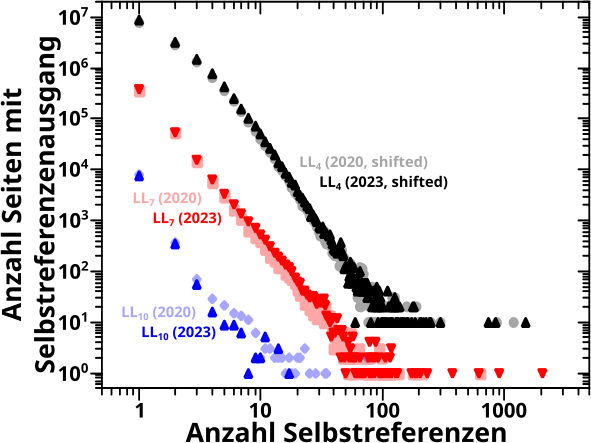
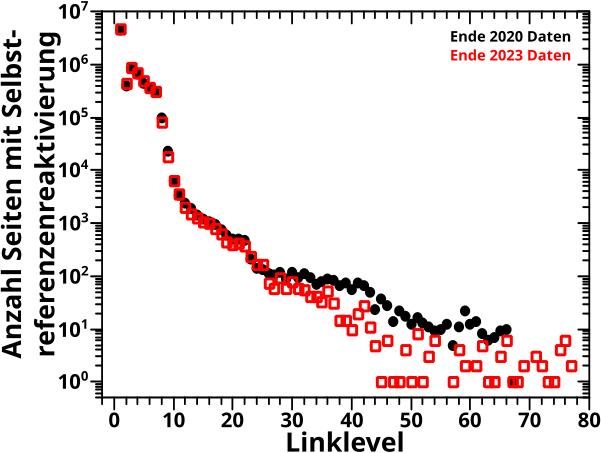
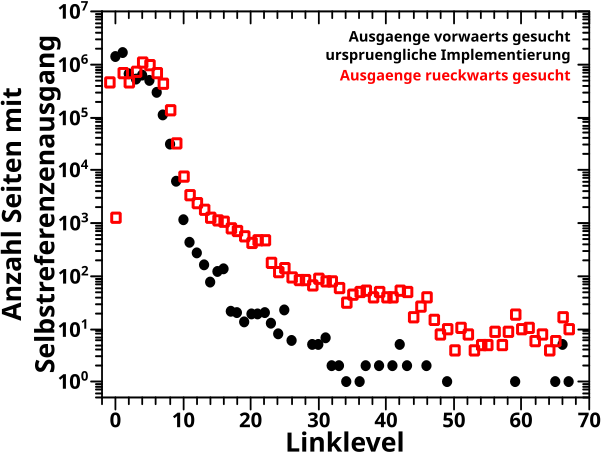
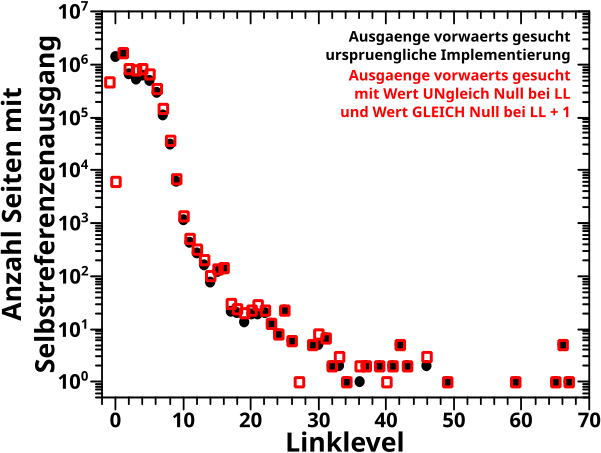
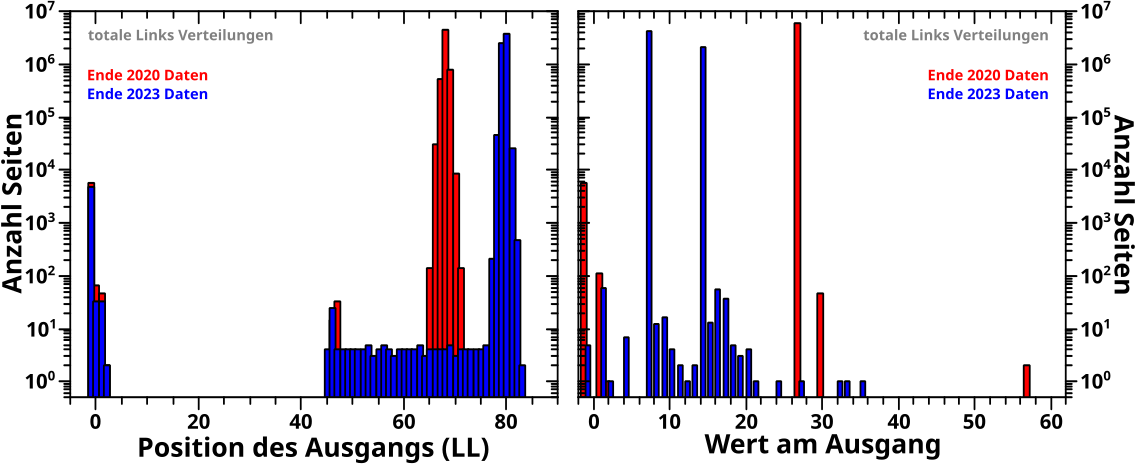
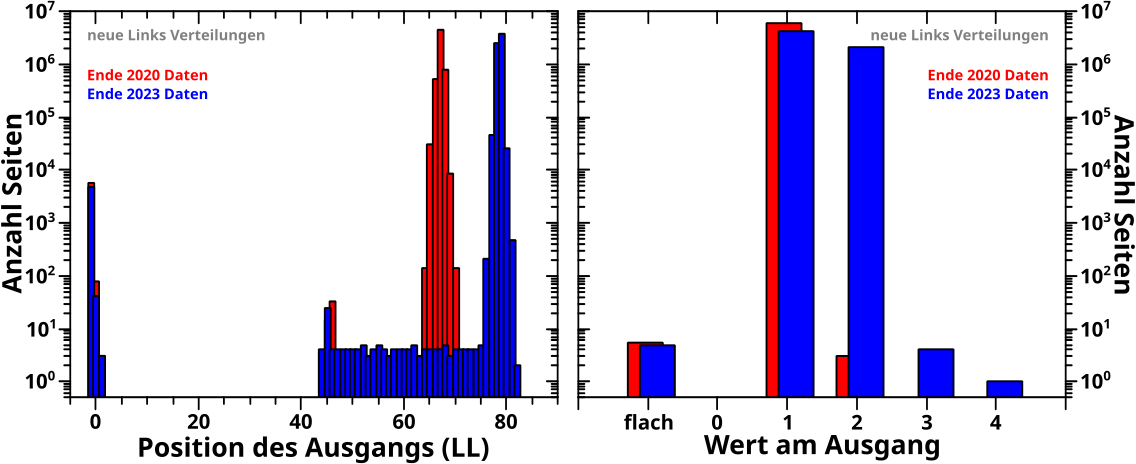
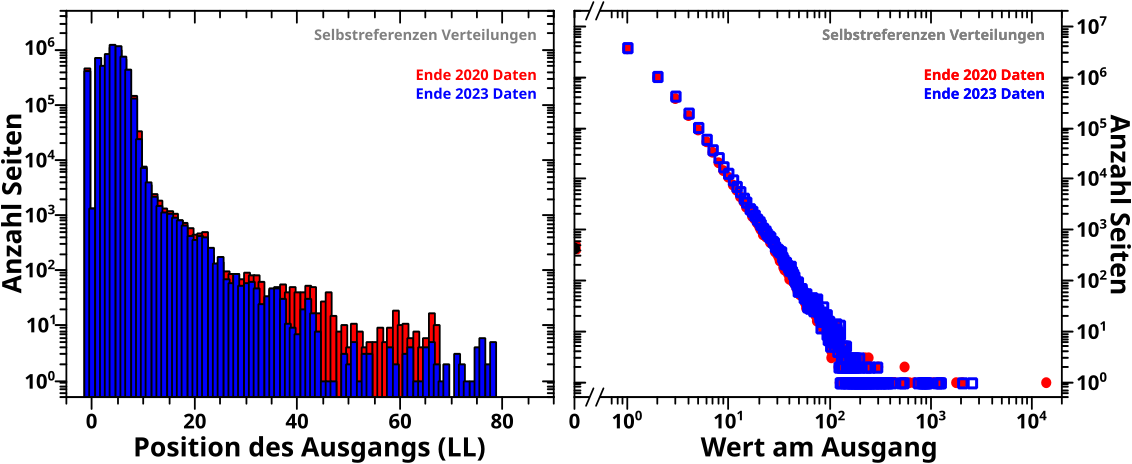
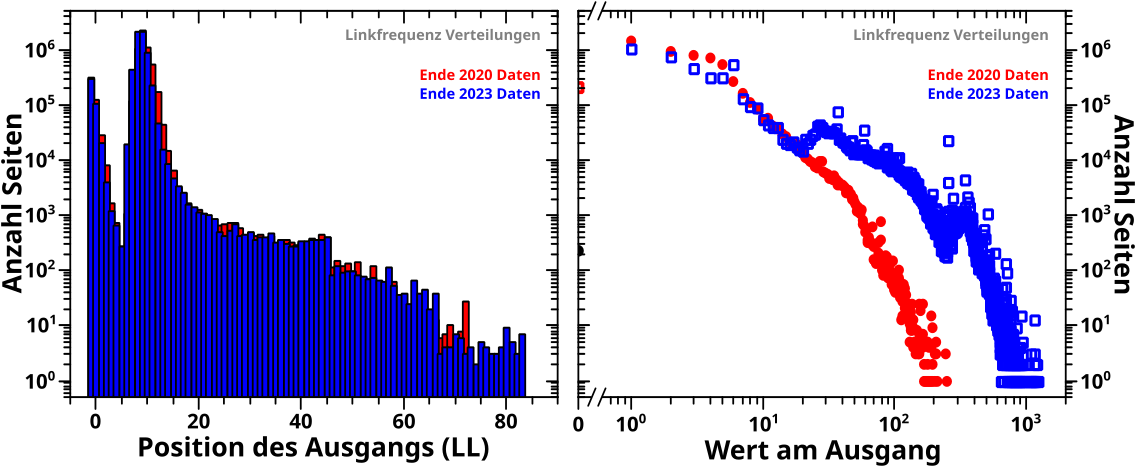
