Nachdem nun der Ausgangszustand praepariert ist und ich weisz wie die Entwicklung des Systems vonstatten geht, kann ich mir nun jede simulierte Seite aus Ersterem hernehmen und mit dem Wissen von Letzterem die Anzahl der Selbstreferenzen pro Linklevel berechnen. Daraus sollte mindestens qualitiativ dann wieder das herauskommen was auch gemessen wurde.
Zunaechst ein paar repraesentative Verteilungen der Selbstreferenzen, denn diese sind das direkte Resultat der Simulation:
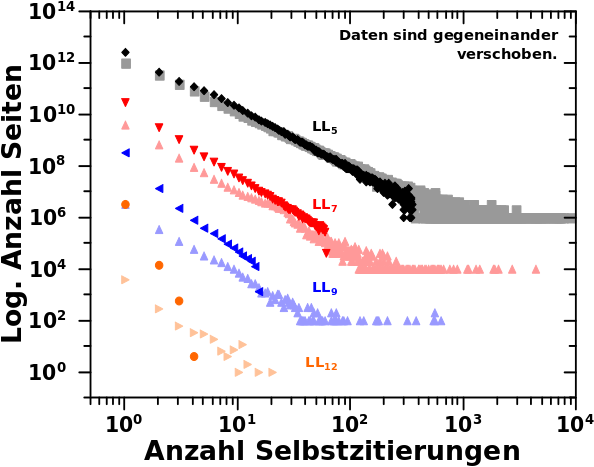
Die Daten sind fuer jedes beispielhafte Linklevel farbkodiert, wobei die schwachfarbigen Punkte die Messungen sind und die starkfarbigen Punkte die Simulation.
Die Datenpunkte fuer jedes beispielhafte Linklevel sind gegeneinander verschoben damit man besser sieht was vor sich geht.
Man sieht, dass die Simulation zunaechst ganz gut passt. Hier beispielhaft an den Daten fuer LL5 gezeigt. Das ist nicht verwunderlich, wurden die Parameter der Entwicklung doch vor allem mit Hinblick auf die ersten paar Linklevel gewaehlt.
Ziemlich schnell kommt es aber zu Diskrepanzen, die mit fortlaufender Entwicklung grøszer werden. Letzteres macht sich dadurch bemerkbar, dass sich die simulierten Punkte immer weiter von den gemessenen Punkten entfernen. Auch dies ist nicht verwunderlich, denn die realen Entwicklungsparameter werden schnell kleiner, waehrend ich sie fuer diese Simulation konstant (und auf (relativ) hohen Werten) halte.
Desweiteren faellt auf, dass der „Schwanz“ der simulierten Verteilungen „abgeschnitten“ ist. Das kommt natuerlich weil ich schon im Ausgangszustand den Sehr-viele-Selbstzitierungen-Schwanz weglasse; da kann der nicht fuer høhere Linklevel pløtzlich auftreten.
Eine weitere Sache ist der Wert fuer die Anzahl der Seiten (pro Linklevel) die nur eine Selbstzitierung aufweisen. Dieser ist eigentlich fast immer zu hoch, bei spaeteren Schritten VIEL zu hoch. Das liegt zum Einen wieder daran, weil die Entwicklungsparameter konstant bleiben; da hat dann auch eine Seite mit nur einer Selbstzitierung auf dem naechsten Level in ueber 70 Prozent der Faelle wieder eine Selbstzitierung. Der zweite Grund haengt indirekt damit zusammen, denn ich erlaube keine „(mehr oder weniger) spontanen Aussteiger“. Also Seiten deren Kette von Selbstzitierungen abbricht (egal ob es nun 23 oder nur eine waren). Die gibt es in Wirklichkeit aber und die tragen dann natuerlich nicht weiter zum gemessenen Signal bei.
Zum Abschluss ist zu sagen, dass die simulieten Daten mehr oder weniger nur bis LL12 sinnvoll sind. Danach habe ich im wesentlich nur noch einen oder zwei Datenpunkte. Auch das ist nicht verwunderlich, folgt dies doch aus dem oben Gesagten und selbst bei den gemessenen Daten sind die dort noch vorhandenen Punkte wahrscheinlich alles eher Ausnahmen, als die Regel.
Trotz Allem ist es aber wichtig zu sehen, dass dieses sehr einfache Model qualitativ gar nicht so falsch ist. Zum Einen werden die Diskrepanzen zwischen simuliertem und gemessenem Singal nicht unendlich grosz. Eine Grøszenordnung (spaeter etwas mehr) ist zwar nicht zu unterschaetzen aber liegt innerhalb dessen was ich erwarten wuerde bei einem so einfach gehaltenen Modell.
Schaut man sich nun die (vor mehreren Monaten zum ersten Mal vorgestellte) totale Anzahl an Selbstzitierungen per (relevantem) Linklevel an …
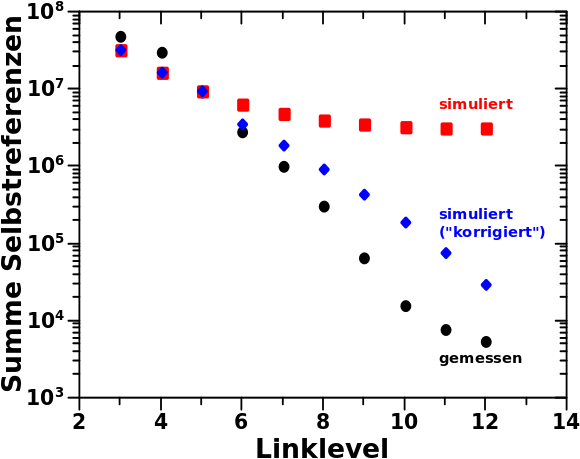
… dann sieht man beim Vergleich der schwarzen und roten Punkte, dass das auch hier Anfangs wieder ganz gut hinhaut und dann aber schnell eine grosze Diskrepanz und ganz anderes Verhalten (der Graf „biegt“ sich falsch) entsteht.
