Hohoho …da fang ich mit dem Schreiben dieses Artikels an und mir faellt auf, dass ich unerwarteterweise eine Gelegenheit gefunden habe, doch nochmal dieses Prachtexemplar zu zeigen:

*grins* … der Hintergrund ist naemlich, dass ich im weiteren Umfeld des Lernens ueber die Gravitation, auch (zwangslaeufig) ein bisschen ueber Neutronensterne und die Prozesse in welche diese involviert sind gelesen habe. Im obigen Buch sind die gar nicht so praesent, deren Existenz war zum Zeitpunkt als das Buch geschrieben wurde zwar gesichert via Beobachtungen, aber es gab noch nicht genuegend Messungen um viel draus zu machen … waren die ersten eindeutig Neutronensternen zugeordneten Beobachtungen doch grade mal 5 Jahre alt.
Genug der Vorrede und der Reihe nach. In der Schule … *ueberleg* … als ich noch zur Schule ging, habe ich mir in populaerwissenschaftlichen Buechern den folgenden „Ablauf“ der Entstehung der Elemente — Nukleosynthese — angelesen.
Im Urknall entstand aller Wasserstoff und der grøszte Teil des Heliums. Das Alles sammelte sich in Sternen und durch Fusion haben die dann Elemente bis zum Eisen „ausgebruetet“. Kerne mit høherer Protonenzahl kønnen durch Fusion nicht entstehen, weil die Bindungsenergie pro Teilchen (im Kern) fuer alles was schwerer ist als Eisen wieder abnimmt.
Hier wird’s truebe in der populaerwissenschaftlichen Literatur, denn offensichtlich gibt’s ja Elemente mit deutlich mehr als den 26 Protonen die Eisen hat. Im Wesentlichen wurde ich damals damit abgespeist, dass die in Supernovaexplosionen entstehen. Damit hab ich mich jahrzehntelang zufrieden gegeben und (zu meiner Schande) bis vor gar nicht all zu langer Zeit im Wesentlichen gedacht, dass Elemente wie bspw. Krypton dadurch entstehen, dass in einer Supernova die vorhandenen Eisen und Neon Kerne (im Falle Kryptons) wie zwei Lehmklumpen gegeneinander „geschmissen“ werden und dann einfach „zusammen backen“ (und nur durch die Kraft der Explosion genug kinetische Energie haben um die Coulombarriere zu ueberwinden.
Letzteres ist natuerlich groszer Quatsch und zu meiner „Verteidigung“ kann ich nur anfuehren, dass Nukleosynthese einfach kein Teil meines Lebens oder Studiums war. Aber Teil meines Lebens und Studiums waren ein Haufen „Bausteine“, die mir halfen das was wirklich passiert besser zu verstehen, sodass was nun folgt mein WeltUniversumsbild nur aufraeumte, aber nicht durcheinander brachte … mit einer wichtigen Ausnahme.
Aber der Reihe nach … bzw. das geht nicht in Reihe weil so viel gleichzeitig passiert und man ein bisschen hin und herspringen muss … deswegen eins nach dem anderen.
Erstens ist im Urknall nicht nur Wasserstoff und Helium entstanden, sondern auch ein bisschen Lithium und Beryllium (das wurde aber (fast) vollstaendig als „Treibstoff“ in den nuklearen Reaktionen in Sternen verbraucht). Dann hatte sich das Universum genug abgekuehlt und andere Elemente konnten nicht weiter entstehen. Das aendert aber eigtl. nix an der oben etablierten Story, denn Lithium und Beryllium spielen keine weitere grosze Rolle bei dieser Geschichte.
Dieser Prozess wird primordiale Nukleosynthese genannt und ist an sich eine super spannende Geschichte, denn das war damals mal ein SOWAS von URST KNAPPER Zeitrahmen der unsere heutige Existenz ueberhaupt erst ermøglicht. Wenn ich dran denke, dann erzaehl ich das mal an anderer Stelle.
Nun zum „Ausbrueten“ von Elemente jenseits von Wasserstoff (und Helium) in Sternen via Fusion. Wasserstoff zu (noch mehr) Helium ist gegeben. Und (drei bzw. vier) Heliumkerne zu Kohlenstoff und Sauerstoff ist auch klar.
