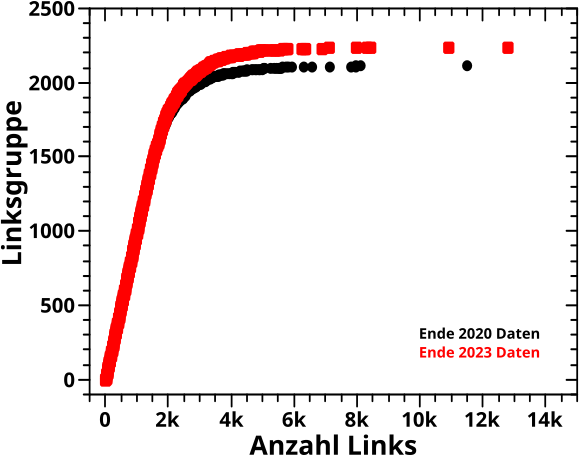
Nach den Relevanzbetrachtungen folgten damals drei Monate lang technische Beitraege auf die ich hier nicht nochmal eingehen muss. Aber danach ging es dann endlich los mit den Linknetzwerkeigenschaften und zunaechst betrachtete ich den Anstieg der Verteilung der Anzahl der (totalen) Links (und hier auch) pro Linklevel. Nur daraus folgten naemlich etliche sehr interessante Erkenntnisse und das muss ich ueber die naechsten paar Beitraege reproduzieren (ich versuche mich kurz zu halten).
Wie immer: die damals naeher betrachteten grøbsten Abweichungen schaue ich mir nicht nochmal an. Dito bzgl. der damals daran anschlieszenden Fehlerbetrachtung.
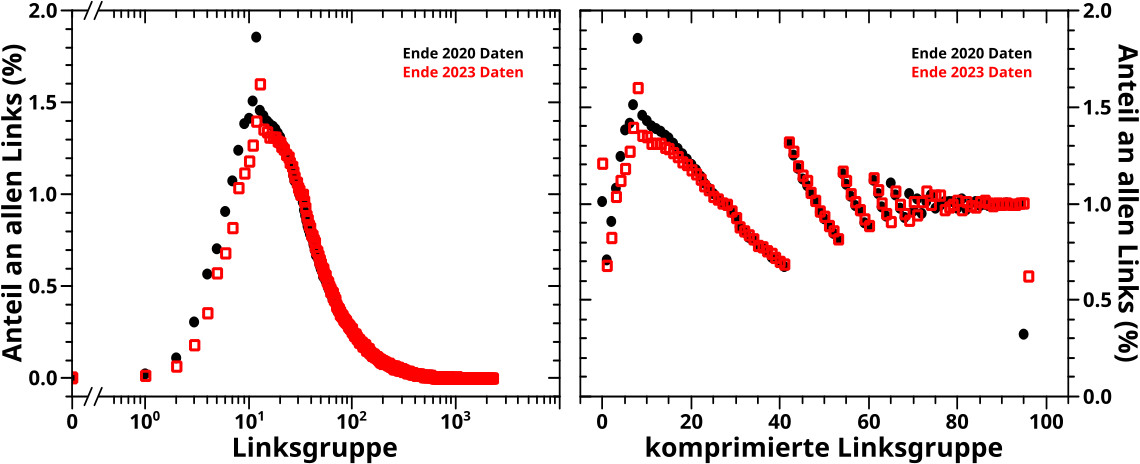
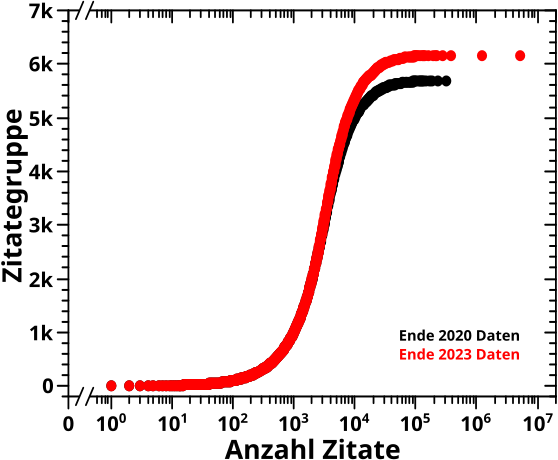
Der Anfang ist schnell gemacht, denn bei der Summe (ueber alle Seiten) der totalen Links pro Linklevel ist nicht viel passiert:
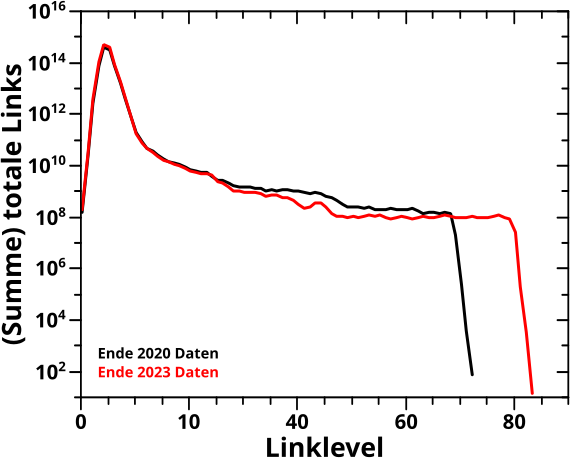
