Weihnachtsbeitrag! Das passt gut, denn ich habe ziemlich viel Aufwand reingesteckt, um die hier vorgestellte Sache zu „entschluesseln“. Deswegen wird dieser Beitrag relativ lang.
Wie beim beim vorletzten Mal erwaehnt, wendete ich fuer die Erforschung des Blobs die gleiche Methodik an wie bei der Erforschung der Anomalie vom letzten Mal. Nur nicht fuer nur eine Seite sondern tausende (ganz zum Anfang) bzw. hunderte (nachdem das Problem eingegrenzt war).
Genug der Vorrede, los geht’s.
Der beim vorletzten Mal erkannte Blob, bei (61, 61) in der komprimierten Darstellung, stellte sich NICHT als Artefakt der Komprimierung heraus sondern als eine echte Anomalie. Wie erwaehnt sieht man den auch in den nicht komprimierten und sogar NICHT normalisierten Daten. Man muss nur in die entsprechende Region zoomen und den richtigen Farbkontrast einstellen … was, zugeggebenermaszen, eigentlich nur ’ne andere Art der „Normierung“ ist:
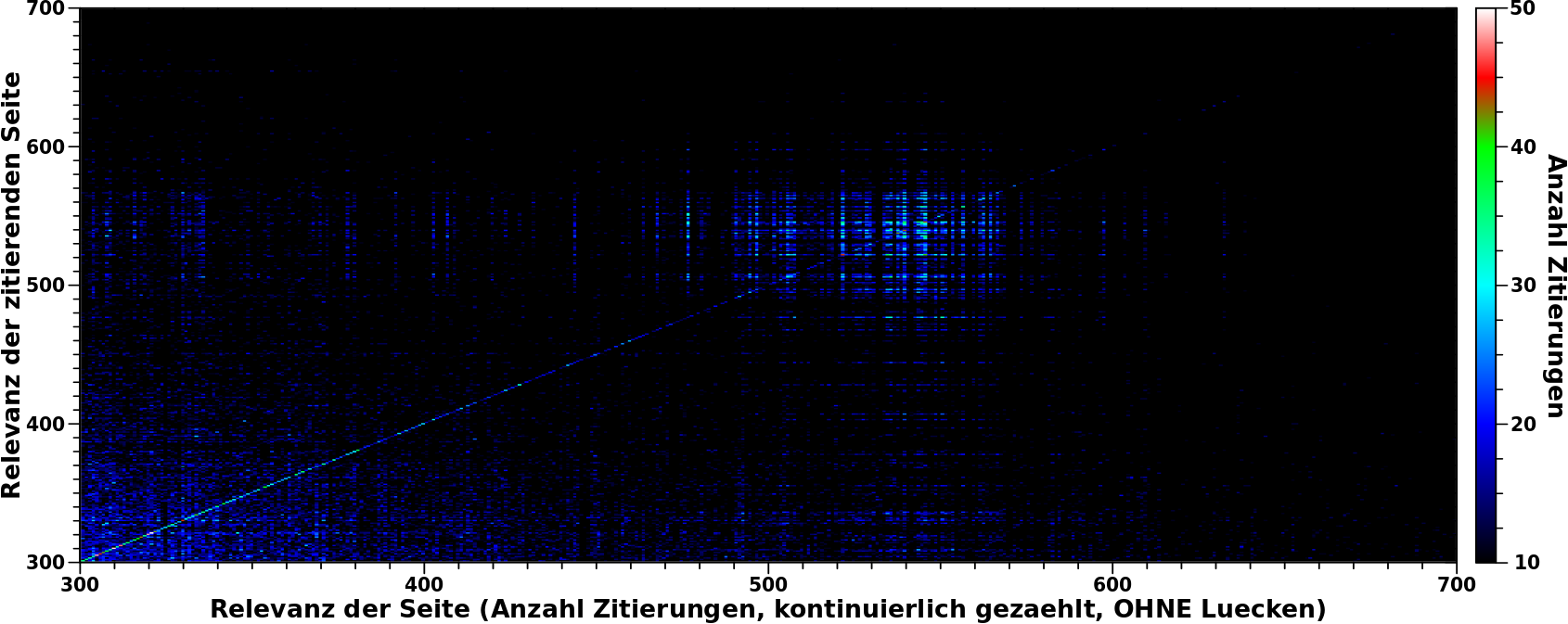
Der Blob stellt sich als „Feld“ heraus fuer Seiten die zwischen ca. 490 und ca. 570 mal zitiert worden von Seiten die ebenso oft zitiert wurden. In diesem Bereich sind Relevanzwert und Anzahl Zitierungen noch identisch.