Fuer unsere Sonne hørt es hier dann auch schon auf. Wie ueber 95 % aller Sterne in unserer Galaxis ist sie einfach nicht schwer genug um genuegend gravitativen Druck zu erzeugen um den elektrostatischen Druck der bereits vorhandenen Kerne zu ueberwinden (bzw. kommt da irgendwann auch die Quantenmechanik via Pauli’s Ausschlussprinzip ins Spiel, aber ich will’s hier ja kurz halten). Am Ende des Lebens unserer Sonne bleibt also ein Kern zurueck, der sehr viel Kohlen- und Sauerstoff enthaelt … ein weiszer Zwerg. Das alles ist natuerlich etwas komplizierter (und super spannend).
Bei schwereren Sternen erlaubt besagter gravitativer Druck (und vor allem die damit einhergehende deutlich høhere Temperatur!) im Kern die „Anlagerung“ weiterer Heliumkerne an Kohlenstoff und Sauerstoff und damit die Entstehung von Elementen bis Eisen. Elemente jenseits von Eisen kønnen in den „Hochøfen“ der Sterne aus dem oben genannten Grund mittels Fusion nicht entstehen.
… Kleine Randnotiz: so’n Stern lebt ja ’n paar Millionen Jahre. Die letzte Stufe des „Verbrennens“ von Silizium zu Eisen dauert aber nur ungefaehr einen Tag … krassomat! …
… Und dann explodiert alles und dabei entstehen Elemente mit mehr Protonen als Eisen hat. Hier muss ich aber zunaechst etwas ausholen. Deswegen spulen wir mal zurueck und lassen die Explosion noch etwas auf sich warten.
Anstelle von Anlagerung von weiteren positiv geladenen Protonen (oder Heliumkernen) kann ein Eisenkern (aber auch andere, weniger protonenreiche Kerne) naemlich neutrale … øhm … Neutronen einfangen. Das aendert natuerlich nur die Masse des Kerns, aber nicht deren Art (es bleibt also ein Eisenkern, oder ein Calciumkern, oder ein Mangankern etc. pp. … ich werde im Folgenden aber Eisen annehmen).
Ist der neue Kern mit gleich vielen Protonen aber einem extra Neutron INstabil, so zerfaellt das Extraneutron via Betazerfall in ein Proton und aus dem Eisenkern wird ein Cobaltkern.
Ist der neue Kern mit gleich vielen Protonen aber einem extra Neutron hingegen stabil, so wird frueher oder spaeter ein weiteres Neutron eingefangen. Das passiert so oft, bis ein instabler Kern entsteht.
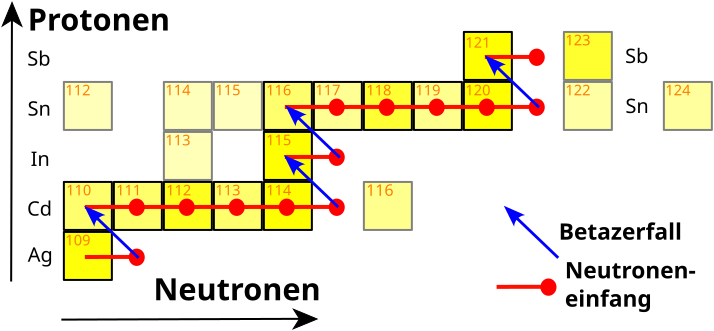
Ein Beispiel (jenseits von Eisen, ich komme darauf zurueck): 109Ag (62 Neutronen, 47 Protonen) faengt ein Neutron ein und wird zu 110Ag (63 Neutronen). Das ist instabil und zerfaellt zu 110Cd (wieder nur 62 Neutronen, jetzt aber 48 Protonen). Die naechsten vier Cadmiumkerne sind alle stabil. Bis 114Cd kommt es also zu keinem Betazerfall. Erst 115Cd (67 Neutronen) ist instabil und zerfaellt zu 115In (66 Neutronen, 49 Protonen). Das ist wieder stabil und kann ein weiteres Neutron einfangen. 116In ist aber instabil und zerfaellt zu 116Sn (immer noch 66 Neutronen, jetzt aber 50 Protonen). Und so weiter und so fort. Hier das ganze als Grafik:
Aha! Da steht ja _langsamer_ Neutroneneinfang. Gibt’s denn auch einen schnellen? Ja, gibt es, aber da bin ich noch nicht. Das oben beschriebene Beispiel ist Nukleosynthese via des s-Prozesses; „s“ fuer Slow. Langsam deswegen, weil der Betazerfall schneller vonstatten geht als ein neues Neutron eingefangen werden kønnte.