Der grøszte Unterschied liegt im Ende, das von 72 Linkleveln in den 2020 Daten zu 83 Linkleveln in den 2023 Daten gewandert ist. Ansonsten sind die Unterschiede marginal (also wie erwartet) und die Form der Kurve bleibt erhalten.
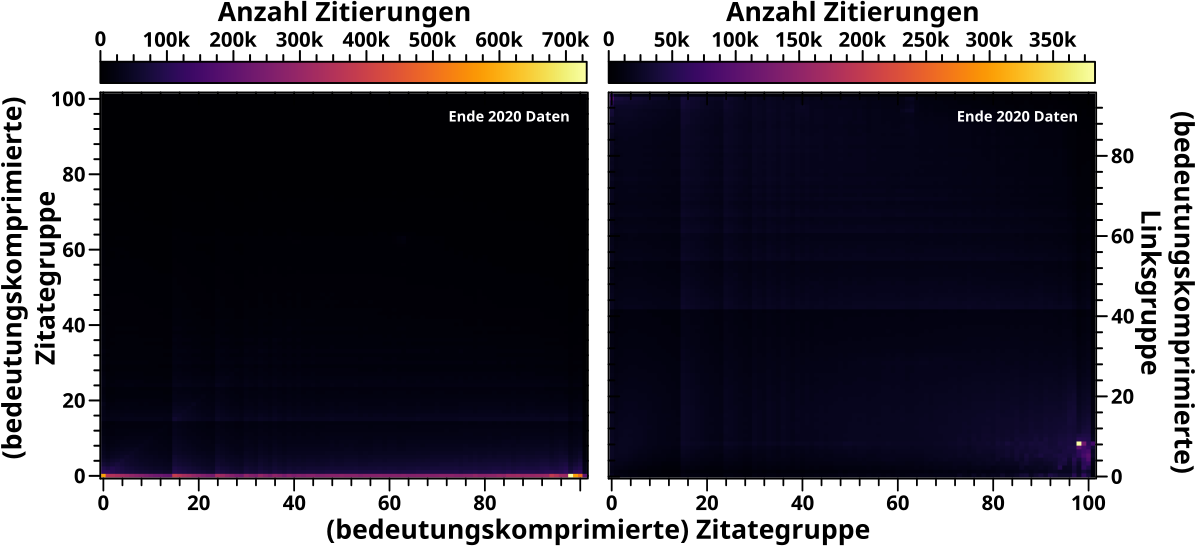
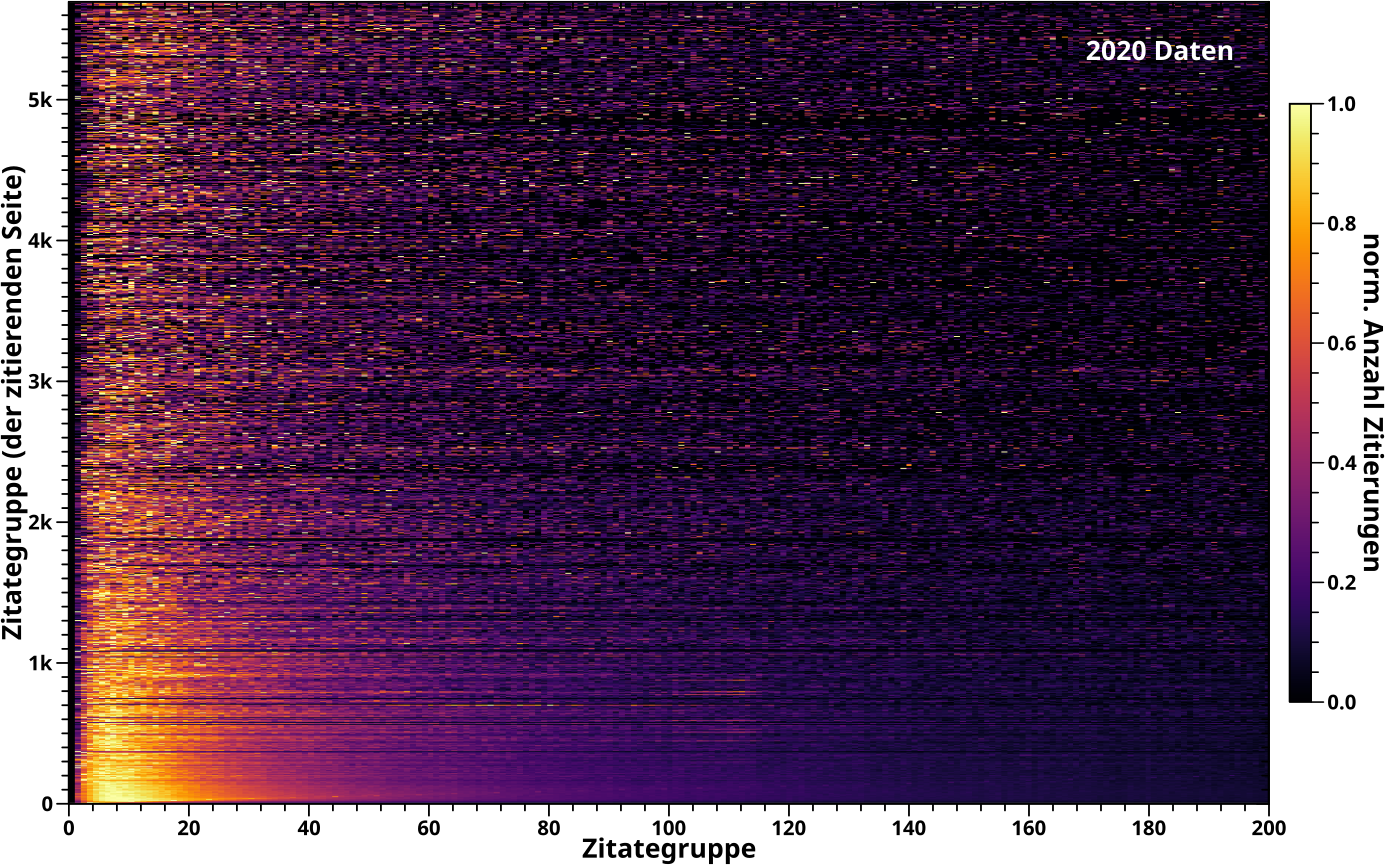
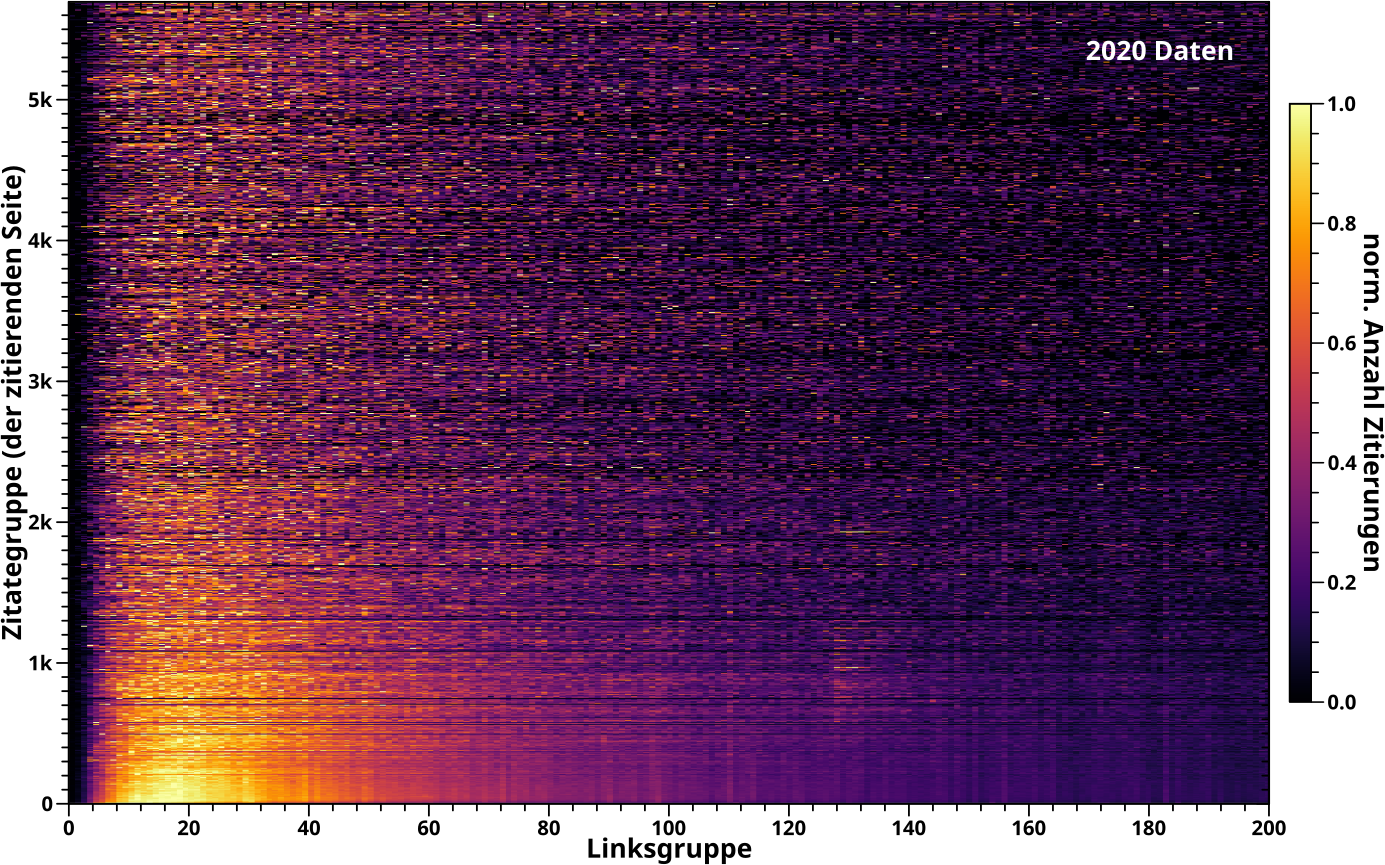
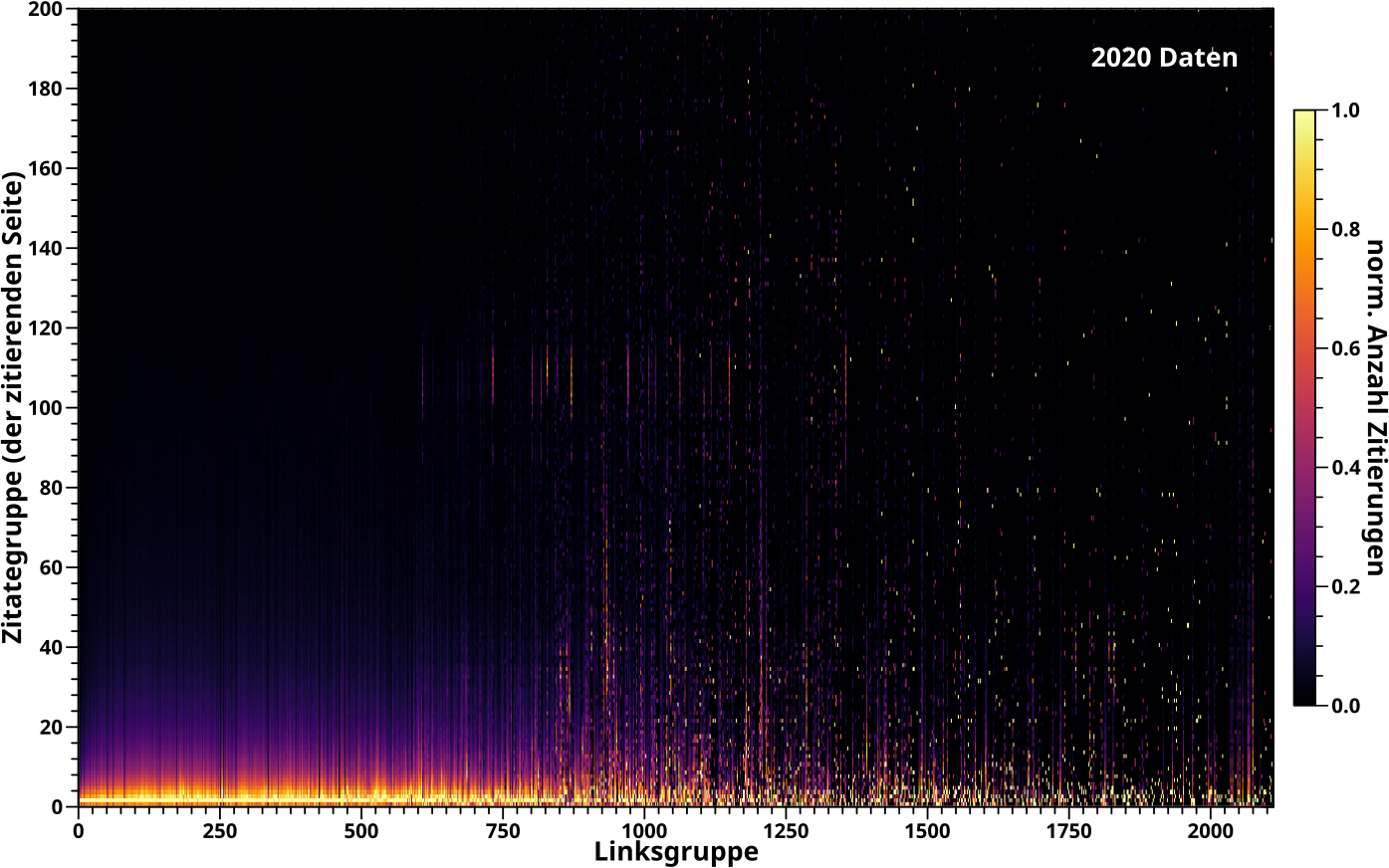
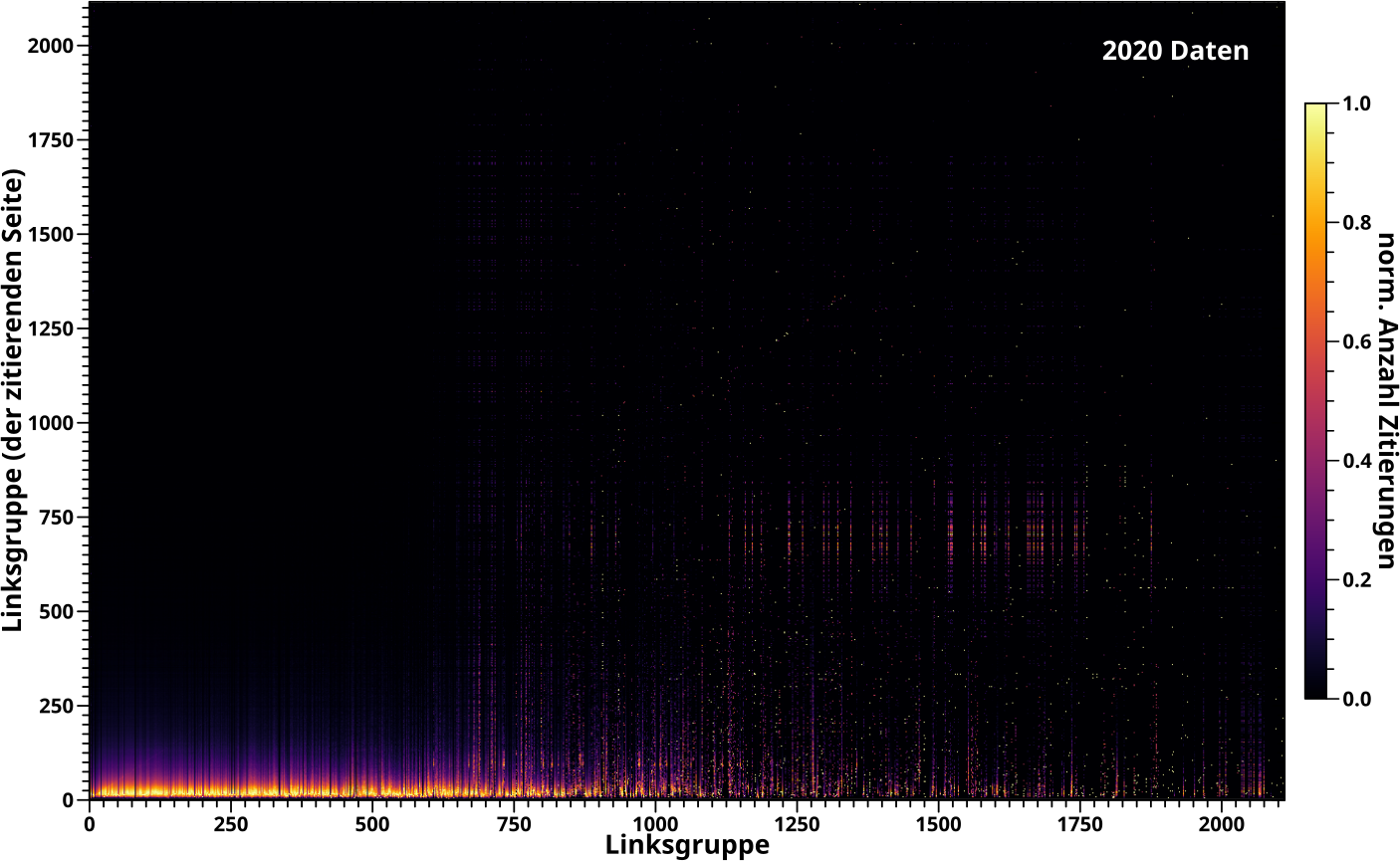
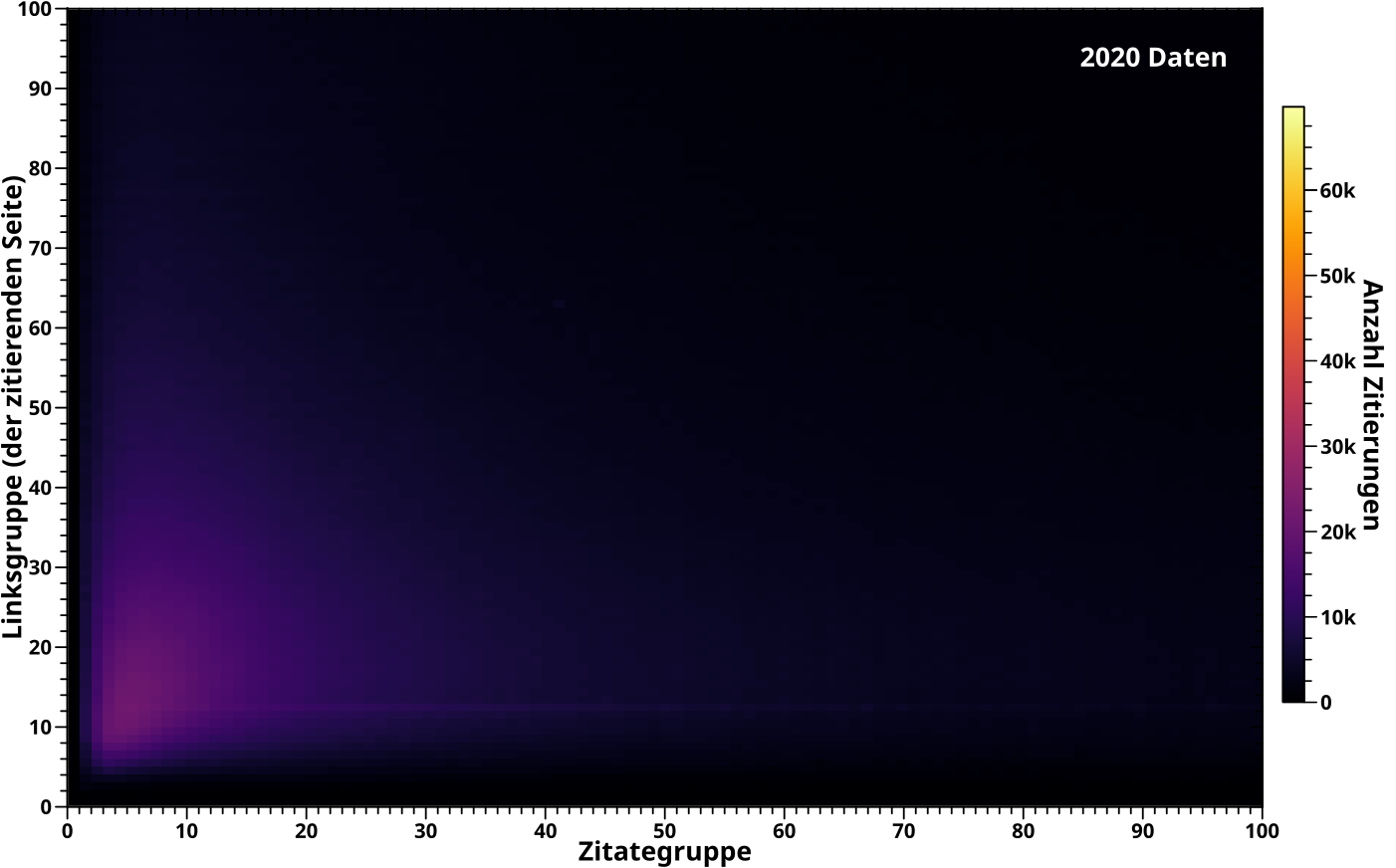
Um den starken Anstieg am Anfang zu erklaeren stellte ich mal damals die Anzahl der Links ueber der Anzahl der Zitate fuer alle Seiten dar … und erhielt einen „schwarzen Klumpen“. Hier …
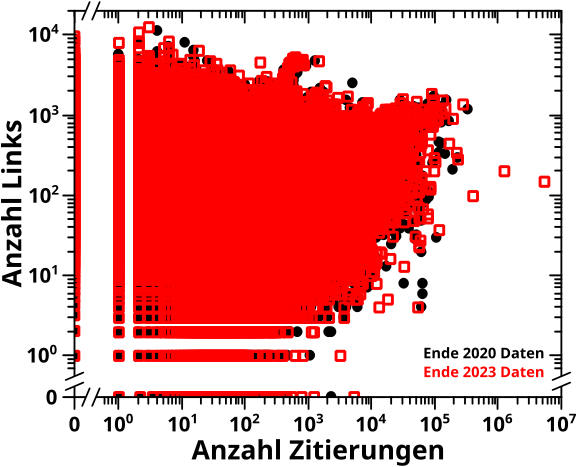
… habe ich das reproduziert und wieder gibt es keine groszen Unterschiede. Auszer im Diagramm an sich, denn damals ist mir nicht aufgefallen, dass die „Nullwerte“ (also entweder keine Zitate oder keine Links) abgeschnitten wurden. Wieder ist wichtig, dass die Form des „schwarzen Klumpens“ im Wesentlichen erhalten bleibt; sogar der kleine „Pøppel“ der oben rausschaut und insb. die „Abbruchkante“ auf der rechten Seite.