Nun erwaehnte ich aber weiter oben, dass ich zu viele Seiten mit einer Selbstreferenz habe. Wenn man diese ab LL6 (vorher zeichnet sich dieser Sachverhalt nicht als Problem ab) komplett weglasse, dann erhaelt man die blauen Punkte. Na aber Hallo! Das sieht doch viel besser aus. Die Luecke zwischen Simulation und Messung reduziert sich deutlich und nun zeigt auch die Simulation ein lineares Verhalten (bei doppellogarithmischer Darstellung). Die Luecke schlieszt sich nicht komplett und ein Unterschied von bis zu ca. einer Grøszenordnung bleibt erhalten. Letzteres war zu erwarten, wenn man das oben Besprochene bedenkt.
Alles in allem wuerde ich das aber als einen ziemlichen Erfolg der Simulation ansehen.
Ich kønnte an der Stelle aufhøren. Das waere aber unehrlich, denn eine weitere (ganz fantastische) Beobachtung waren die Regressionsparamter der individuellen Verteilungen der Selbstreferenzen pro Linklevel. Der Vergleich von Messung und Simulation dieser Grøszen sieht so aus:
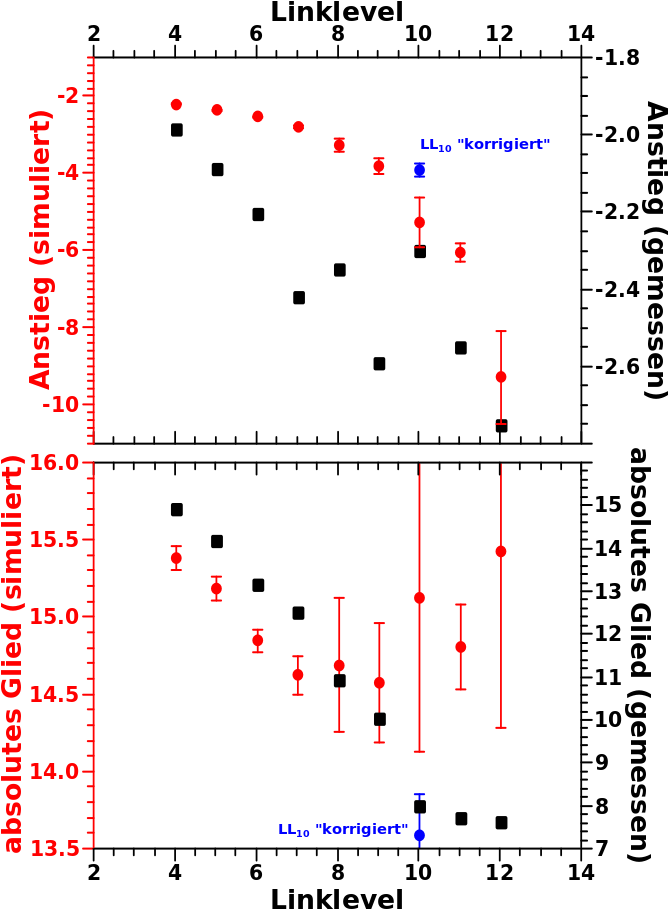
ACHTUNG: man beachte die unterschiedlichen Skalen fuer simulierte bzw. gemessene Werte!
Man sieht, dass das generelle Verhalten qualitativ reproduziert wird; die Werte sowohl des Anstiegs als auch des absoluten Glieds nehmen ab. Hurra! Ein weiterer Erfolg fuer mein einfaches Modell.
Wenn man genauer hinschaut (deswegen der Hinweis mit den unterschiedlichen Skalen) sieht man, dass bis ungefaehr LL6 die Werte fuer diese beiden Grøszen noch ganz gut uebereinstimmen. Danach wird der simulierte Anstieg allerdings VIEL zu schnell steiler und das absolute Glied nimmt viel zu langsam ab.
Dies liegt zum Einen wieder an dem oben Gesagten. Zum Zweiten liegt es daran, dass ich bei der Bestimmung der Regressionsparamter der Simulation die Daten nicht fuer die Regression „optimiert“ habe (siehe mein Kommentar diesbezueglich im zitierten Beitrag). Fuer LL10 habe ich das mal gemacht; also „unpassende“ Punkte am Anfang und am Ende der Daten weggelassen. Das Ergebniss ist der blaue Punkt in den beiden Diagrammen und der bewegt sich nicht nur in die richtige Richtung, sondern ist auch signifikant anders als wenn man diese „Korrektur“ nicht vornimmt.
Letztlich ist zu sagen, dass das Modell die Daten qualitativ gut genug beschreibt. Quantitativ allerdings gibt es Diskrepanzen von bis zu einer Grøszenordnung. Wenn man bedenkt, dass das Modell sehr einfach gehalten ist, so ist das immer noch beeindruckend. Es zeigt aber auch, dass fuer eine bessere Beschreibung weitere Effekte zu beruecksichtigen sind. Das werde ich nicht machetun … mit einer Ausnahme: ich schau mir beim naechsten Mal an, wie das Abbrechen von Linkketten pro Linklevel aussieht (oben erwaehnte „Aussteiger“). Ich habe aber nicht vor das ins Modell einzuarbeiten, denn ich bin mit den Ergebnissen zufrieden genug und habe genug Zeit damit verbracht und ehrlich gesagt auch keine Lust mehr drauf.
Leave a Reply