Kurze Wiederholung (weil’s immer noch etwas kompliziert ist):
i.: Alle Seiten werden am haeufigsten von „irrelevanten“ Seiten zitiert und alle Seiten reden (zitieren) am haeufigsten ueber „irrelevante“ Seiten.
ii.: Der Relevanzwert entspricht bei kleinen Werten der Anzahl der Zitierungen und ist bei grøszeren Werten eine Abbildung einer Zaehlweise mit Luecken (Anzahl der Zitierungen) auf eine Zaehlweise ohne Luecken (Relevanzwert)
iii.: Aus dem zweiten Punkt folgt (indirekt), dass die Daten bei kleinen Relevanzwerten aus (sehr sehr) vielen Seiten zusammengesetzt sind. Hingegen bei groszen Relevanzwerten wird das „Signal“ von nur wenigen Seiten generiert. Bei ganz groszen Werten gar nur von einzelnen Seiten. Dadurch entsteht der Eindruck, dass das „Signal“ in diesem Bereich nur „Rauschen“ ist.
iv.: Zeilenweise Normierung zeigte beim letzten Mal, dass im „Rauschen“ bei groszen Relevanzwerten vermutlich noch Information steckt und dass dies dort nur deswegen als „Rauschen“ scheint, wegen dem was im dritten Punkt steht.
Heute folgt nun, wie man mittels einer weiteren (ich wage zu sagen: geschickten) Abbildung die Information aus dem Rauschen „ziehen“ kann.
Es wird etwas technisch am Anfang. Aber das ist wichtig um zu verstehen, dass die qualitativen Schlussfolgerungen gueltig sind, trotz der „Artefakte“ welche besagte Abbildung hinterlaeszt.
Zunaechst muss ich zu dem im dritten Punkt Zusammengefassten zurueckkehren um zu erklaeren wie das Problem zu løsen ist. Dafuer schaue man auf diese Tabelle, welche das Problem verdeutlicht.
| So oft zitiert | Anzahl Seiten | Anzahl Zitate | Prozentanteil (Seiten) | Prozentanteil (Zitate) | kumulativer Prozentanteil (Seiten) | kumulativer Prozentanteil (Zitate) |
|---|---|---|---|---|---|---|
| 0 | 320,089 | 0 | 5.52 | 0 | 5.52 | 0 |
| 1 | 793,588 | 793,588 | 13.69 | 0.48 | 19.21 | 0.48 |
| 2 | 601,762 | 1,203,524 | 10.38 | 0.73 | 29.59 | 1.20 |
| 3 | 483,386 | 1,450,158 | 8.34 | 0.87 | 37.92 | 2.08 |
| … | … | … | … | … | … | … |
| 9 | 162,916 | 1,466,244 | 2.81 | 0.88 | 64.45 | 7.64 |
| 10 | 142,269 | 1,422,690 | 2.45 | 0.86 | 66.90 | 8.49 |
| … | … | … | … | … | … | … |
| 52 | 8,950 | 465,400 | 0.15 | 0.28 | 92.28 | 28.50(539) |
| 53 | 8,565 | 453,945 | 0.15 | 0.27 | 92.43 | 28.78 |
| 54 | 8,241 | 445,014 | 0.14 | 0.27 | 92.57 | 29.04 |
| 55 | 7,967 | 438,185 | 0.14 | 0.26 | 92.71 | 29.31 |
| … | … | … | … | … | … | … |
| 187,590 | 1 | 187,590 | 0.000017 | 0.11 | 99.99(9965507) | 99.66 |
| 231,196 | 1 | 231,196 | 0.000017 | 0.14 | 99.99(9982753) | 99.80 |
| 325,128 | 1 | 325,128 | 0.000017 | 0.20 | 100 | 100 |
In der ersten Spalte ist die Anzahl der Zitierungen welcher identisch ist mit dem Relevanzwert bis zu einem Wert von 2075. Da die Bedeutung dieser beiden Begriffe die selbe ist, benutze ich diese beiden synonym an dieser Stelle.
In der zweiten Spalte sieht man die Anzahl der Seiten die so oft zitiert wurden wie in der ersten Spalte angegeben. In der vierten Spalte steht dann wie vielen Seiten das prozentual entspricht und der aufaddierte Anteil an Seiten ist in der sechsten Spalte zu sehen.
Das Produkt aus der ersten und zweiten Spalte ergibt die Anzahl der Zitate, die diese Gruppe auf sich vereint (dritte Spalte). Der entsprechende Prozentanteil (an der Summe aller Zitate) ist in der fuenften Spalte und der kumulative Anteil in der siebten Spalte zu sehen.
Die prozentualen Anteile verdeutlichen das Problem ganz gut. Bei kleinen Relevanzwerten befinden sich im Gesamtsignal deutlich mehr „Treffer“ (ausgedrueckt durch den Prozentanteil der Zitate) als bei groszen Relevanzwerten. Das ist das was ich mit ungleicher Schrittweite meine und das aendert sich auch nicht durch eine Normierung. Das Problem kønnte entsprechend durch eine gleiche Schrittweite geløst werden und da kommen die Prozentanteile ins Spiel. Es ist naemlich so, dass dieser Wert bei den Zitaten (anders als bei den Seiten) niemals grøszer als 1 wird und der Unterschied von „Schritt zu Schritt“ auch nicht so grosz ist. Vielmehr ist es so, dass der Unterschied mit grøszeren Relevanzwerten abnimmt. Das ist toll, denn bedeutet dies doch, dass ich die Daten von mehreren Relevanzwerten zusammenfassen kann um „Meta-Gruppen“ zu erstellen, die alle eine mehr oder weniger gleiche Schrittweite und damit „Signalstaerke“ haben. Das „mehr oder weniger“ wird nochmal wichtig.