Das Anomaliefeld ist nicht homogen; es finden sich dunkle Streifen dazwischen. Das bedeutet, dass viele Seiten welche in diesen generellen Relevanzbereich fallen, NICHT ueberproportional haeufig von Seiten aus dem selben Relevanzbereich zitiert werden.
Desweiteren sieht man links und unter dem Anomaliefeld hellere Streifen. Die erklaere ich weiter unten.
Man beachte weiterhin, dass die Farbskala in diesem Bild erst bei 10 Zitierungen „los geht“ und (wie oben erwaehnt) nicht normiert ist. Im Bild ist also nur der _Ueberschuss_ uber den „Untergrundzitierungen“ zu sehen. Das wird etwas anschaulicher, wenn man das linke Diagramm in diesem Bild mit in Betracht zieht:
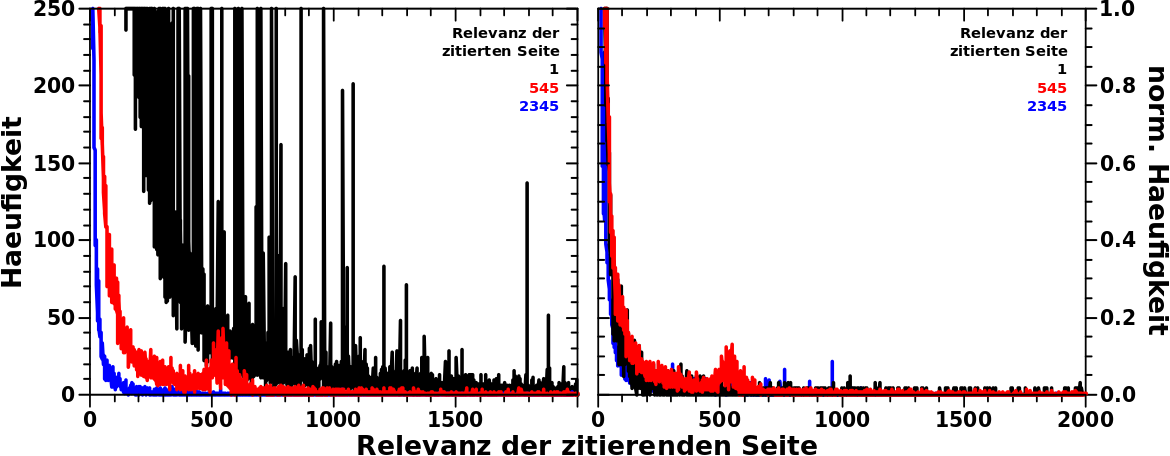
Hier habe ich vertikale „Schnitte“ durch das (komplette) Datenfeld bei den angegebenen Relevanzwerten gemacht. Die schwarze Kurve bspw. beinhaltet die Daten fuer ALLE Seiten die ein mal zitiert wurden. Auf der Ordinate wird nun gezaehlt, wie oft derartige Seiten zitiert wurden, von Seiten mit einem Relevanzwert, der auf der Abszisse gegeben ist.
Nur einmal zitierte Seiten gibt es viele und deswegen sind die absoluten Haeufigkeitswerte dieser schwarzen Kurve durchweg so hoch. Im normierten Diagramm auf der rechten Seite relativiert sich das.
