Da schrieb ich beim letzten Mal, dass …
[i]ch […] mich darauf [freue], diese Maxiserie nach fast drei Jahren abzuschlieszen
und prompt faellt mir auf, dass im allerersten Beitrag nur eine einzige Frage konkret … nun ja … nicht gestellt wird, sondern ich sag jetzt mal im Raum haengt und ich die nie behandelt habe.
So ziemlich alles was ich behandelte „erzaehlten“ mir die Daten selbst und ich musste die zu den Antworten gehørenden Fragen oft genug erstmal finden. Was natuerlich erklaert, warum ich besagte Frage bisher nicht behandelt habe, denn ich stellte sie ja nicht konkret und die Antwort dazu ist bisher nicht „aus den Daten gefallen“.
Worueber rede ich eigentlich? Nun ja, im ersten Beitrag gab ich an, wie man von Trondheim zu Kevin Bacon gelangt und tue das sogleich als wenig von Interesse ab:
[f]uer so ein paar konkrete Fragen war dieses Spielzeug ganz nett.
Vielmehr …
[…] wollte [ich] wissen, wie alles mit allem anderen zusammenhaengt.
Die im Raum haengende, nicht gestellte, konkrete Frage ist dann natuerlich: wieviele „Schritte“ braucht man im Durchschnitt von irgendeiner Seite zu irgendeiner anderen Seite?
Und ich muss sogleich sagen, dass ich diese Frage NICHT direkt (!) beantworten kann, denn dafuer habe ich die Daten nicht.
Fuer eine direkte Beantwortung waere es fuer jede Seite nøtig zu wissen, wann diese von jeder anderen Seite gesehen wird. Theoretisch kann man diese Information sammeln, das wuerde aber ein (dreidimensionales) Datenfeld der Grøsze 6 Millionen zum Quadrat mal 100 erfordern … jede Seite zu jeder anderen Seite mal die Anzahl der erwarteten Linklevel.
Das ist der technische Grund gewesen, warum ich die Linkfrequenz einfuehrte (die sich spaeter auf verschiedenste Weisen als extrem erfolgreich herausstellte). Bei der Linkfrequenz handelt es sich um eine Art „Projektion“ (mit (gewaltiger) Informationsminderung) des originalen 3D-Datenfeldes auf nur 2 Dimensionen, was die benøtigte Grøsze um mehr als sechseinhalb Grøszenordnungen vermindert (nur noch 6 Millionen mal 100). Dennoch erfordert das immer noch ca. 2 GB Arbeitsspeicher … womit man sich ausrechnen kann, dass die originale Idee ungefaehr 10 Petabyte (!) RAM braucht. Sportlich, nicht wahr.
Jaja, man kønnte das originale Problem immer nur eine Seite auf einmal machen, dann reichen auch 2 GB RAM … aber das Ergebniss will ja auch gespeichert werden zur nachfolgenden weiteren Analyse … und da braucht man dann doch wieder die 10 Petabyte (nur nicht als RAM sondern auf der Festplatte).