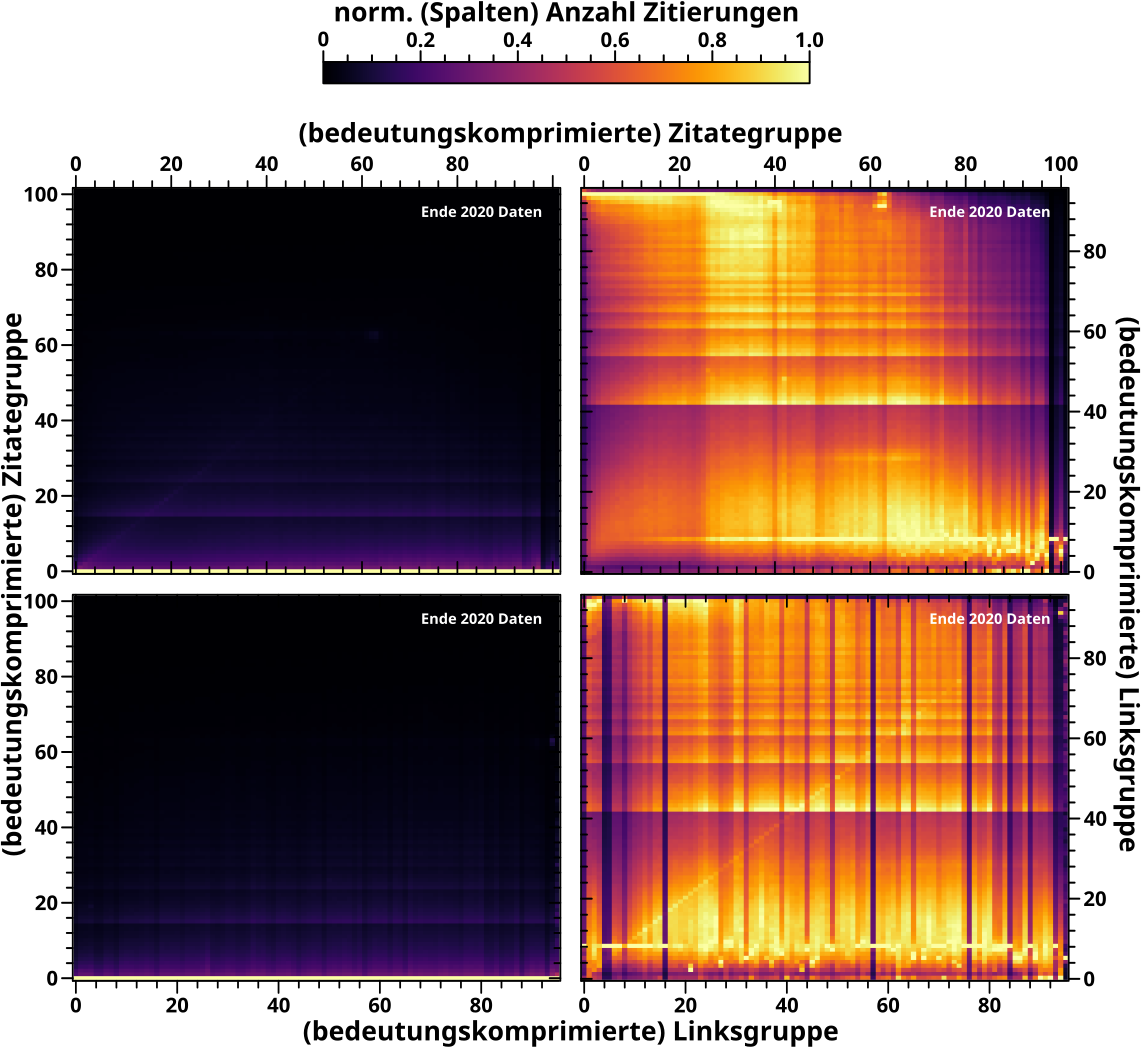
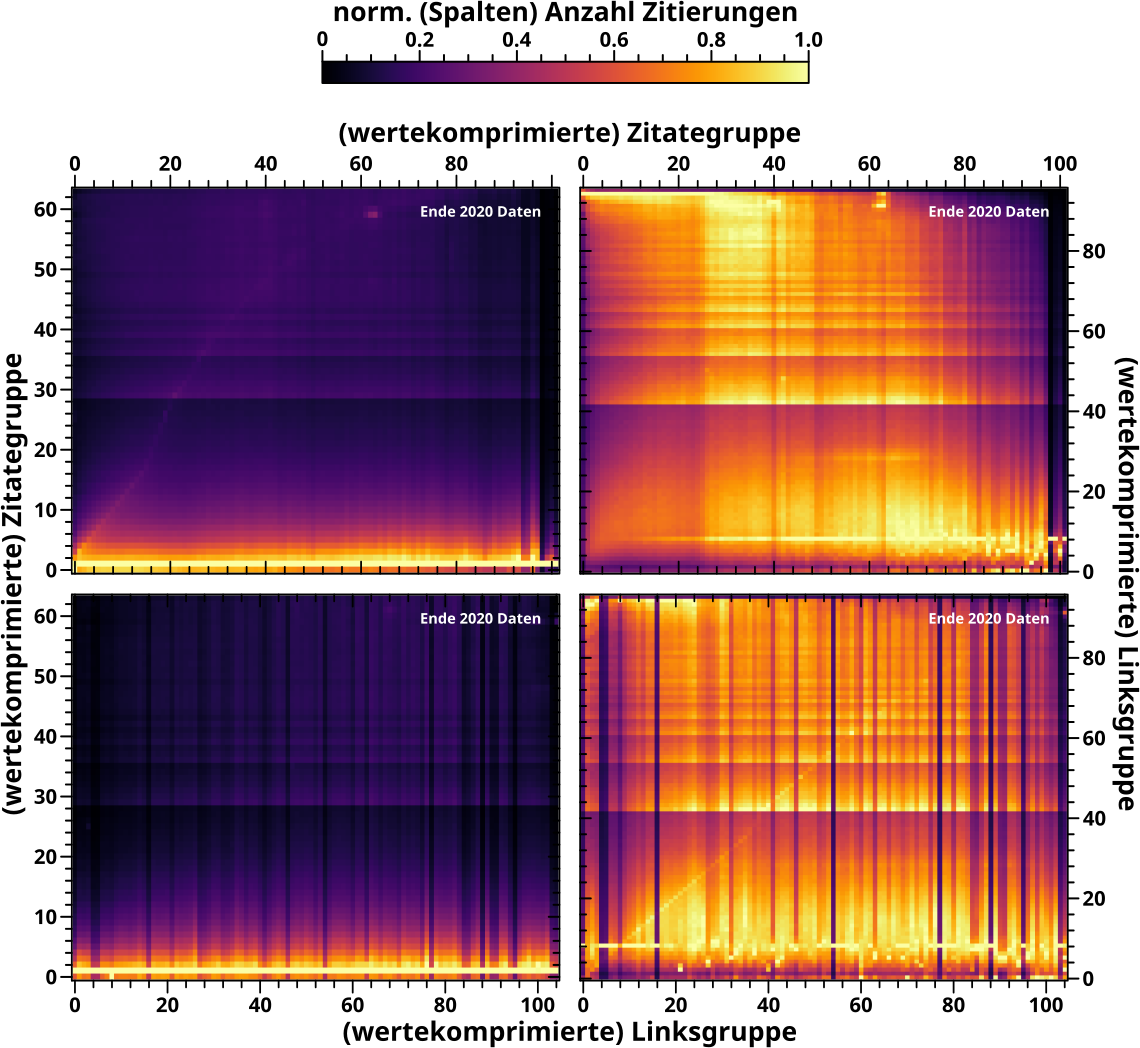
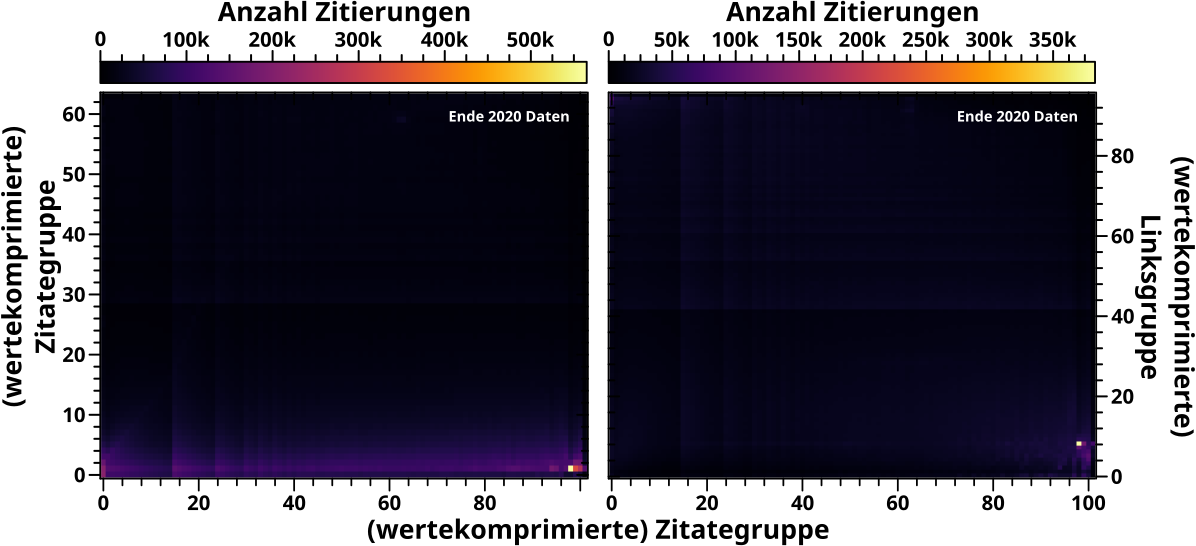
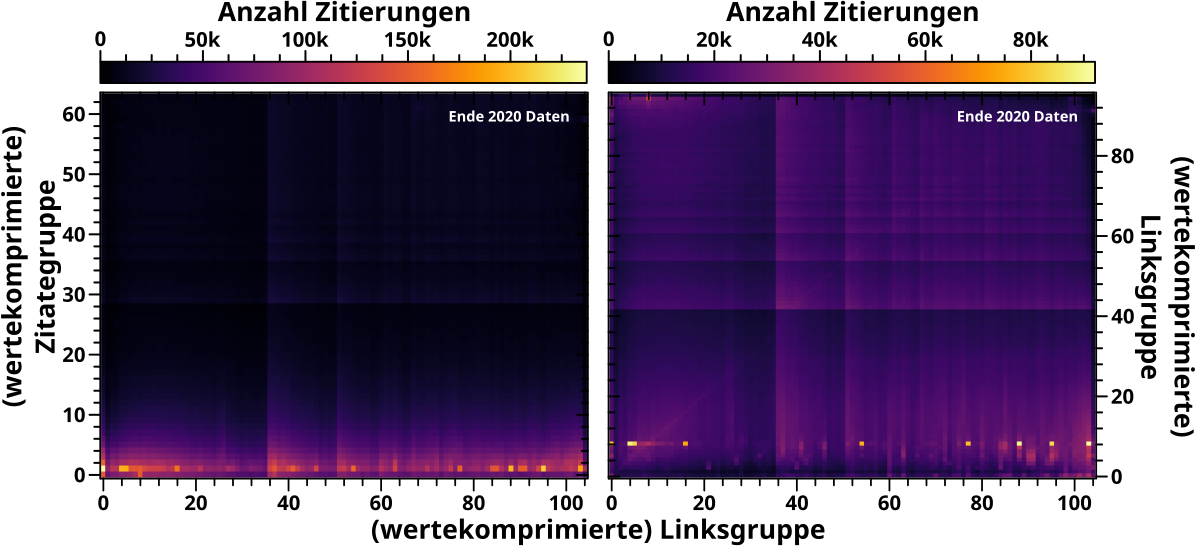
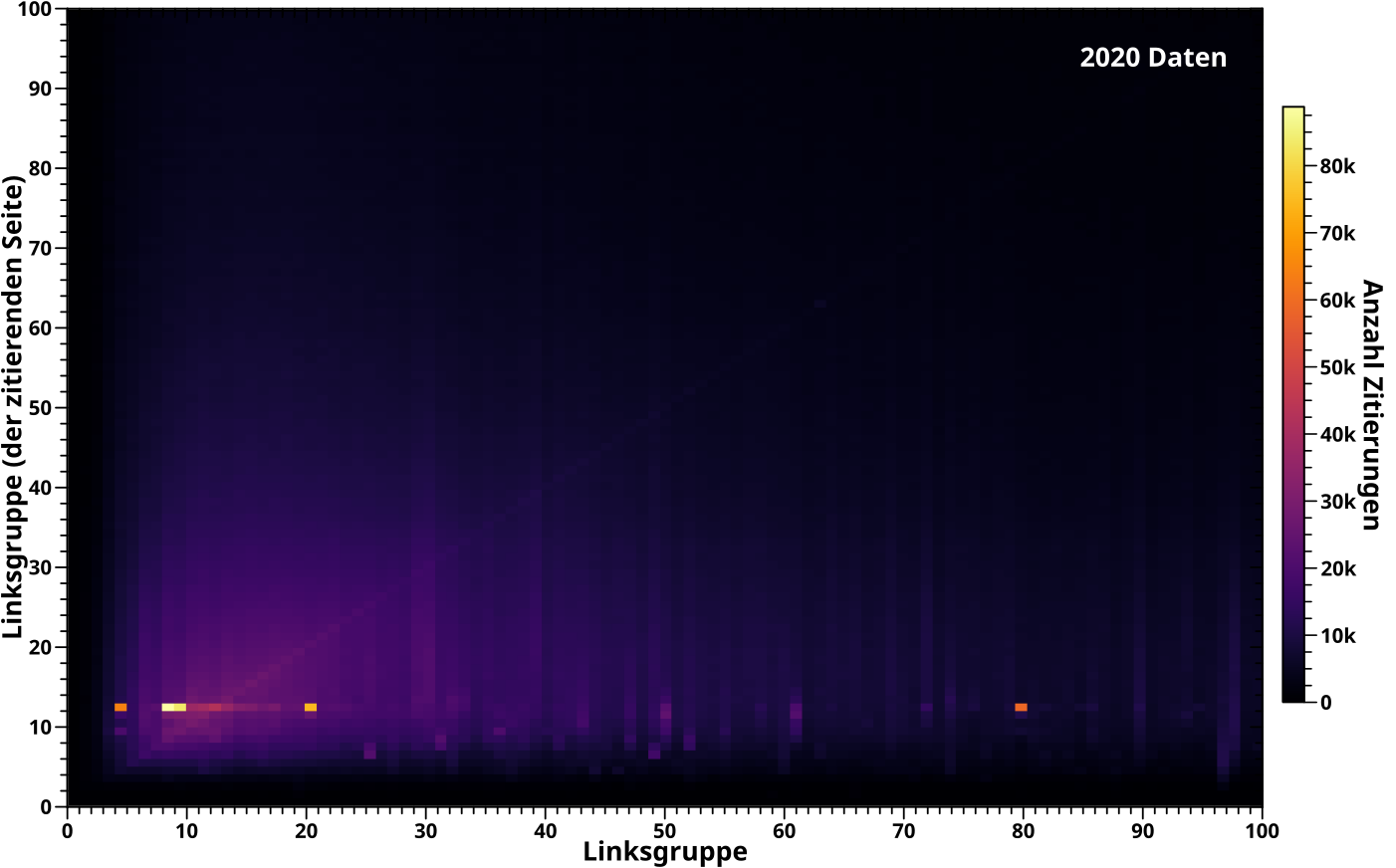
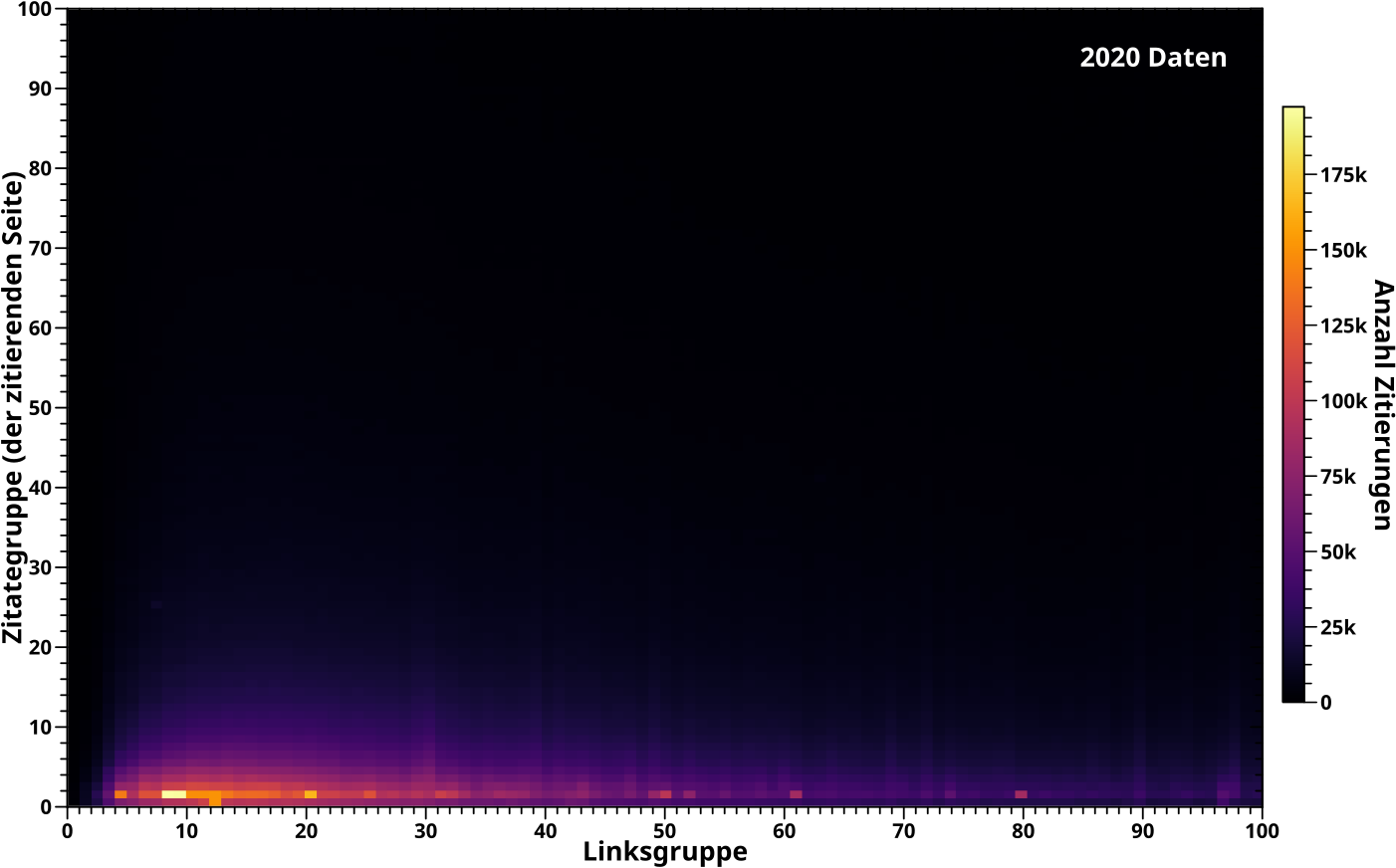
In diesem Diagramm ist eine Information versteckt, die ich damals nicht weiter betrachtet hatte: die Anzahl der Seiten mit eindeutigen Zitate-Links-Kombinationen. Ein Beispiel: man nehme an, dass es 8 Seiten gibt, die 23 Zitate und 5 Links haben. Diese 8 Seiten sind alle in nur einen einzigen Punkt gequetscht.