Durch diesen Prozess entstehen in alten (also leichten) Sternen Elemente bis zum Blei (Anzahl Protonen: 82). Und alt muessen die Sterne werden, denn wie’s schon im Namen steht: das ist ein langsamerwieriger Vorgang. Das war die erste Ueberraschung (wenn auch keine grosze). Ich hatte nicht genuegend Information mich nicht genuegend damit beschaeftigt um mir selbst zusammen zu reimen, dass protonenreiche Elemete auch ohne Supernova entstehen kønnen.
Nun zum r-Prozess … „r“ fuer Rapid, und schneller im Vergleich zum Betazerfall. Dafuer schalten wir unsere Sternenevolution wieder an und lassen jetzt wirklich alles explodieren. Waehrend einer Supernova sind die Neutronenfluesse derart hoch, dass nach dem Einfang eines Neutrons ein weiteres Neutron eingefangen werden kann bevor das erste eingefangene Neutron sich durch Betazerfall in ein Proton umwandelt. Das erlaubt nun ganz andere Kernprozesse.
Als Beispiel nehmen wir wieder 114Cd. Wenn das schnell hintereinander zwei Neutronen einfaengt (und dann KEINE mehr), dann wird es zu 116Cd. Der Kern ist aber stabil (bzw. EXTREMST wenig instabil, denn die Halbwertszeit liegt bei ueber 20 Trillionen Jahren) und somit wandelt der sich nicht in Indium um via Betazerfall (vielmehr springt der „nach“ den 20 Trillionen Jahren direkt via doppeltem (!) Betazerfall zu 116Sn … ein sehr unwahrscheinlicher Vorgang, weswegen 116Cd so eine lange Halbwertszeit hat).
Lange Rede kurzer Sinn: bei genuegend hohen Neutronenfluessen, wie sie bspw. in Supernovaexplosionen vorkommen, kønnen sich vor dem Betazerfall genuegend Neutronen in Eisenkernen (oder Calciumkernen, oder Mangankernen etc. pp.) sehr viele Neutronen ansammeln. Wenn der hohe Neutronfluss aufhørt ist alles wie vorher und die extrem neutronenreichen Kerne zerfallen in Kerne anderer Art mit (viel) mehr Protonen.
Zwei Anmerkungen. 1.: In einer Supernova wird deutlich mehr als die Haelfte des vorher „ausgebrueteten“ Eisens tansformiert. 2.: Nukleosynthese via des r-Prozesses in einer Supernova erlaubt die Entstehung von Elemente bis Rubidium (Protonenzahl 37). Das war dann die zweite Ueberraschung: Supernovae produzieren ja gar nicht alles ueber Eisen.
Aber es geht noch weiter … denn wenn das ausgebruetete Eisen jetzt weg ist und leichte Sterne kein Eisen ausbrueten … wo kommt denn dann das viele Eisen her. Hier kommt nun Ueberraschung #3 und wir muessen nochmal zur oben erwaehnten Sternenleiche zurueck, dem guten alten Kohlen- und Sauerstoffreichen Weiszen Zwerg. Wenn der sich naemlich in einem Binaersystem mit einem anderen Stern befindet, so kann der Zwerg Masse vom Begleiter absaugen Masse des Begleitsterns in das tiefere Gravitationspotential des weiszen Zwergs fallen. Dadurch wird Letzterer immer schwerer und wenn die Chandrasekhar-Grenze fuer stabile weisze Zwerge ueberschritten ist (wenn der also zu schwer wird) kommt es dann doch (endlich) zur Fusion der Kohlenstoff und Sauerstoffkerne zu protonenreicheren Elementen.