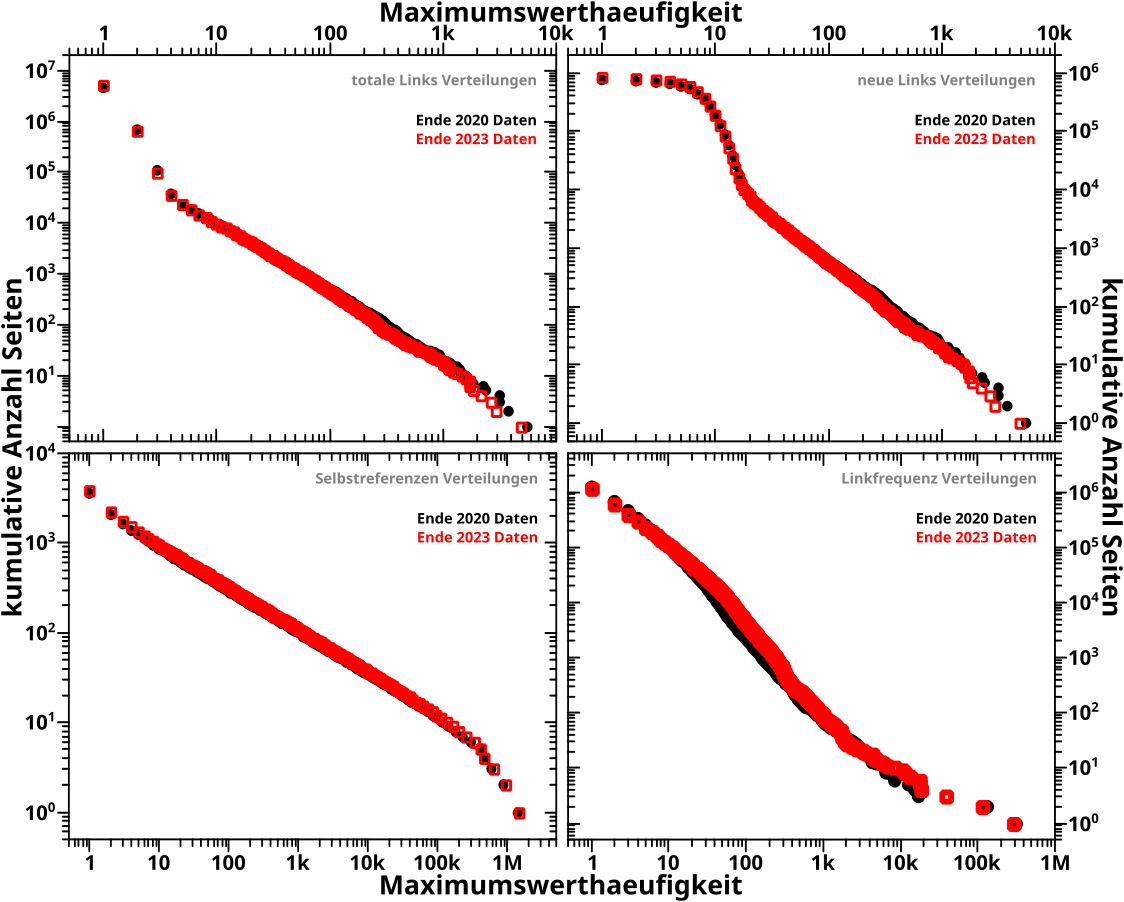
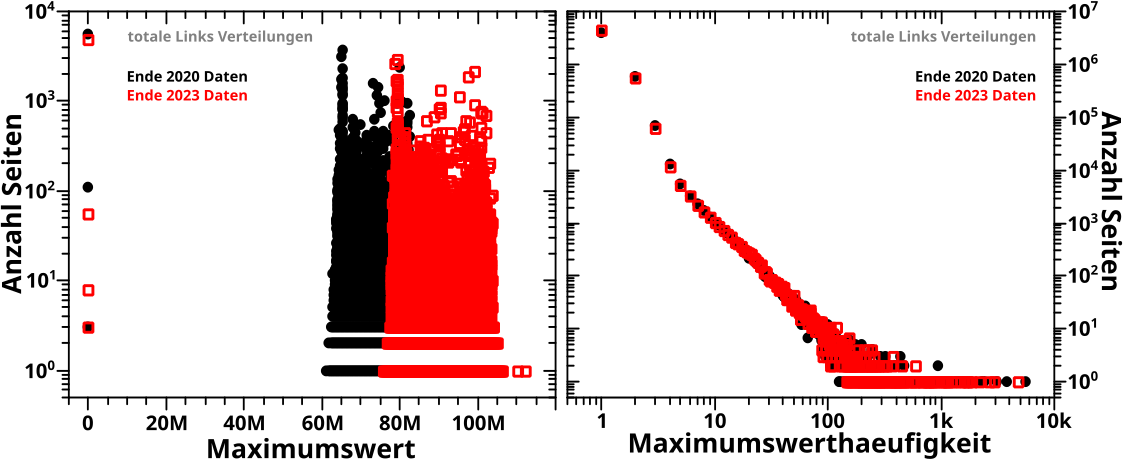
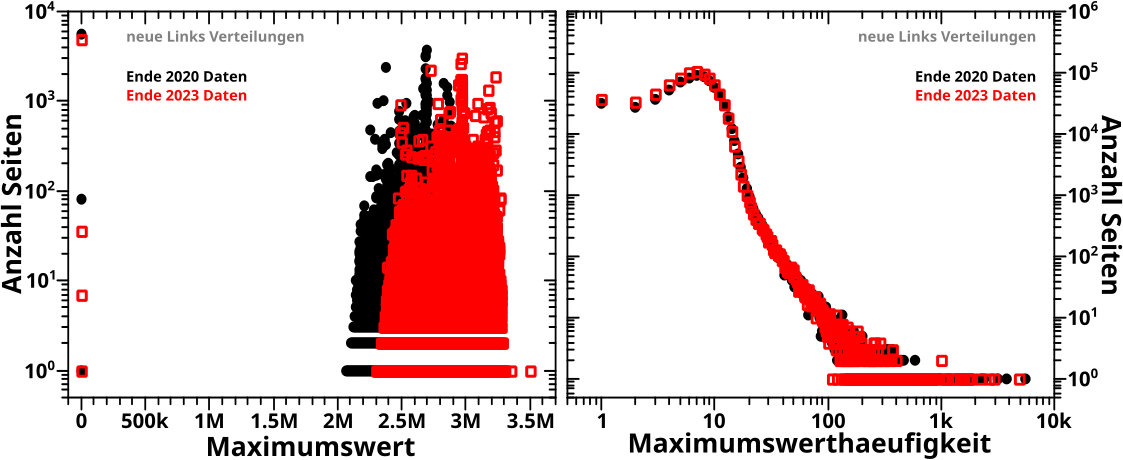
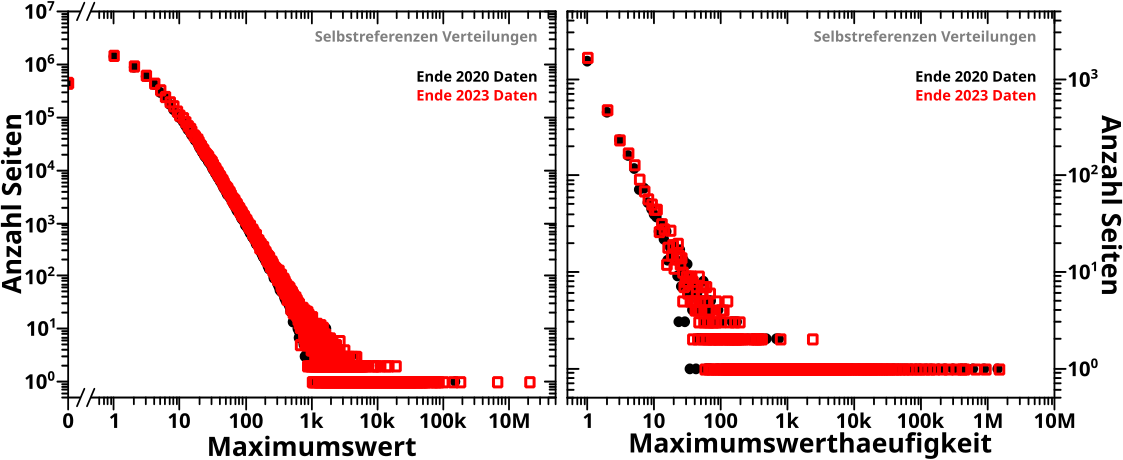
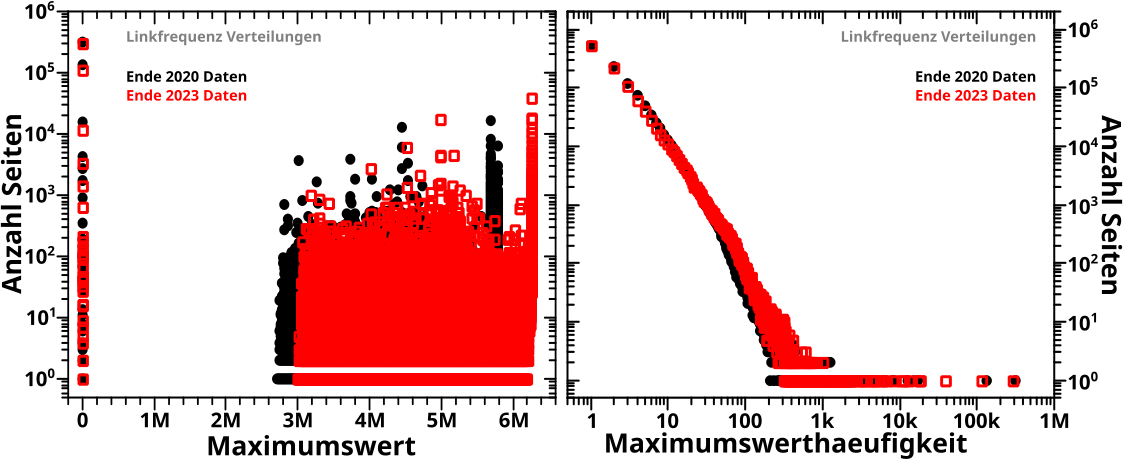
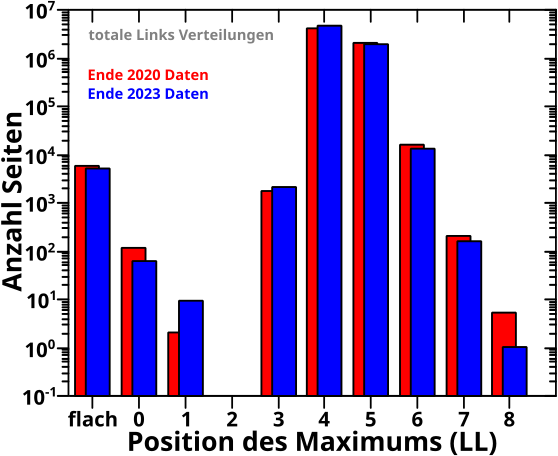
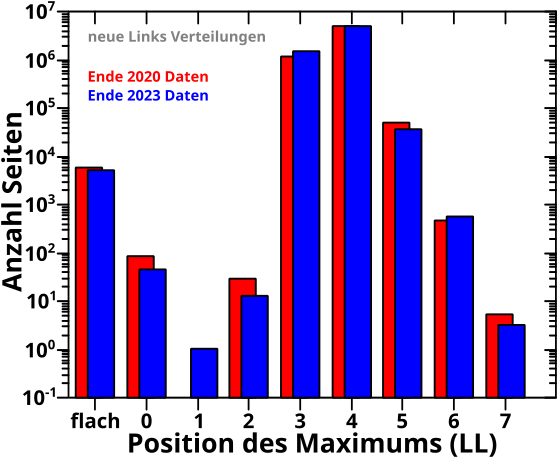