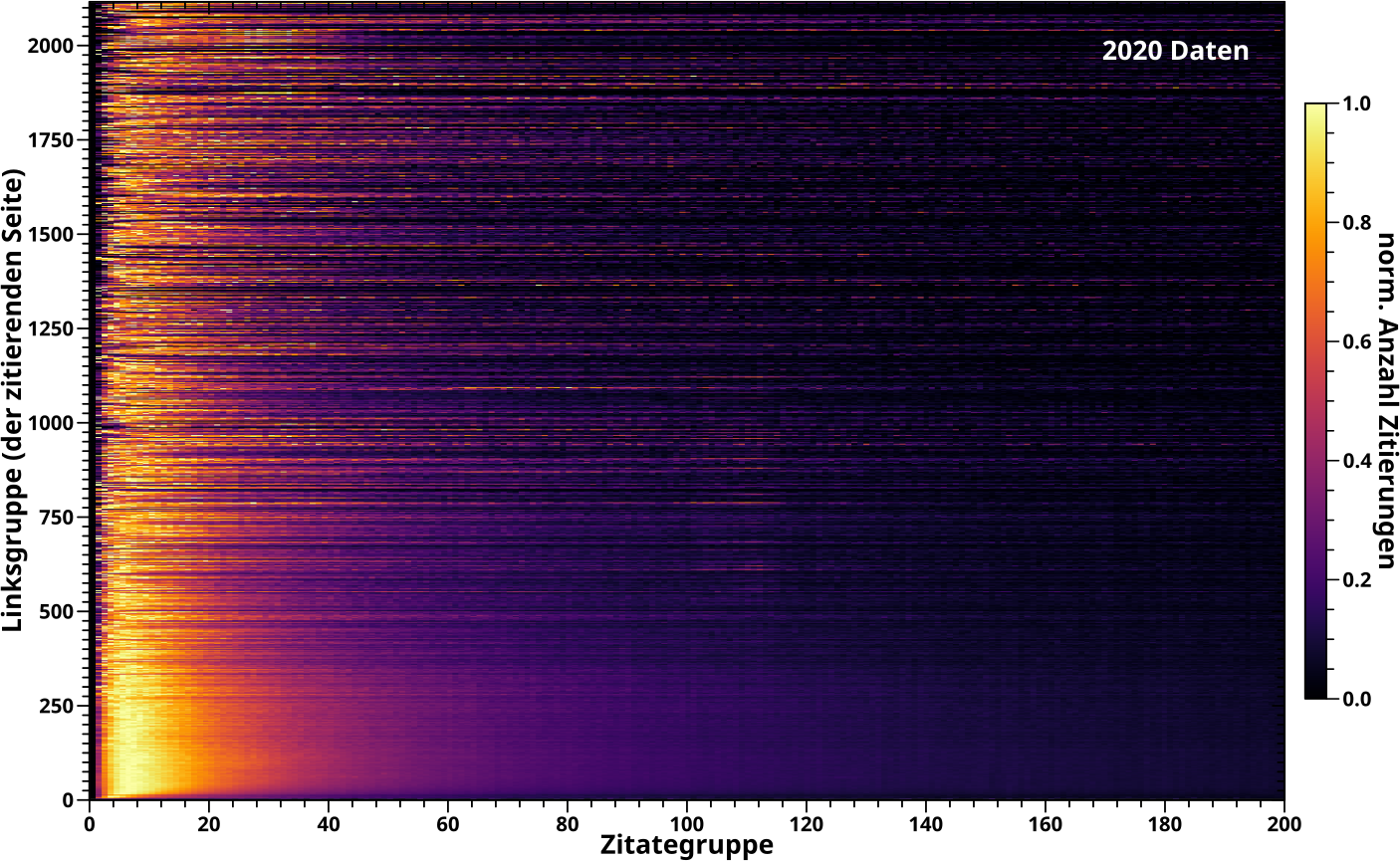
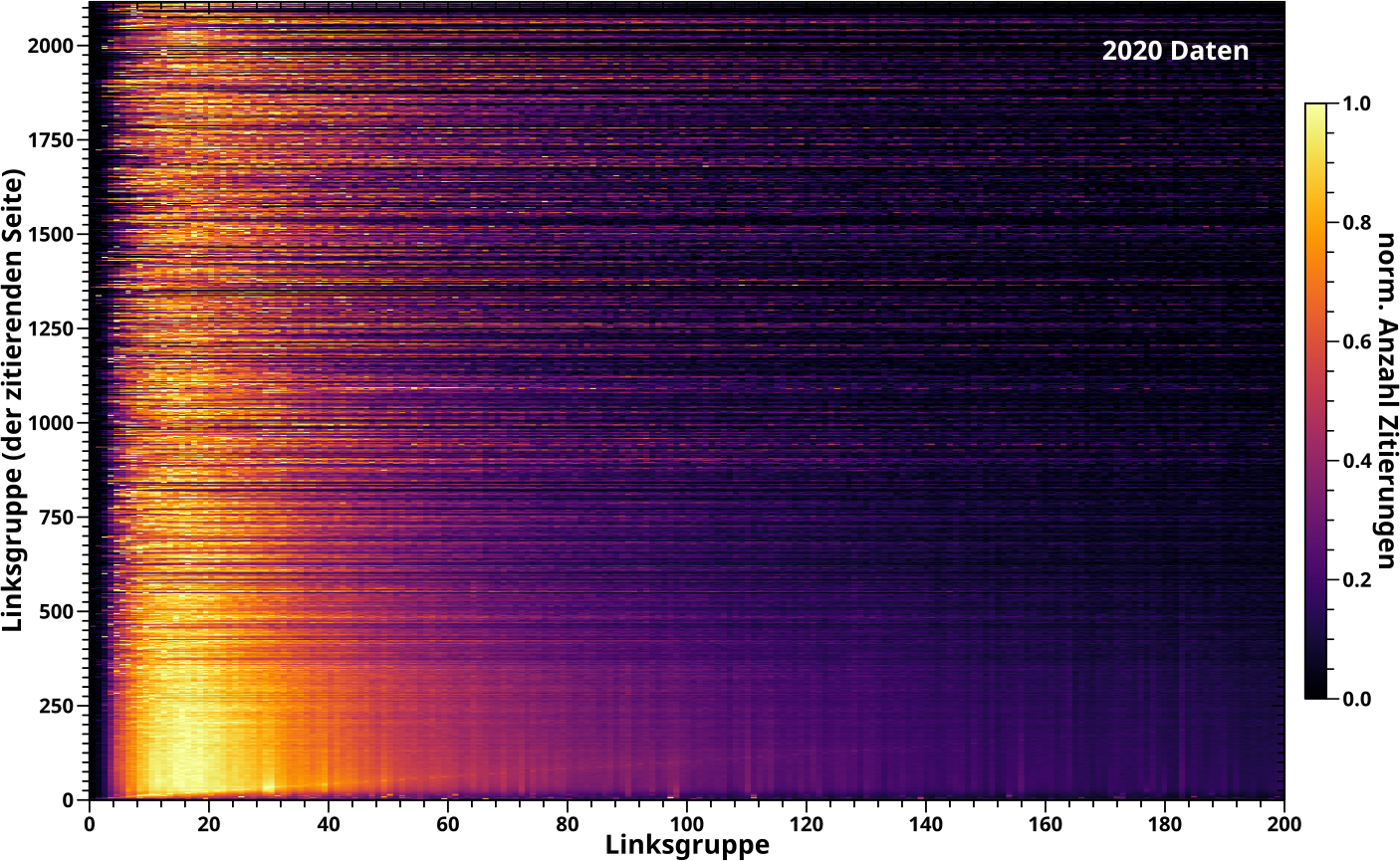
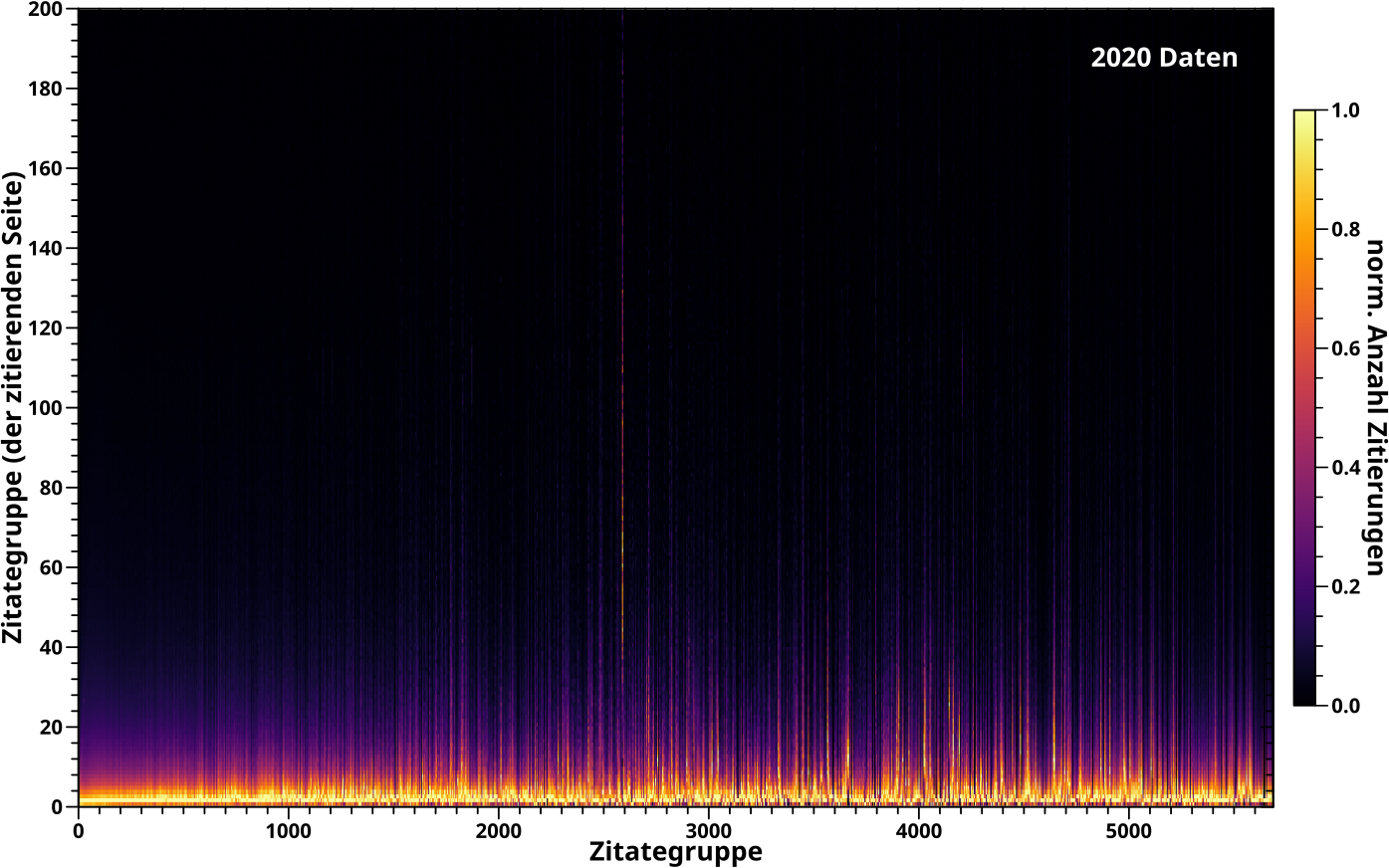
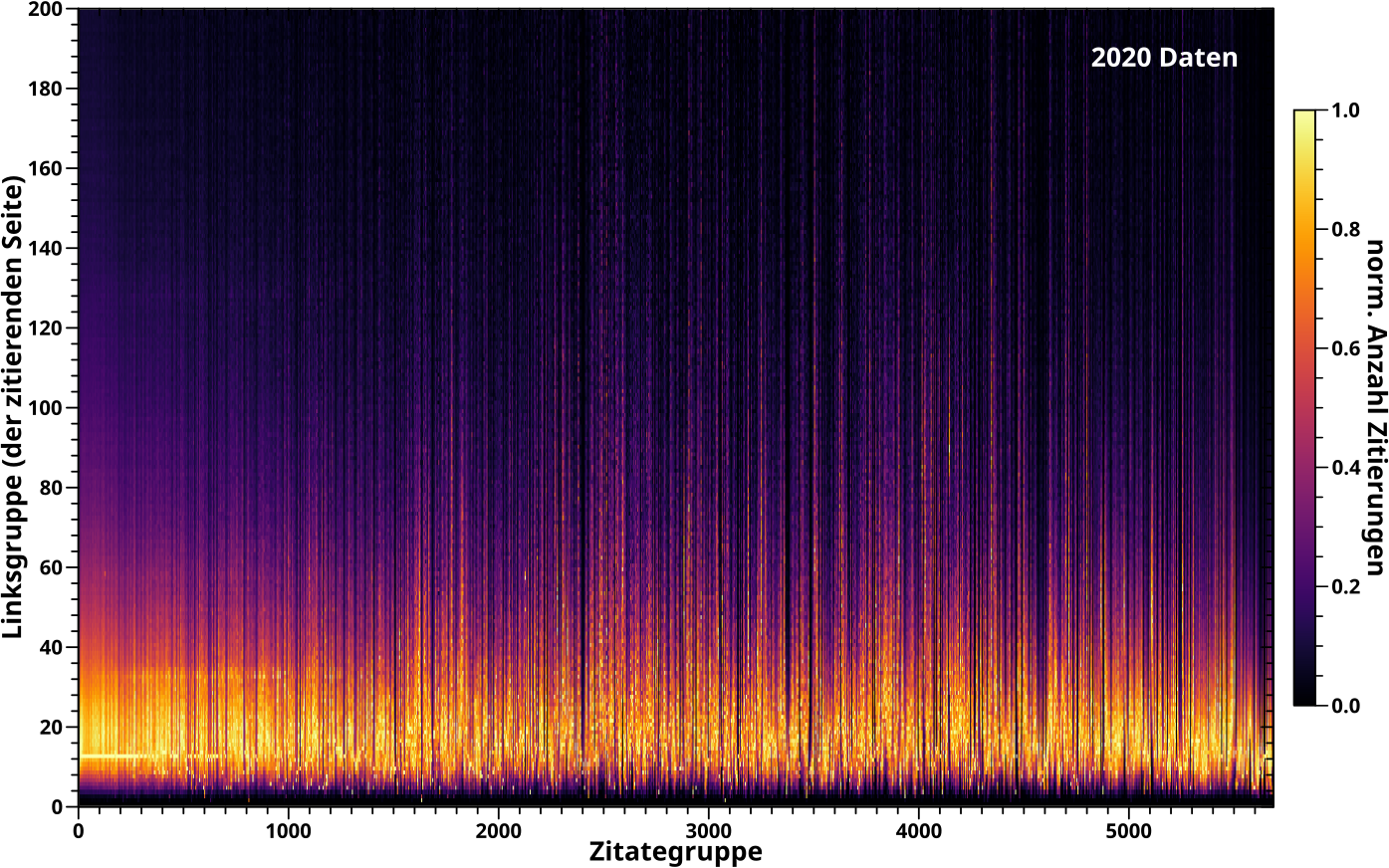
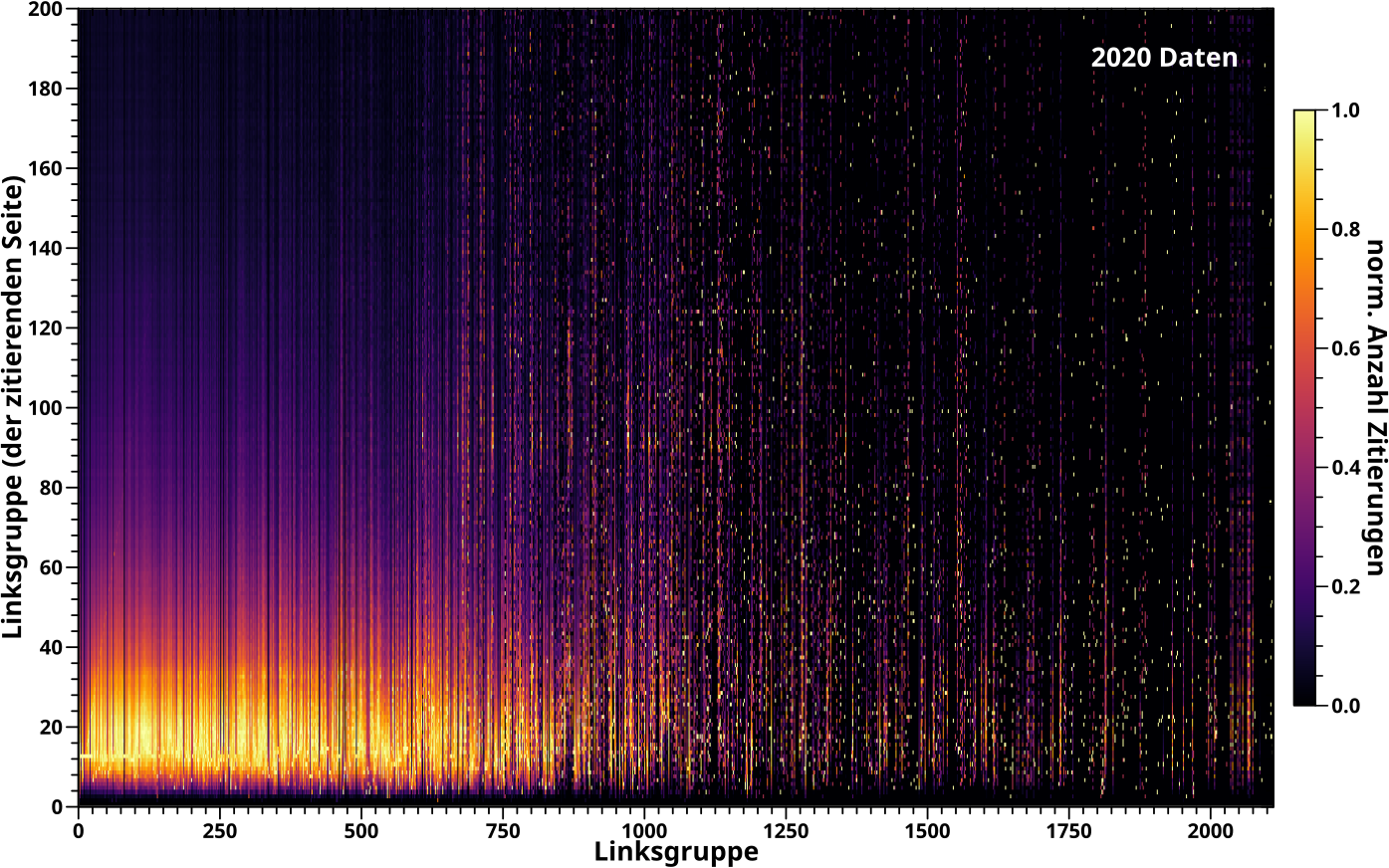
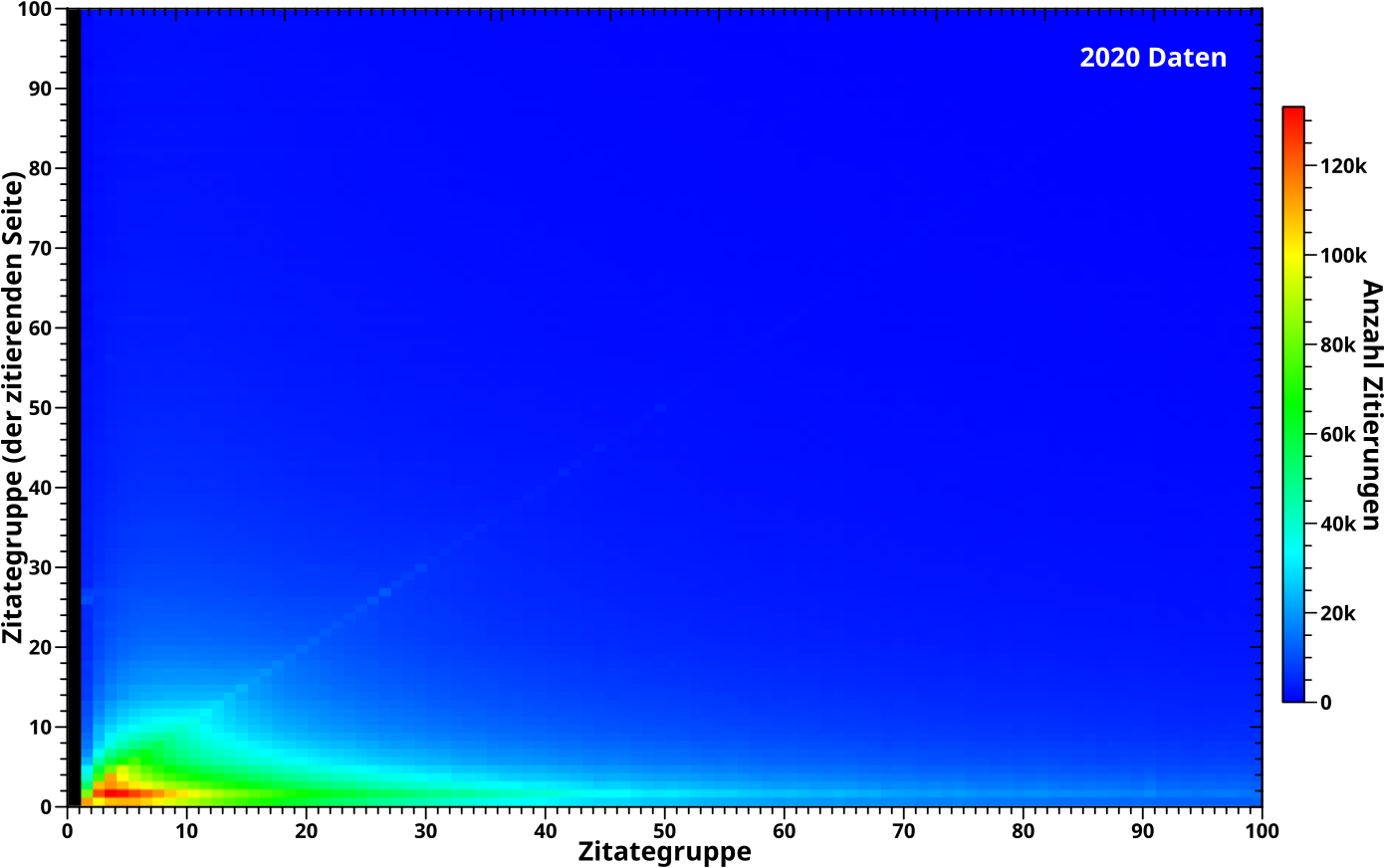
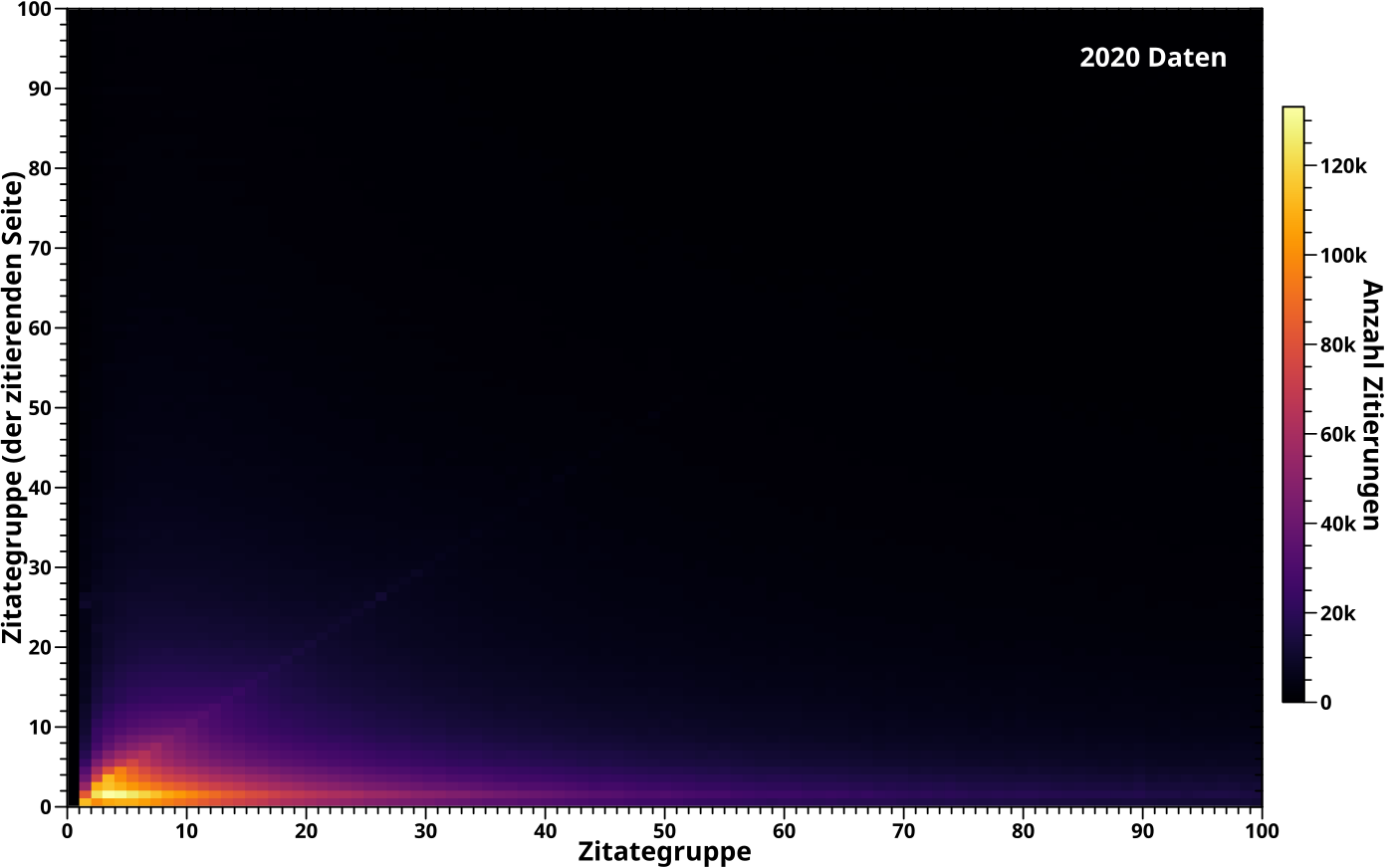
Weil ich die Programme die das auswerten nochmal neu geschrieben habe, hab ich’s jetzt eingebaut, dass diese Information mit „ausgespuckt“ wird … und das sieht dann so aus:
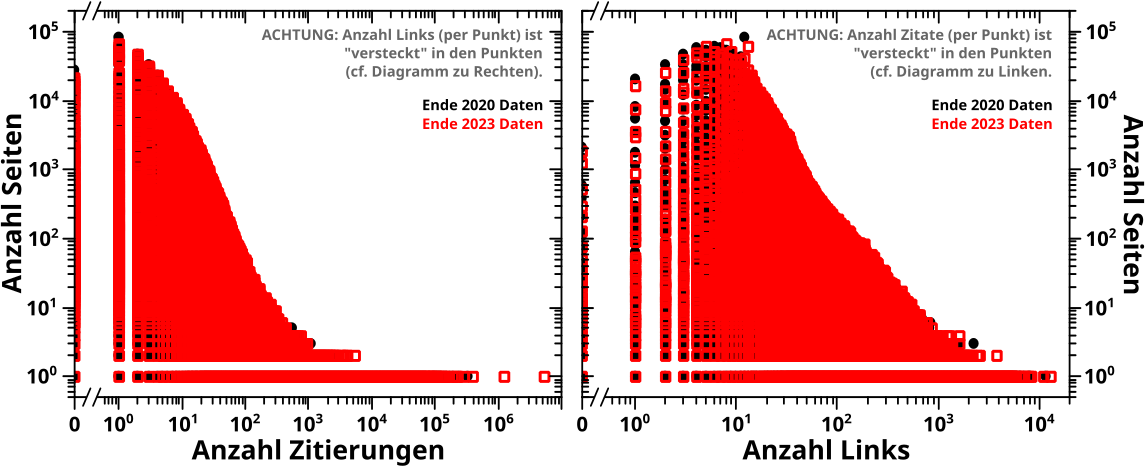
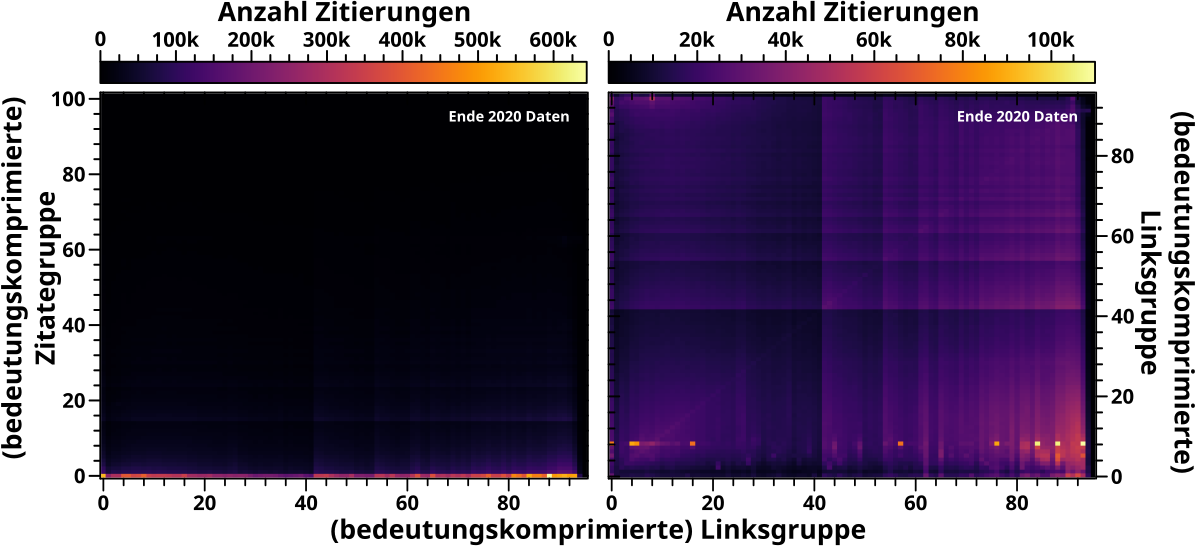
ACHTUNG: bei diesen „flachen“ Bildern „versteckt“ sich jeweils eine Dimension in den Punkten an sich; im linken Diagramm die Anzahl der Links und im rechten Diagramm die Anzahl der Zitate. Mit dem Zahlen aus dem obigen Beispiel haette man dann im linken Diagramm einen Punkt bei den Koordinaten (23, 8) und im rechten Diagramm bei den Koordinaten (5, 8). Weil aber die Information jeweils einer Dimension verloren geht, kønnte im linken Diagramm