Wie wir aus vorhergehenden Betrachtungen wissen, kommen die meisten Zitierungen von Seiten mit kleinen Relevanzwerten. Deswegen „divergiert“ die Kurve wenn man sich der Null auf der Abzsisse naehert bzw. wird sehr schnell sehr flach sobald man von kleinen Relevanzwerten weg ist. Wiederum, verweise ich auf das normierte Diagramm diesbezueglich bzw. sieht man das an nicht normierten Daten auch an den beiden anderen Kurven.
Von Interesse ist nun die rote Kurve, denn diese geht durch das Anomaliefeld. Diese Kurve umfasst ALLE Seiten die 545 mal zitiert wurden. Deswegen ist das Integral unter der Kurve auch (deutlich) grøszer als 545. Jede einzelne Seite die zu diesen aggregierten Daten beitraegt, wird aber nur 545 mal zitiert. Fuer die dargestellte Kurve werden diese Daten aufsummiert und deswegen ergeben sich grøszere Werte als 545.
Die allermeisten dieser 545 mal zitierten Seiten sind ganz normal und verhalten sich wie oben beschrieben. Aber (und hier nehme ich eins der Resultate der Analyse dieser Anomalie vorweg) ein paar dieser Seiten werden ueberproportional haeufig von Seiten zitiert die im Anomalierelevanzbereich liegen. Daher kommt der kleine „Huppel“.
Im oberen Falschfarbenbild habe ich die Farbskala so gewaehlt, dass Haeufigkeitswerte kleiner oder gleich zehn in schwarz dargestellt werden. Deswegen sieht man die Anomalie viel deutlicher. Aber wie man an diesen Beispielkurven sieht, ist das ein echtes „Signal“.
Und hierin lag die Herausforderung. In den interessanten Relevanzbereich fallen fast sechstausend Seiten. Aber vielleicht 10 Prozent davon sind interessant.
Man nehme bspw. Castration. Diese Seite wird so oft zitiert, dass sie auf der Abzsisse in den Relavanzbereich zwischen 490 und 570 faellt. Die allermeisten Zitierungen kommen von anderen Seiten mit kleinen Relevanzwerten. Im Anomaliefeld hingegen wird diese Seite nur sieben mal zitiert. Das bedeutet, dass von allen Zitierungen die „Castration“ erhaelt nur Gordon Ramsay, Aggression, Conversion therapy, Bull, Self-harm, Prostate und William II of England selbst so oft zitiert wurden, dass sie auf der Ordinate in den Anomaliebereich fallen.
Das passt gut ins allgemeine Bild, denn im Durchschnitt entfallen auf Seiten im Anomaliebereich (also mit ca. 490 bis ca. 570 Zitierungen insgesamt) nur weniger als 5 Zitierungen aus dem Anomaliefeld.
Das war der entscheidende Hinweis, wie ich die wenigen hundert Seiten welche die Anomalie ausmachen identifizieren kann: das muessen Seiten aus dem Anomaliebereich auf der Abzisse sein, die signifikant mehr als 7 Zitierungen von Seiten haben, die im Anomaliebereich auf der Ordinate liegen.
Und die „Schuldigen“ waren schnell gefunden: Datum(se) und Jahre.
Viele Jahre haben haben eine Uebersichtsseite auf der steht, was denn so passiert ist. Als Beispiel nehme man 1984. Dort sieht man, dass das Datum jeden Tages verlinkt ist. Als Beispiel nehme man June 1. Und bei den Datumsseiten sind dann wieder Links zurueck zu den Jahren.
Aha soso! Das sind nun zwar die „Schuldigen“ fuer die Anomalie, aber das erklaert zwei Dinge nicht:
1.: warum liegt der Anomaliebereich bei Relevanzwerten zwischen ca. 490 und ca. 570, und
2.: warum ist das sowohl auf der Abzsisse als auch auf der Ordinate der selbe Bereich?