Zur Veranschaulichung nehme man die Werte bei 52, 53, 54 und 55 Zitierungen. Wenn ich diese vier Zeilen zusammenfasse, erhalte ich die „Meta-Gruppe“ mit dem Namen 29. Der Name kommt daher, dass alle diese Werte beim kumulativen Prozentanteil (der Zitate) auf 29 % gerundet werden.
Bei kleinen Relevanzwerten bis 8 entspricht auch hier wieder der Name der „Meta-Gruppe“ der Anzahl der Zitierungen. Aber bereits ab 9 Zitierungen muss ich anfangen Zeilen zusammen zu fassen.
Wie angesprochen wird nun aber das „mehr oder weniger“ nochmal wichtig.
Im Durchschnitt repraesentiert jede Meta-Gruppe ca. 1.6 Millionen Zitierungen (der Median ist aehnlich). Aber insbesondere bei den ersten Meta-Gruppen (also bei kleinen Relevanzwerten) kann diese Zahl deutlich grøszer werden.
Zur Veranschaulichung nehme man die Werte bei 9 und 10 Zitierungen. Diese „komprimieren“ zu Meta-Gruppe 8 %. Aber die Menge an Zitaten die dadurch repraesentiert wird ist mit 2,888,934 Zitaten fast doppelt so grosz wie der Durchschnitt.
DAS wiederum fuehrt im (normierten) Falschfarbenbild zu Streifen; den oben erwaehnten Artefakten. Die Anzahl dieser „Grenzfaelle“ ist zum Glueck gering und die Artefakte aendern an der Nuetzlichkeit dieser Abbildung auf Meta-Gruppen, welche ungefaehr gleich grosze Mengen an Zitierungen repraesentieren, nichts.
Aber nun endlich die Falschfarbenbilder. Zunaechst die totalen Zahlen und die spaltenweise normierten Daten:
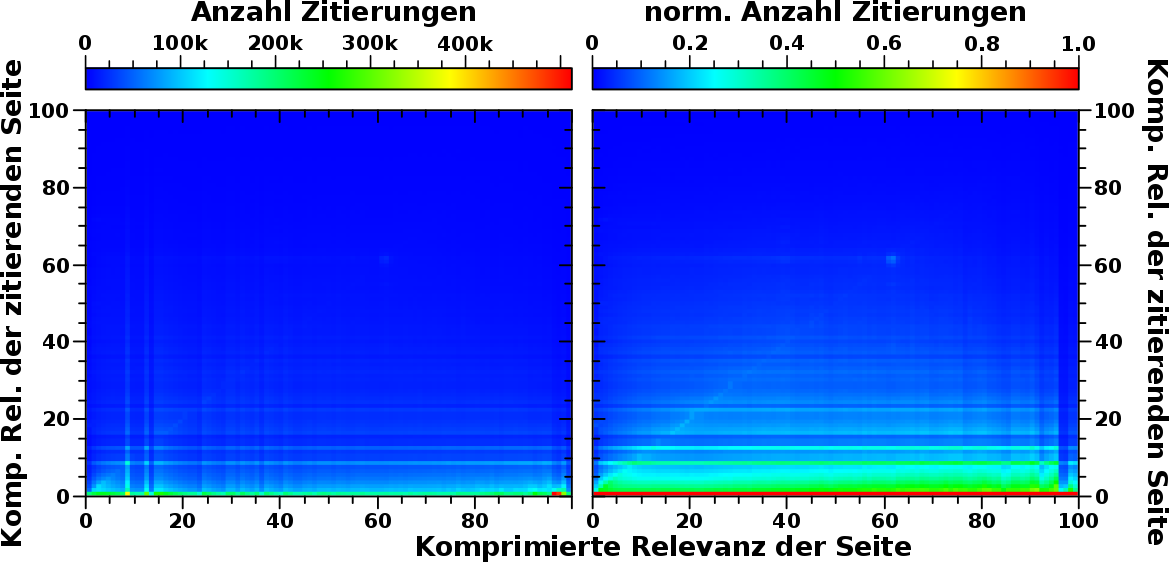
Ich habe diese beiden Darstellungen in ein Bild gepackt, weil sich keine neuen Erkentnisse ergeben. Immer noch gilt, dass die Relevanz aller Seiten durch Zitierungen von „irrelevanten“ Seiten kommt. Durch die Komprimierung sieht man es diesmal sogar schon in der totalen Anzahl der Zitierungen im linken Diagramm (gruener Streifen parallel zur Abzsisse bei kleinen Relevanzwerten). Dort sieht man ebenso rechts unten einen roten Punkt. Das liegt daran, dass die wenigen Seiten hin zum 100 % Wert so krass viele Zitate auf sich vereinen, dass dies in den (totalen) komprimierten (a.k.a. zusammengefassten) Zahlen dann deutlich auffaellt.
Auszerdem treten die erwaehnten horizontalen und vertikalen Streifen auf; besagete Artefakte. Im linken Bild sind diese Linien sowohl auf der Abzsisse als auch auf der Ordinate den selben Werten zuzuordnen. Durch die spaltenweise Normierung „verschwinden“ die vertikalen Streifen im rechten Diagramm, denn alle Spalten sind ja auf den selben maximalen Wert normiert.
Das soll genug sein fuer heute. Dieser Beitrag sollte vor allem das Prinzip der Komprimierung der Daten klar machen und was das fuer die Resultate bedeutet. Beim naechsten Mal zeige ich dann die zeilenweise normierten Daten und da gibt es einiges zu diskutieren.
Leave a Reply