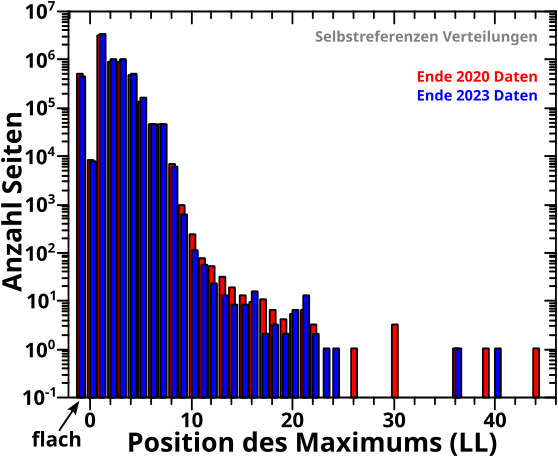
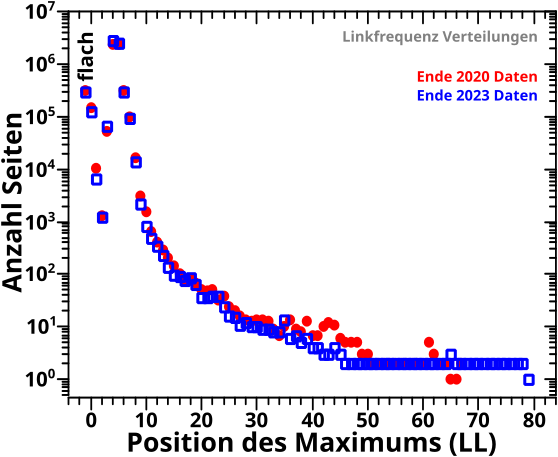
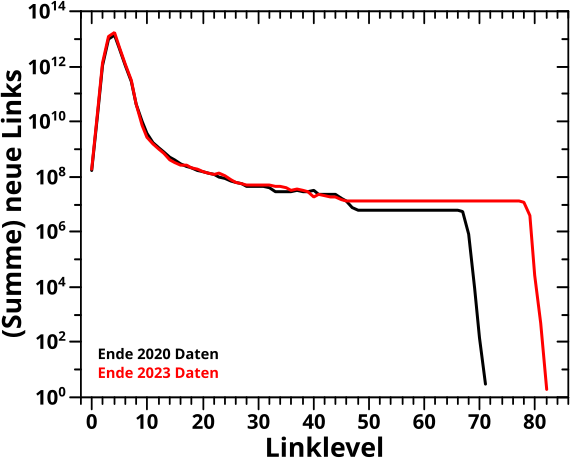
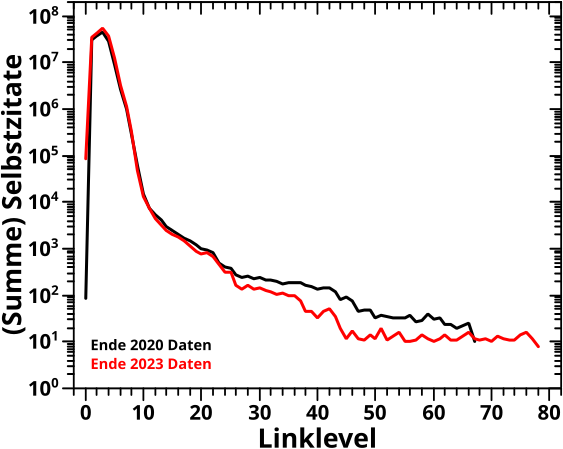
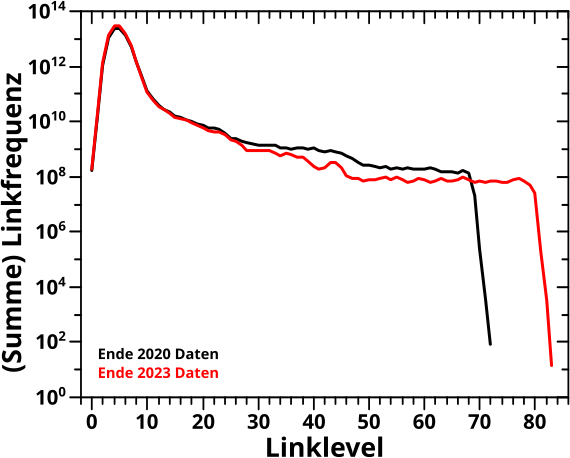
Direkt an das letzte Mal (also ohne Wiederholungen) anknuepfend:
Super! Reproduziert … … … … … … … … … aber hmmmm … hier stimmt doch was nicht!