Ach so … das klingt jetzt alles ganz friedlich, aber das ist ein SEHR schneller Prozess, der UNHEIMLICH viel Energie freisetzt. So viel, dass es den weiszen Zwerg zerreiszt. Deswegen wird das auch als Supernova klassifiziert, aber vom Typ Ia.
Und das ist der Prozess (der Fusion und zum Teil r-Prozesse beinhaltet), der fuer den Groszteil der Nukleosynthese der Elemente um Eisen (aber nicht weiter als bis Zink) verantwortlich ist.
Das war’s aber noch nicht, denn der r-Prozess geht nur bis Rubidium und der s-Prozess nur bis Blei … Wo kommt denn dann bspw. das ganze Radon (Protonenzahl 86) her?
Und DAS, meine lieben Leserinnen und Leser, bringt mich nicht nur zu den Neutronensternen zurueck, sondern ist auch der Grund fuer diesen Artikel. Es ist die einzige Information die ich noch nicht hatte, die ich mir also nicht haette zusammenreimen kønnen mit den „Puzzlestuecken“ die mir bekannt waren.
Wieauchimmer, wir brauchen immer noch hohe Neutronenfluesse um protonenreiche Elemente via des r-Prozesses zu erschaffen. Die Neutronenfluesse einer Supernova reichen aber nicht aus. Da bleibt ja dann nur noch eine Sache im Universum uebrig die NOCH høhere Neutronenfluesse zur Folge hat: die Kollision und Verschmelzung zweier Neutronensterne. Seitdem man via Gravitationswellenastronomie solche gewaltigen Ereignisse beobachten und diese dann auch im elektromagnetischen Spektrum verfolgen kann, wird die Haelfte der Nukleosynthese aller Elemente mit mehr Protonen als Eisen solchen Neutronensternverschmelzungen zugeschrieben.
KRASS! O! MAT!
Da das aber erst seit dem historischen Ereignis GW170817 der Fall ist, fuehre ich zu meiner „Verteidigung“ an, dass ich das nun wriklich nicht wissen konnte. Zum Zeitpunkt meines Studiums wurde das sicherlich diskutiert unter Forschern die sich mit dem Thema beschaeftigten, aber das war noch nicht so etabliertes Wissen, dass es bis in meine Vorlesung (oder Buecher) geschafft haette … also ein bisschen wie die Sache mit den Neutronensternen und dem dicken schwarzen Buch ganz oben.
Zum Abschluss dann noch ein letzter Prozess der Nukleosynthese (in diesem Fall) sehr LEICHTER Kerne. Hier haben wir aber keine Anlagerung an Helium oder Wasserstoff (zusaetzliche Protonen oder Neutronen „verdampfen“ einfach von allen Kerne zwischen Helium 4He und 12C), sondern kosmische Strahlen „zerschlagen“ Elemente mit mehr Protonen (aber nicht zu vielen … also bspw. Stickstoff) in kleine Stuecke. Diese Kerzertruemmerung ist verantwortlich fuer alles Beryllium und Bor und ein klein bisschen Lithium. Das alles passiert natuerlich nicht mehr innerhalb von Sternen sondern bspw. in der Erdatmosphaere bzw. haeufiger im mit protoneneichen Elementen angereicherten Raum zwischen den Sternen.
Ach ja … radioaktive Elemente mit kurzer Halbwertszeit entstehen natuerlich auch in allen oben genannten Prozessen. Weil die aber so schnell zerfallen sehen wir die nur, wenn wir die selber herstellen (mit Ausnahmen).
