich so.
Bei der Meshir-Kette ist das jetzt anders. Alle Monate haben gleich viele Tage und damit (zunaechst) gleich viele Seiten in der Kette. Das heiszt, der Algorithmus erkennt, dass der Familienname (zu Recht), „Meshir“, „Tobi“, „Koiak“ und „Paremhat“ zur gleichen Zeit enthalten muss (weil diese Wørter alle gleichhaeufig vorkommen) … was natuerlich nicht geht, weswegen hier (zu Recht) eine regulaere Familie erkannt wird, aber ohne Kernfamilie sondern nur mit Anhaengern. Die Seiten der Meshir-Kette werden im obigen rechten Diagramm also zunaechst gar nicht mitgezaehlt und deswegen geht die blaue Kurve runter, weil immer mehr Kernkettenseiten „rausfallen“.
Je høher das Linklevel umso mehr Seiten fallen auch aus der Meshir-Kette raus. Wenn dann bspw. „Paremhat“ ein Mal seltener im Histogramm auftritt als „Meshir“, „Tobi“ und „Koiak“, wird „Paremhat“ als Teil des Familiennames gestrichen. Das geht immr so weiter, bis tatsaechlich NUR noch „Meshir“ den Spitzenplatz im Histogramm einnimmt und der Familienname dann NUR noch aus „Meshir“ besteht.
Wenn das von LL36 zu LL37 passiert, kann der Algorithmus pløtzlich Seiten einer Kernkette zuordnen (eben alle eigentlichen Meshir-Seiten) und es kommt zu einem Sprung in den beiden blauen Kurven. Nach oben bei der Anzahl der Kernfamilienseiten (dahin werden die Meshir-Seiten pløtzlich einsortiert) und nach unten bei den Anhaengern (denn da zaehlen die Meshir-Seiten pløtzlich nicht mehr mit dazu). Der Sprung betraegt nicht genau 30, weil die Dynamik der Kurve ja auch von anderen Seiten abhaengig ist.
Pøøøøh … was fuer ein Ritt … an der Stelle hab ich mich entschieden diesbezueglich doch noch einen dritten Artikel folgen zu lassen.
Aber das rechte untere Diagramm, die Seiten in Patchworkfamilien, muss noch kurz besprochen werden. Hier sind die roten und blauen Punkte beinahe deckungslgleich … es gibt naemlich keinen „Mesir-Fall“, die Datengrundlage ist also sehr aehnlich.
Man sieht aber einen systematischen Unterschied von einem Faktor ca. zwei bis ca. vier zum alten Algorithmus. Fuer (sehr) kleine Linklevel ist der obige Grund sicherlich wieder, dass durch die Suchparameteraenderung weniger „Muell“ eingesammelt wird.
Zunaechst wuerde ich vermuten, dass das aber nicht die Erklaerung fuer die spaetere Diskrepanz sein (denn wie gesagt, irgendwann erkennen alter und neuer Algorithmus die selbe Anzahl an Kettenseitenkandidaten). Dann sehe ich aber, dass die rote Kurve sowieso nur bis ungefaehr in den Bereich geht wo alter und neuer Algorithmus unterschiedlich viele Seiten erkennen. Mglw. ist das also doch ein Teil der Erklaerung fuer den Unterschied, zusammen mit der Tatsache, dass Zwei-Seiten-Ketten rausfliegen. Ich wuerde das als des Raetsels Løsung anerkennen … das muesste aber wer anderes genauer untersuchen.
Kurios sind in den alten Daten die (grauen) Punkte um LL42. Denn die haben einen Wert von eins … høh? „Ketten“ mit einer Seite? das geht doch gar nicht … doch doch, das geht im alten Algorithmus, denn es gibt Seiten die sich selbst zitieren und damit als „Patchworkfamilien“ (falsch) „erkannt“ werden, weil sie ja von einer potentiellen Kettenseite (eben sich selber) zitiert werden. Und das zieht sich nicht durch von kleineren Linkleveln, weil das mglw. urpsruenglich zu regulaeren Familien gehørende Seiten waren … oder sowas.
Aber das ist nun wirklich genug fuer heute.