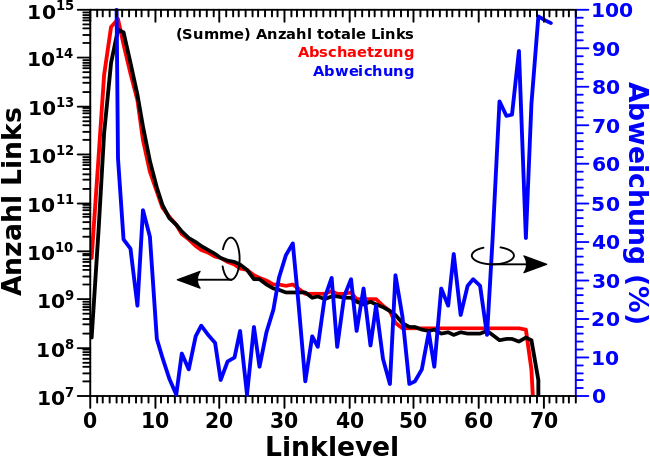
Nach der vielen Theorie die letzten beiden Male heute nun Messwerte :) … aber der Reihe nach.
Das Ende des letzten Beitrages aufgreifend: waehrend es (beinahe) unvermeidlich schien, dass es eine „Insel der Unzitierten“ geben muss, so galt dies nicht fuer die Existenz des No-way-home-Archipels. In den Daten konnte ich Letzteres aber direkt nachweisen. Kann ich dies auch bzgl. der Archipele der erweiterten Form?
Wie erwaehnt, musste ich zur Klaerung dieser Frage eine schøne rekursive Funktion schreiben. Ich wuerde diese gerne im Detail diskutieren, denn ich finde rekursive Funktionen voll toll und es ist total schade, dass ich die nicht øfter brauche. Ich befuerchte allerdings, dass dies kontrapodutkiv waere. Deswegen muss ich die Diskussion anders aufziehen.
Bisher arbeitete ich derart, dass ich fuer jede Seite wusste, welche anderen Seiten diese zitiert und folgte dem Linknetzwerk einen Schritt nach dem anderen. Hier nun muss ich zunaechst das „Spiegelbild“ zu diesen Daten nehmen, ich musste also fuer jede Seite bestimmen, von welchen anderen Seiten diese zitiert wird. Dann folgte ich dem Linknetzwerk rueckwaerts. Ich schaute also fuer eine Seite von wem diese zitiert wurde und bei den zitierenden Seite schaute ich wer diese zitierte und so weiter. Das ist die Rekursion und die fuehrte ich so lange fort, bis keine neuen zitierenden Seiten mehr auftauchten.
Wieauchimmer, rekursive Funktionen haben einen Nachteil: rein praktisch kann ein Computer eine Rekursion nicht beliebig tief folgen. Jedes Rekursionslevel benøtigt eigene Ressourcen und davon habe ich nicht unendlich viele in meinem Rechner verbaut.
Deswegen schraenkte ich einen Parameter fuer die Analyse folgendermaszen ein: wenn eine Seite von mehr als 69 anderen Seiten zitiert wurde, so wird die Rekursion abgebrochen. Das ist nicht die ganze Wahrheit, 69 ist das Limit fuer zitierende Seiten die ich auf einem gegebenen Rekursionslevel noch nicht „gesehen“ habe. Die Anzahl aller zitierenden Seiten kønnte also betraechtlich høher sein.
Ich denke, dass dies Limitierung plausibel ist, denn wenn eine Seite von mehr als 69 Seiten zitiert wird, so ist es sehr unwahrscheinlich, dass alle diese _nicht_ irgendwie eine Verbindung zum „groszen Auszerhalb“ haben. Letzteres wuerde dann auch die urspruengliche Seite mit der ich startete mit diesem verbinden und damit kønnte die Startseite nicht Teil eines Archipels sein.
Ich testete bis zum Wert 1500 (ab 2000 wird die Rekursionstiefe so grosz, dass ich in oben erwaehnte Ressourcenlimitierung laufe, bzw. laeszt Python das nicht mehr zu um eben dies zu vermeiden). Der „Umschlagpunkt“ ab dem keine weiteren Archipele mehr dazu kamen lag bei 68. Der Wert 69 kommt durch das Abfaerben des juvenilen Humors, des jungen Mannes der bei mir wohnt, auf mich zustande.
Desweiteren liesz ich das No-way-home-Archipel auszen vor. OKOK, das stimmt nicht ganz. Ich nahm es einmal mit in die Analyse rein. Dann dauerte Selbige aber ca. 10 Stunden, anstatt ein paar Minuten. Deswegen habe ich das nur ein Mal gemacht. Ich bespreche die Unterschiede bei den Ergebnissen an anderer Stelle, weil ich denke, dass dies durchaus lehhreich sein kann.
Aber genug der Vorrede und Vorhang auf fuer die Ergebnisse; zunaechst das bereits Bekannte.
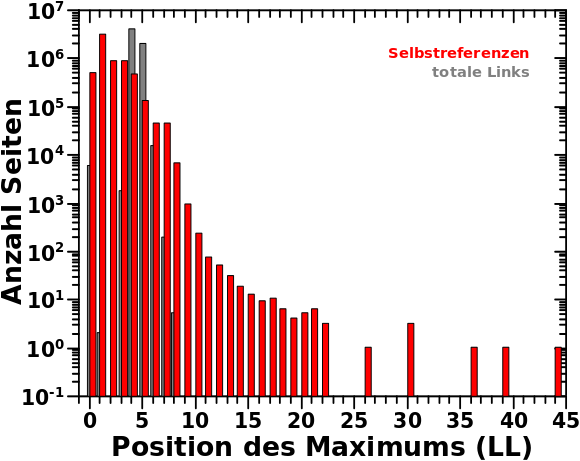
Zum ersten Balken der Verteilung der Maxima der individuellen Verteilungen der Selbstreferenzen tragen 474.653 Seiten bei. Davon gehørten 7649 zu Seiten die sich auf LL0 selbst zitieren (von insgesamt 83.435 Seiten mit dieser Eigenschaft) und auf keinem Linklevel mehr als eine Selbstreferenz haben. Somit blieben 467.004 uebrig, die erklaert werden mussten.