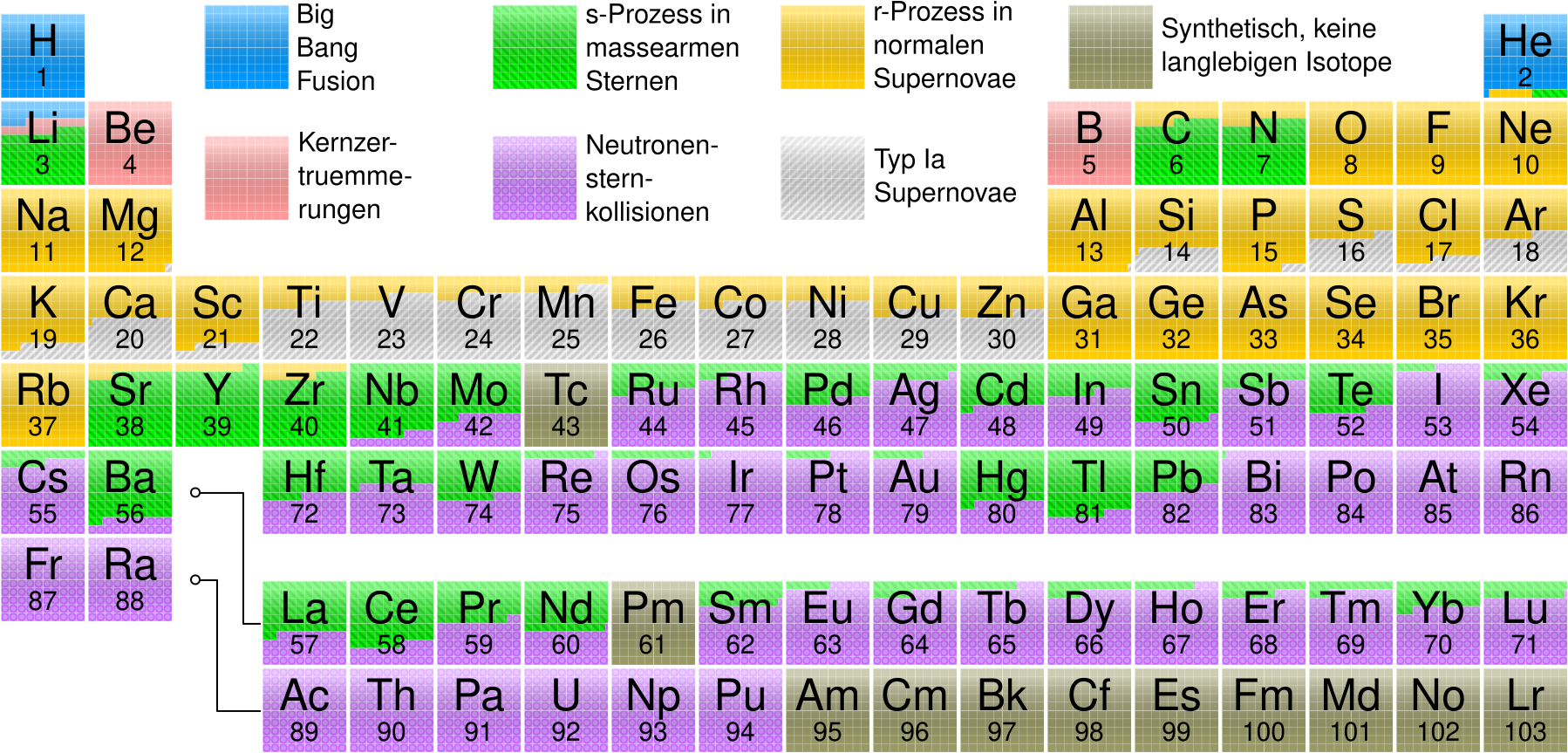
Das alles kann man in diesem, aueszerst coolen Periodensystem zusammenfassen, welches anzeigt woher das Zeuch kommt, was wir im Universum direkt (!) beobachten:
Cool wa!
Das war der ernste Artikel dieser Miniserie. Der steht im Wesentlichen fuer sich allein. Aber wie’s so oft ist, wenn man sich mal mit ’nem Thema beschaeftigt, dann taucht das pløztlich ueberall auf. Die zwei nachfolgenden Beitraege nehmen das Konzept eines Periodensystems der Elemente ein bisschen … ich sag jetzt mal: weniger streng … und vereinfachen das Ganze signifikant … tihihi