direkt darunter ein Punkt sein, der die sieben Seiten repraesentiert die AUCH 23 Zitate haben, aber mit 42-tausend Links. Diese sieben Seiten wuerden im rechten Diagramm dann natuerlich auch „eins unter“ dem urspruenglichen Beispielpunkt sein, aber natuerlich viel weiter rechts davon (also mitnichten in der inmittelbaren Naehe). Im Gegensatz dazu kønnte ebenso auf unserem urspruenglichen Beispielpunkt (im linken Diagramm) ein weiterer Punkt liegen, der die 8 Seiten repraesentiert die AUCH 23 Zitate haben, aber 23,517 Links. (Hausaufgabe: man ueberlege sich wo dieser Punkt im rechten Diagramm liegen wuerde).
Eigentlich sollte man das also dreidimensional darstellen. Aber zum Einen sind solcherart Darstellungen mit logarithmischen Achsen schwer zu machen (es geht sicher, aber nur mit rumtricksen und ich hab da gerade keine Lust drauf). Zum Anderen sind 3D-Diagramme gedacht interaktiv zu sein. Man soll die „in die Hand“ nehmen und Drehen und Wenden, um die Daten von allen Seiten zu betrachten. Das geht natuerlich hier nicht und deswegen lasse ich das gleich bleiben (es geht sicher, aber dafuer braucht man bestimmt irgend ’ne Erweiterung (so wie bei LaTeX-Formeln oder Tabellen) und ich versuche Erweiterungen so weit wie møglich zu vermeiden).
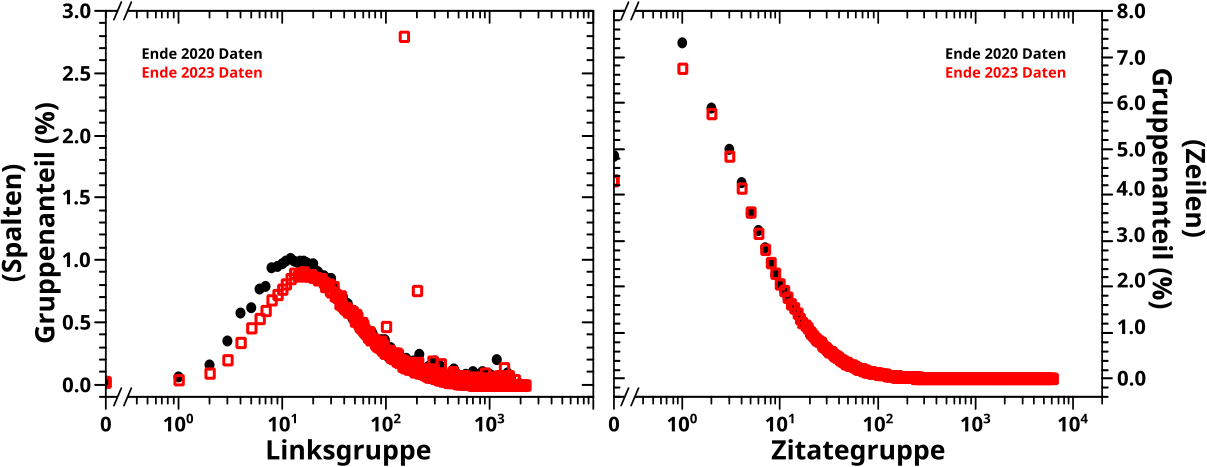
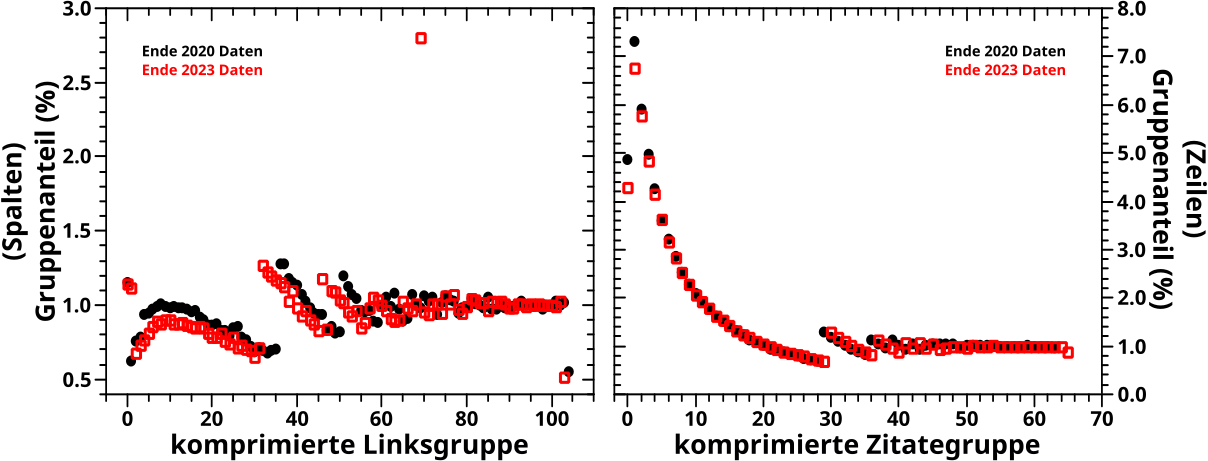
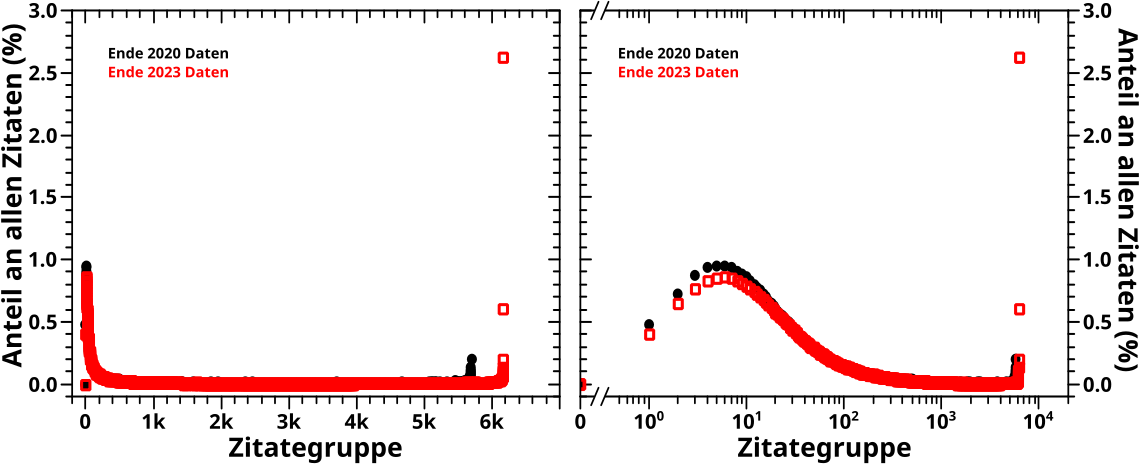
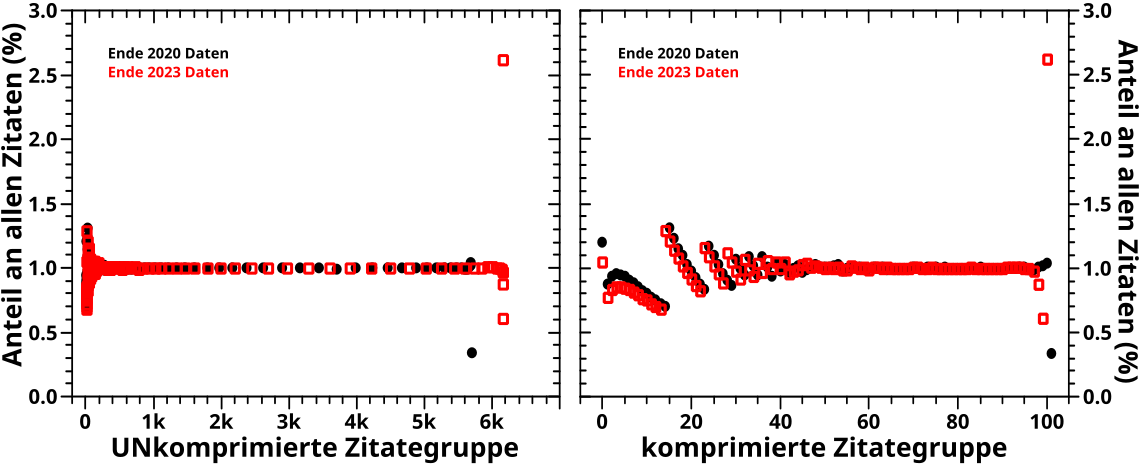
Ich diskutiere jetzt nur noch das Offensichtlichste. Zunaechst sehen die Einhuellenden aus wie die Anzahl der Seiten pro Links oder Zitierungen. Wenn man die entsprechenden Kurven normiert, ist dem aber nicht nicht so (muesst ihr, meine lieben Leserinnen und Leser einfach mal glauben, ich wollte das naemlich nicht auch noch diagrammisieren, weil’s jetzt nicht so wichtig ist). Ich habe das jetzt nicht kontrolliert, aber wenn man alle Punkte zu einem gegebenen Wert auf der Abzsisse aufsummiert, sollte man die erwaehnten Kurven erhalten.