Daraufhin unternahm ich Untersuchungen, die zur Entdeckung des No-way-home-Archipels fuehrten. Die grøszte „Insel“ dieses Archipels ist die „Insel der Unzitierten“ mit 320.089 Seiten und insgesamt „wohnen“ auf dem gesamten Archipel 451.792 Seiten.
Damit blieb fuer nur noch 15.212 Seiten ungeklaert, warum diese zum Signal in besagtem ersten Balken beitragen. Dies fuehrte zu den Ueberlegungen bzgl. der Erweiterung/Verallgemeinerung des Archipelkonzepts. Hier kommen dann endlich die neuen Ergebnisse.
Ohne jeglichen Einfluss des No-way-home-Archipels finde ich fast 30-tausend Untergruppen. Wenn diese zu den grøsztmøglichen, zusammenhaengenden (Ueber?)Gruppen zusammen gezogen werden, bleiben noch 8.258 Archipele. Hurra! Die Existenz von (konzeptuell erweiterten/verallgemeinerten) Archipelen ist bewiesen. Nun wird es spannend, ob ich damit auch das erklaeren kann, was ich erklaeren will.
Von den 15.212 Seiten die zitiert werden, aber keine Selbstreferenzen haben, befinden sich 9995 auf diesen Archipelen. Streng genommen muesste ich noch schauen, ob die Zitierungen auch wirklich von niedrigeren „Stufen“ kommen. Aber rein logisch muss das ja so sein, denn wenn sie von høheren Stufen kommen wuerden, dann muessten diese Seiten ja Selbstreferenzen haben. Deswegen spare ich mir das Schauen an dieser Stelle mal ausnahmsweise.
Das ist alles was ich aus den ganzen langen Ueberlegungen und den vielen Stunden die ich mit der Analyse dazu zubrachte herauskam … so viel geschrieben (nicht nur in diesem Beitrag), fuer nur eine einzige Zahl … das kønnte man als eher mickrige Ausbeute sehen, wenn da nicht die Freude am Erkenntnisgewinn und jede Menge neues, konzeptuelles Wissen ueber das Linknetzwerk an sich waeren … aber dazu mehr an anderer Stelle (wie es z.Z. aus sieht als Weihnachtsbeitrag).
Und selbst mit dieser Zahl bleiben 5217 Seiten uebrig … da dachte ich zunaechst .oO(verdammt) … um dann erleichtert fest zu stellen, dass ich ja noch gar nicht solche Seiten in Betracht gezogen hatte, die keine Links haben, aber zitiert werden.
Seiten ohne Links kennen wir schon von den „ganz fruehen Aussteigern“ aber nicht alle von denen werden zitiert, weswegen ich nicht einfach die Zahl von dort nehmen kann. Ist letzteres der Fall, dann sind die schon bei den „Bewohnern“ der „Insel der Unzitierten“ gezaehlt worden. Aber siehe da, 5202 Seiten werden zitiert, haben aber keine Links … hurrah … oder eher: AAARGHAGAHGRHG … da bleiben naemlich immer noch 15 Seiten uebrig.
An dieser Stelle dachte ich zunaechst: .oO(15 von fast 500k … da ist der erste Balken ja (fast) komplett erklaert und das „fast“ ist ein sehr sehr sehr kleines „fast“ … das kann ich getrost alles in den Fehler schieben … auszerdem habe ich mit den Archipelen so viel gelernt, eigentlich kønnte ich hier auch aufhøren).
Aber ein Teil meines Wesens ist, dass ich erst „aufgebe“, wenn ich wirklich nicht mehr weiter weisz. Und hier hatte ich zwar zunaechst keine Idee, aber das Beduerfniss, da noch laenger drueber nachzudenken, auch wenn es nur noch 15 Seiten waren, die einer Erklaerung bedurften.
Und ich gruebelte und gruebelte und kam einfach auf keinen plausiblen Mechanismus fuer diese 15 Seiten.
Dann ging ich auf einen Spaziergang … und wie so oft auf Spaziergaengen scheint die Bewegung auch mein Gehirn in Gang zu bringen, denn pløtzlich hatte ich eine Erklaerung parat.
Bei diesen 15 kønnte es sich um Seiten handeln, die von „Auszen“ zitiert werden (also zu keinem Archipel gehøren), die mindestens einen weiterfuehrenden Link haben (also nicht unter die obigen 5202 Seiten fallen, fuer die das nicht gilt) aber wo die Linkkette dann schnell ins Leere fuehrt. Also weitere „fruehe Aussteiger“ aber nicht auf LL0 wie oben, sondern auf LL1-3.
Und tatsaechlich! Diese 15 Seiten werden alle aus dem groszen Wikipedialinknetzwerk (und auch von Archipelen, aber nur Ersteres ist relevant) zitiert. Manche sogar mehrfach. Desweiteren haben alle nur einen Link und alle diese Links fuehren zu Seiten die keine weitern Links haben. … YEEEEEEEES!!! … I AM AWESOME!
Tja, und damit ist das Signal im ersten Balken komplett erklaert und das Mysterium ist keins mehr! Toll wa!