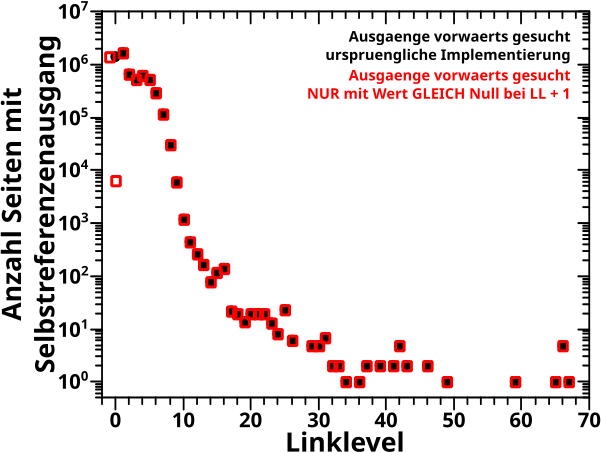
Am Anfang des letzten Artikels beschrieb ich die alte Vorwaertsmethode doch gar nicht mit „schaue wann der NAECHSTE Wert Null ist“ (auch wenn ich derart die damaligen Daten reproduzieren konnte; siehe das dritte Diagramm beim letzten Mal), sondern „schaue wo der ERSTE Wert Null ist“. Ich muss also die „wenn der Wert auf einem gegebenen Linklevel UNgleich Null ist“ Bedingung zu „wenn der Wert auf einem gegebenen Linklevel GLEICH Null ist“ modifizieren und NUR dies benutzen um nach „Ausgaengen“ zu suchen. Das sieht dann so aus:
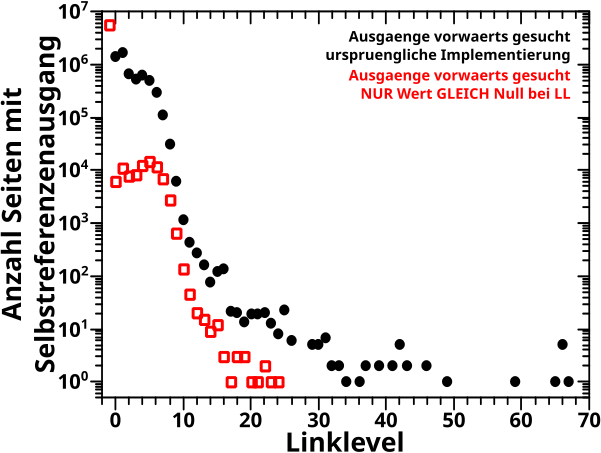
Verdammt! Wenn ich das was ich sagte (und meinte) ordentlich implementiere, dann sieht das zwar von der Form aehnlich aus, aber liegt im Wesentlichen ueberall ([zum Teil sehr deutlich] mehr als) eine Grøszenordnung UNTER den Ergebnissen von damals (und damit auch unter den Ergebnissen der Rueckwaertsmethode).