Bzgl. Ersterem fand ich das Folgende heraus.
– 78 Jahresseiten (seit 1917) welche im Anomaliebereich ca. 230 – 300 Zitierungen haben, und
– 284 Datumsseiten, welche im Anomaliebereich zwischen ca. 50 und 75 Zitierungen haben.
Das ist also NICHT ausschlieszlich Zirkelzitieren an dieser Stelle. Wie kommen diese Seiten also zu bspw. 500 Zitierungen insgesamt, wenn die sich nicht nur gegenseitig zitieren?
Auf diese Frage fand ich auch eine Antwort, auch wenn diese mehr als eine Ursache hat.
Zunaechst ist es so, dass in den letzten 100 Jahren vermutlich jeden Tag irgendwas passiert ist. Das gibt den Jahresseiten (im Anomaliebreich) dann bereits ca. 350 Zitierungen. 150 bis 200 Zitierungen von woanders ist relativ leicht vorstellbar fuer die Jahresseiten. Ehrlich gesagt wundert es mich dass das nur so wenige sind, aber ich habe mal auf ein paar Seiten geschaut und bei der kleinen Stichprobe keine einzige gefunden, bei der eine Jahreszahl ein Link war. Ist vielleicht Wikipediapolitik oder so.
Das erklaert uebrigens auch die helleren Streifen links vom Anomaliefeld, aber immer noch im Anomaliebereich auf der Ordinate. Das sind dann auch wieder Jahresseiten, aber von Jahren die weniger als 490 Zitierungen auf sich vereinen. Die „Streifen“ erscheinen dann an der Stelle, wo die Datumsseiten auf der Ordinate liegen.
Das gleiche Argument nur umgekehrt geht dann auch zurueck auf die Datumsseiten. Fuer die letzten 100 Jahre ist jeden Tag was passiert. Die Datumsseiten bekommen somit also schonmal 100 „Zirkelzitierungen“. Im Schnitt kommen dann noch ca. 120 weitere Zitierungen von anderen „aelteren“ Jahresseiten hinzu. Diese liegen selber nicht im Anomaliebereich, weil wir da nur von wenigen Tagen wissen, ob was passiert ist (bspw. 1666). Aber weil’s so viele Jahre gibt und wir sogar bei etlichen Sachen aus der Antike die genauen Daten haben (bspw. Ides of March) laeppert sich das zusammen und im Schnitt bekommt dann halt jedes Datum noch besagte 120 Zitierungen von anderen Jahren auszerhalb des Anomaliebereichs.
Dann bin ich aber erst bei ca. 220 Zitierungen. Da fehlen noch ca. 300 Zitierungen. Die allermeisten davon kommen von einer Eigenheit auf Wikipedia, die mir vorher nicht bekannt war, aber die ich beim letzten Mal bereits (kurz) erwaehnte: Listen zu super speziellen Sachen. In diesem Zusammenhang bedeutet es, dass es nicht nur die normalen Jahresseiten gibt, sondern auch sehr spezifische Jahresseiten. Bspw. 2020 in professional wrestling, 1522 in literature oder 1952 in Wales. Dort stehen dann nur jeweils nur relativ wenige spezifische Datumsangaben. Die einzelnen Seiten tragen also gar nicht mal so sehr zum „Zitierungszaehler“ bei. Aber es gibt echt viele (mehr oder weniger obskure) Themen mit solchen Listen. Insgesamt habe ich fast 4000 von diesen spezifischen Jahresseiten gefunden. Und von diesen kommt die ueberwiegende Mehrheit der „fehlenden“ 300 Zitierungen (ich schaetze ca. 200 bis 250).
Diese Seiten tragen auch zu den Zitierungen fuer die Jahre bei. Der Einfluss auf die Datumsseiten ist aber (deutlich) grøszer als auf die Jahresseiten und das faellt fuer Erstere in die „150 bis 200 Zitierungen von woanders“.