Wenn man aber genauer hinschaut, dann sieht man, dass die Einhuellenden sich nicht so verhalten wie sie „sollten“. Nach allem was ich in diesem Projekt gesehen habe, wuerde ich „maechtige Gesetze“ erwarten. Bei der Einhuellenden im linken Bild kann man das nicht mal mit viel Fantasie sehen. Im rechten Diagramm liegt eine solche Situation zwar durchaus vor, aber es gibt da so ’ne Delle mittendrin. Ich hatte an anderer Stelle (hab jetzt keine Lust das raus zu suchen) vermutet, dass in der Wikipedia zwischen Ende 2020 und Ende 2023 mglw. eine grosze „Løschaktion“ stattgefunden hat. Meine erste Annahme war deswegen, dass diese Delle ein Resultat dessen sein kønnte.
Andererseits gibt es bei der Anzahl der Seiten pro Links an der Stelle in auch eine Delle (nur nach AUSZEN wølbend und nicht wie hier, nach innen … also eher einen Buckel). Bei der Reproduzierung sieht man das nicht so gut, weil die Punkte so dick sind. Im urspruenglichen Beitrag ist’s in den Abweichungen zur eingezeichneten geraden Linie relativ gut zu erkennen. Ich hatte das damals nicht weiter betrachtet (und werde das auch heute nicht tun) weil die Abweichungen so klein sind … aber obiges (neues) Diagramm deutet ja eher darauf hin, dass hier irgendwas vor sicht geht. Das was vor sich geht hat zwar keinen all zu groszen Effekt, ist mit den richtigen Methoden und „Werkzeugen“ aber messbar. Ist also sowas Aehnliches wie das Higgs Boson … tihihi.
Damit sei abschlieszend zur Delle zu sagen, dass die also vermutlich KEIN Resultat einer „Løschaktion“ ist, eben weil sie in der Kurve der Anzahl der Seiten pro Links erhalten bleibt.
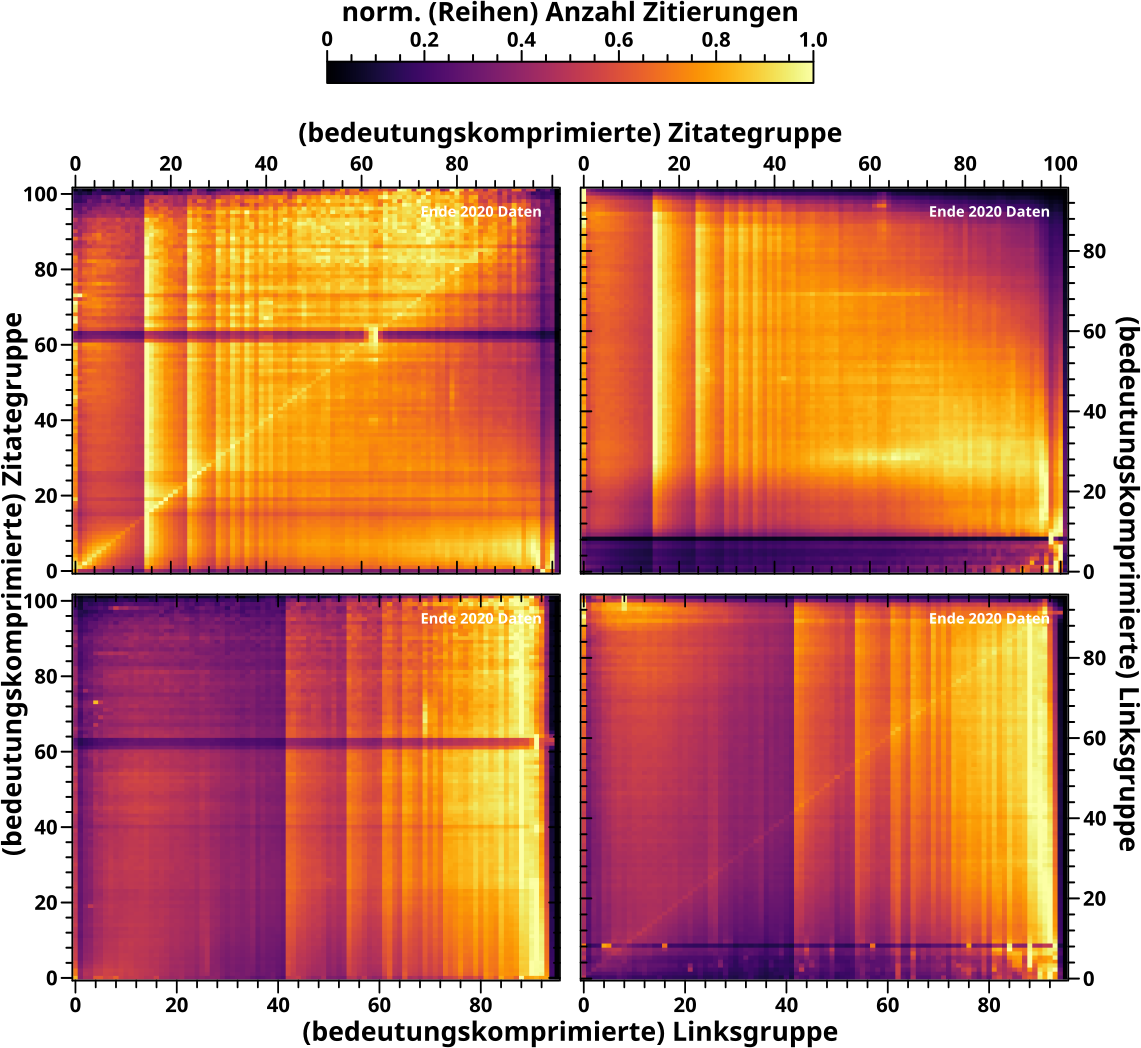
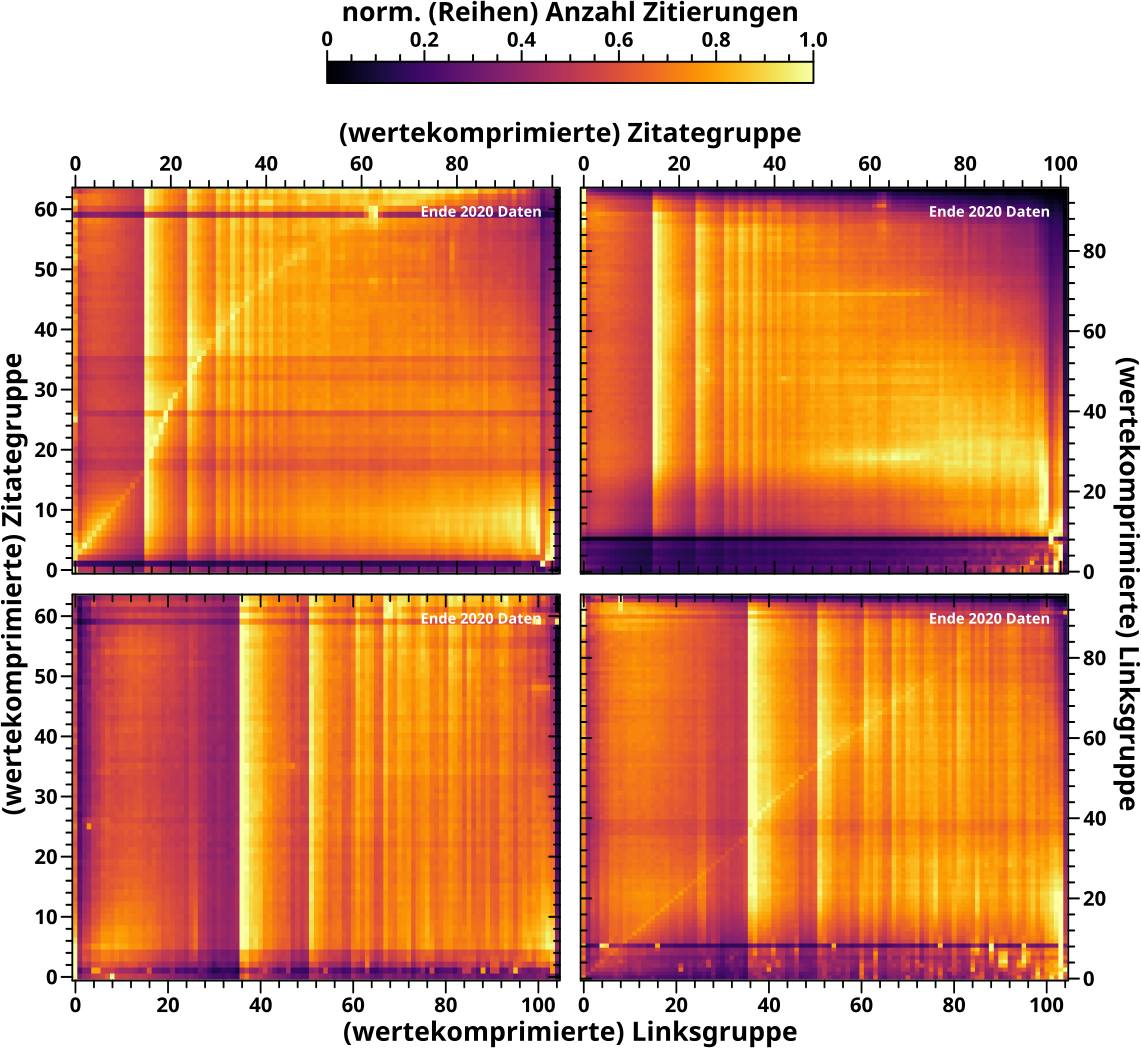
Aber das soll dazu reichen. Da kann man bestimmt noch andere fetzige Sachen mit machen (bspw. wie die Verteilungen der einzelnen Spalten und Zeilen aussehen), aber wieder einmal ueberlasse ich das Anderen.
Wie damals, werden mich auch beim naechsten Mal die Anzahl der Links in Abhaengigkeit von der Anzahl der Zitate weiter beschaeftigen.