Aber da stimmt immer noch was nicht … ich kønnte mich da zwar gewaltig taeuschen, aber ich kann mich nicht erinnern, dass ich damals „schau ob der NAECHSTE Wert Null ist“ implementiert hatte. Wie bin ich dann aber auf die Ergebnisse gekommen?
Ueber die Antwort stolperte ich in anderen Beitraegen (die ich vermutlich naechstes Mal versuchen werde zu reproduzieren) und die ist trivial — ich hab (unbewusst) geschummelt:
[…] die Skala fuer das Linklevel [geht] erst bei 2 los. Auf LL1 kann nix reaktiviert werden.
Oder anders: ich fange an „Ausgaenge“ erst ab LL1 zu suchen (anstatt bei LL0). Und wenn ich schummel, dann erhalte ich tatsaechlich die Ergebnisse wie damals (siehe das erwaehnte dritte Diagramm im vorhergehenden Beitrag). Das entspricht naemlich dem Algorithmus „schaue ob der NAECHSTE Wert Null ist“, angefangen bei LL0, denn dabei steht man zwar am Anfang auf LL0 schaut aber als allererstes auf LL1.
Oder noch anders: die urspruengliche (!), damals benutzte (?) Vorwaertsmethode war ueberhaupt nicht so wie ich die beschrieben hatte. Vielmehr implementiere ich das damals mit der UNZULAESSIGEN (!) Zusatzinformation, dass Selbstreferenzen ohnehin nicht vor LL1 losgehen kønnen. Das ist aus zwei Gruenden unzulaessig. Zum Einen gibt es durchaus Seiten die Selbstreferenzen auf LL0 haben (auch wenn ich das als Artefakte des Dateneinsammelns erkannt habe). Zum Zweiten macht das die Vorwaertsmethode nur fuer Selbstreferenzen (und nicht allgemein) brauchbar, denn alle anderen Grøszen von Interesse MUESSEN auf LL0 anfangen.
Und hier liegt der schwerwiegende Fehler. Ich habe urspruenglich eine Methode benutzt die zum Ersten nicht gut ist und nur (wie im Nachhinein erkannt) mit Zusatzannahmen ordentliche Ergebnisse liefert. Zum Zweiten bei richtiger Implementierung (also ohne Zusatzannahmen oder erweiterte oder modifizierte Bedingungen, also genau so wie ich die Methode beschrieben habe) Ergebnisse zur Folge hat, die etwas vøllig anderes liefern als das was ich eigtl. suche. Und zum Dritten erhielt ich damals nur deswegen irgendwie (?) richtige (?) Ergebnisse, weil ich durch „schummeln“, die Diskrepanzen des zweiten Punktes unbewusst und unerkannt, also aus Versehen, kompensiert habe.
DAS ist eine Art Fehler die wissenschaftliche Arbeiten fundamental zu Fall bringen.
Mich duenkt (bin mir aber nicht ganz sicher) ich erwaehnte das Folgende bereits an anderer Stelle. Im Wesentlichen kønnen alle Fehler in der Wissenschaft in zwei Kategorien eingeordnet werden.
1.: Berichtigungen,
2.: die Methode ist komplett falsch weil zugrundeliegende Annahmen oder Methoden Quatsch sind.
Berichtigungen sind OK und wichtig. Die kønnen auch die Methode kritisieren und kønnen flapsig als „man muss aber diesen Effekt auch beachten und dann korrigiert das Ergebniss 5 % nach unten“ bezeichnet werden. Rein vom „Rechnerischen“ kønnte man das bzgl. der Korrekturen an Newtons Vorhersagen durch Einsteins Gravitationstheorie sagen. Und rein vom Rechnerischen ist das auch OK und die Menschenhheit hat mittels Netwons Theorie Menschen auf den Mond gebracht. Aber …
… Newton meinte von seiner Gravitationstheorie, dass diese das Universum beschreibt, waehrend Einstein zeigte, dass die grundlegenden Annahmen Newtons, ein universales Koordinatensystem, auf das man von ueberall aus Bezug nehmen kann und instantan wirkende Kraefte, komplett ueberhaupt nicht der Realitaet entsprechen. Newtons Theorie geht von so falschen Annahmen aus, dass Einstein die Theorie komplett zu Fall gebracht hat.