Die 100 Zitierungen die noch fehlen sind von Seiten, welche eine Datumsseite (mehr oder weniger) aus Versehen zitieren. Sowas wie bspw. Kuzbass Autonomous Industrial Colony (zitiert December 22 und lohnt sich zu lesen), Dobruja Day oder Council of People’s Commissars of the Russian Soviet Federative Socialist Republic. Diese machen dann nochmal so ca. 50 bis 100 Zitierungen aus und wir sind bei ca. 490 bis 570.
Damit hat sich auch die zweite obige Frage beantwortet: das ist ein totaler Zufall, dass der Anomaliebereich symmetrisch ist auf den Achsen. Das ist nicht falsch zu verstehen. Ein „Feld mit erhøhter Intensitaet“ wuerde es allein schon durch die Jahr/Datum-Zirkelzitierungen geben. Aber nur die Zirkelzitierungen wuerde das Anomaliefeld zu ca. (350, 220) schieben.
Beide Koordinatenwerte wuerden dann gleichmaeszig um ca. 50 bis 150 erhøht werden, durch zufaellige Zitierungen von zufaelligen anderen Seiten. Damit sind wir bei ungefaehr (480, 320)
Erst der Zufall der (hohen) Anzahl der spezifischen Jahresseiten, „schiebt“ das Anomaliefeld zu ca. (530, 530). Wie erwaehnt ist zu beachten, dass der Einfluss dieser (spezifischen) Seiten auf die (allgemeinen) Jahresseiten kleiner ist als auf die (allgemeinen) Datumsseiten. Und das ist besagter Zufall, denn waere die Anzahl der spezifischen Seiten nur halb so grosz, wuerde das Anomaliefeld bei (500, 430) sein.
Uff, das war viel laenger als geplant, aber ich habe mit der Untersuchung dieser Anomalie echt viel Zeit verbracht (mehrere Wochen). Zwischendurch wollte ich schon aufgeben und das einfach nicht erwaehnen. Dann hat’s mir aber doch keine Ruhe gelassen und das Resultat wollte ich dann auch auch hier stehen haben.
Fuer die „Relevanzdiskussion“ war es auch relevant (Wortspielkasse), denn durch die „Kompromierung“ der Daten wurde Information aufgedeckt und da war es wichtig zu wissen, dass diese Anomalie genau das ist (eine Anomalie). Es war wichtig heraus zu finden, dass die Anomalie eine Kombination aus systematischen und zufaelligen, wikipediainternen (!) (und somit NICHT analysespezifischen) Ursachen ist. Ansonsten haette ich mir Sorgen gemacht bzgl. der Gueltigkeit der in vorherigen Beitraegen praesentierten Resultate und getaetigten Aussagen.
So ist das halt mit dem „Data Scienctist“ … der muss wissen wo die Blobs herkommen. Normale „Data Analysts“ haette da keine Chance ;) .
Das war’s soweit mit den „ersten“ Ergebissen. Ich muss sagen, dass ich selber ueberrascht bin, wieviel ich hier schon herausgeholt habe und ich habe noch nicht mal mit der eigentlichen Sache angefangen.
Urspruenglich dachte ich, dass das hier insgesamt vielleicht fuenf oder sechs Beitraege werden. Aber das Projekt wurde schnell grøszer … und dann noch grøszer. Und das ist ja eine der schønsten Sachen an der Wissenschaft; man entdeckt unerwartete und spannende Sachen. Aber ich bin auch froh, dass dieser Abschnitt nun (fast) abgehandelt ist.
Nun geht’s aber endlich weiter mit den eigentlichen Betrachtungen zum Linknetzwerk … bzw. muss ich erstmal wieder etwas technisch werden, bevor ich damit weiter machen kann … aber das ist ja auch mal schøn. Immer nur Ergebnisse ist ja eintønig.
Leave a Reply