Newtons Theorie funktioniert verdammt gut fuer alles was uns im normalen Leben interessiert, denn da sind seine Annahmen zwar (auch) nicht realisiert, aber weil nur kleine Gravitationsfelder und Geschwindigkeiten vorliegen ist das nicht so schlimm und es fuehrt nur zu winzigkleinen Fehlern, wenn man so tut als ob sie realisiert sind. Das fuehrt aber NICHT dazu, dass Einsteins Gravitationstheorie nur zu einer Berichtigung wird, denn selbst bei kleinen Gravitationsfeldern und Geschwindigkeiten beschreibt Newtons Theorie das Universums nicht wirklich, denn Newtons Theorie laeszt bspw. Gravitationswellen nicht zu.
Und der Punkt bleibt selbst dann bestehen, wenn aus Newtons Theorie die „richtigen Zahlen rausfallen“. Ein anderes Beispiel was meinen Punkt mglw. etwas besser illustriert sind „KI“ Chatbots. Wir sind laengst nicht mehr in der Lage die von echten Menschen zu unterscheiden (wenn wir es nict vorher wissen). Oder anders: es „fallen die richtigen Zahlen“ bei einem Gespraech mit denen raus. Das macht solche „KI“ Chatbots noch laengst nicht zu Menschen. Auch dann nicht, wenn sie in Roboter installiert werden, die aueszerlich nicht von Menschen unterschieden werden kønnen (wenn „die Zahlen“ also noch „richtiger“ werden). Und das Argument bleibt auch dann bestehen, wenn man die Anfuehrungszeichen weg laeszt und man irgendwann echte Intelligenzen (nur eben auf Silizium basierend) hat, denen man dann meiner Meinung nach sogar Persønlichkeitsrechte einraeumen muss … das sind immer noch keine Menschen … selbst dann nicht wenn wir sie wie Menschen behandeln (siehe bspw. der Film Her … „die Zahlen“ als noch „richtiger richtiger“ werden) … es sei denn natuerlich, wir veraendern die Definition von „Mensch“ (und damit die zugrundliegende Theorie) fundamental.
Und wer mir jetzt mit „Aber aber aber! Newton ist richtig, denn wir bauen damit doch Bruecken und bringen Menschen auf den Mond und ich soll mal bitte nicht so’n Erbsenzaehler sein“ kommt, den verweise ich auf Aristoteles. Denn der hat gesagt, dass jeder bewegte Gegenstand AUTOMATISCH zur Ruhe kommt, wenn man den in Ruhe laeszt. DAS beschreibt die Welt um mich herum, wie ich sie den ganzen Tag sehe und erlebe, VIEL besser als Newtons erstes Gesetz. Deswegen war es DIE akzeptierte Wahrheit bzgl. dessen wie die Welt funktioniert fuer Jahrtausende. Als Newton formulierte, dass dem NICHT so ist, war es damals auch direkt als Widerlegung von Aristoteles gemeint. Und wer mir so kommt, møge mir bitte detailliert darlegen, warum er das auf Newton, aber nicht auf Aristoteles bezieht … Aber ich schwoff ab.
Oder anders: „KI“ Chatbots als Menschen zu behandeln, oder mit Netwons Gravitationstheorie (bisher ausschlieszlich) Maenner auf den Mond zu bringen, reproduziert zwar was wir messen, es beschreibt aber nicht das Universum.
Und deswegen hab ich das beim letzten Mal (und hier) alles so detailliert ausgebreitet. Auf den ersten Blick sieht’s so aus als ob die zwei Methoden um „Ausgaenge“ zu finden nicht viel anders sind und alle Unterschiede in den Ergebnissen natuerlich erklaert werden kønnen. Als ich aber genauer hinschaute erkannte ich, dass eine ordentliche Implementierung der urpsruenglich diskutierten Vorwaertsmethode eigentlich vøllig andere Ergebnisse zur Folge hat und das damals nur durch weitere, nicht erkannte, Fehler (bzw. unzulaessige Zusatzannahmen) kompensiert wurde.
Und DAS ist ein schwerwiegender Fehler der zweiten Art und ich kann hier eigentlich nur sagen: Reproduktion NICHT geglueckt.
Solche Fehler passieren und das ist auch erstmal nix Schlimmes. Es ist durchaus auch ein Zeichen von Fortschritt, denn ein Fehler wird ja erst dann zum Fehler wenn man den als solchen erkennt (vorher ist’s einfach nur richtig und die Wahrheit). In der Wissenschaft sollte man das dann halt nur eingestehen und genau diskutieren um zu erkennen was falsch gemacht wurde, damit man aehnliche Fehler an anderer Stelle nicht wiederholt.
So, nun hab ich alles gesagt, was ich sagen wollte un kann mit ruhigem Gewissen beim naechsten Mal endlich die naechste Reproduzierung angehen.