Wieauchimmer, ich kann die Frage gluecklicherweise indirekt angehen und meiner Meinung nach auch zufriedenstellend beantworten. Dafuer sind endlich mal die neuen Links pro Linklevel von Interesse (die ja bisher eher weniger „fruchtbar“ waren) und (wieder einmal) die Linkfrequenz. Aber wie immer ist das zumindest in Teilen nicht so einfach.
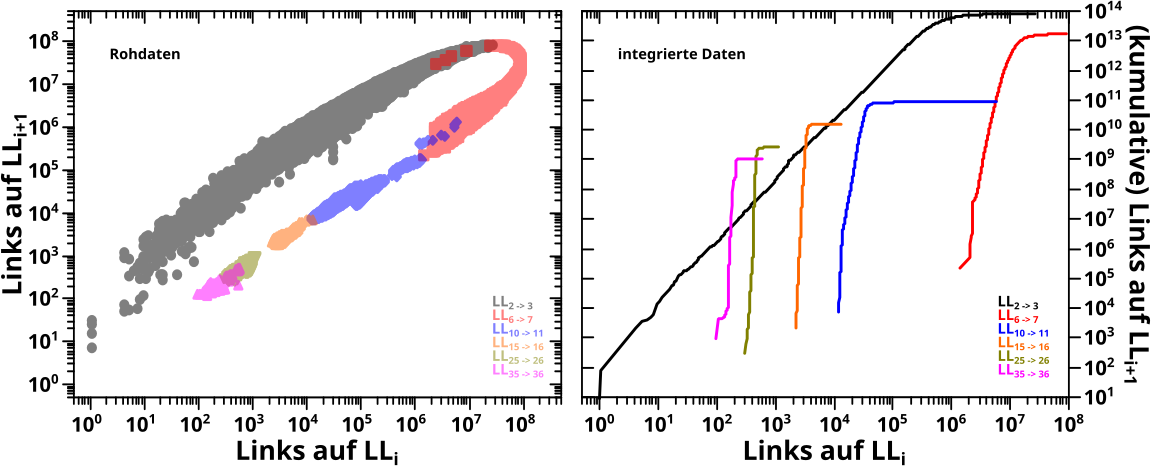
Ich beginne mit der Anzahl der neuen Links pro Linklevel. Korrekter: mit der Summe dieser Grøsze ueber alle Seiten und das Ganze per Linklevel. Das wurde hier schonmal gezeigt und die diagrammisierte das bis LL10 mit linearer (linker) Ordinate in diesem Bild als schwarze Kurve nochmals (man beachte das schwarze (!) „x1012„, welches ausdrueckt, dass die Werte fuer die schwarze Kurve damit multipliziert werden muessen um die (tatsaechliche) Anzahl der neuen Links (pro Linklevel) zu erhalten … das ist aber im hiesigen Zusammenhang eher eine Formalitaet, da mich der Wert an sich ja gar nicht weiter interessiert):
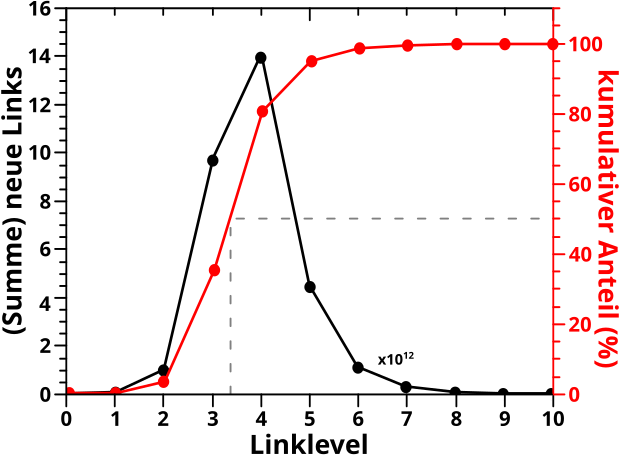
Zur Erinnerung: von einer Urpsrungsseite ausgehend, druecken die neuen Links auf jedem Linklevel aus, wieviele von allen Links die ich auf dem gegebenen Linklevel sehe, auf keinem vorherigen Linklevel auftauchten. Das (bestimmte) Integral unter dieser Kurve ergibt dann die Anzahl aller Wikipediaseiten (unabhaengig von der Ursprungsseite). Das Integral der obigen schwarzen Kurve ist dann also die Anzahl aller Wikipediaseiten zum Quadrat (da die Kurve ja das Summensignal ueber alle Seiten ist).
Kurzer Einschub und Achtung: ich lasse in allen Betrachtungen diesbezueglich die Archipele auszer acht … die haben natuerlich ein grøszeres Integral weil die ja zumindest Teile des Archipels UND das grosze „Gesamtnetzwerk“ sehen, wohingegen die Seiten im Gesamtnetzwerk keine Archipelseiten sehen. Das sollte aber keinen all zu groszen Unterschied machen.
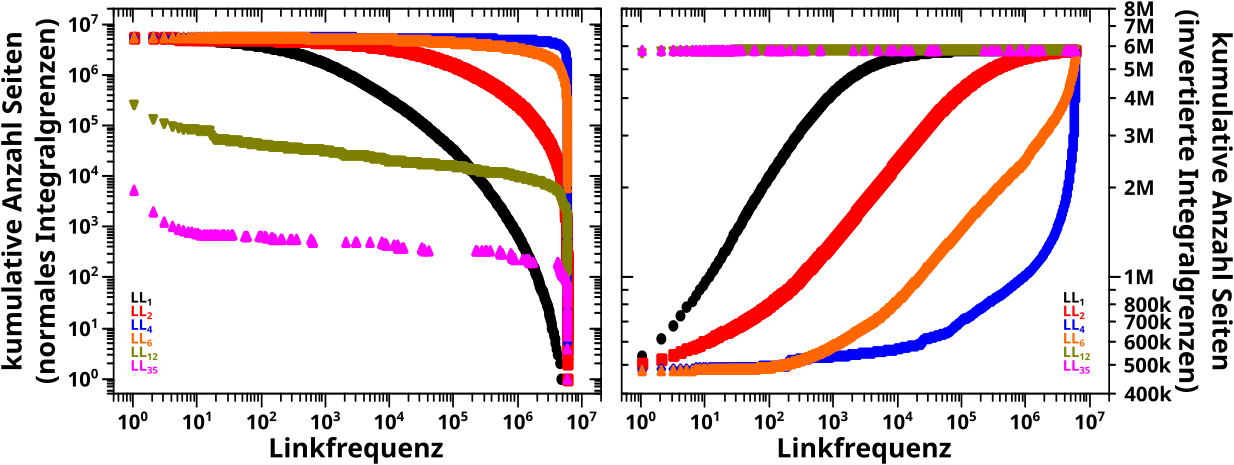
Wenn ich nun besagtes Summensignal durch das Integral unter der Kurve teile, dann erhaelt man den durchschnittlichen Anteil der Wikipediaseiten die eine Seite auf einem Linklevel NEU sieht. Wenn man das dann von einem Linklevel zum naechsten aufaddiert, so sagt dieser kumulative Anteil ganz direkt und ohne Umschweife aus, wieviel Prozent aller Wikipediaseiten im Durchschnitt bis zu dem gegebenen Linklevel gesehen wurden.
Dieser kumulative Anteil ist in der roten Kurve dargestellt und der geht natuerlich bis 100 % (mehr als alle Seiten sehen geht nicht). Fuer die (nicht gestellte) Frage des allerersten Beitrags von Interesse ist, wenn dieser kumulative Anteil 50 % ueberschreitet; wenn es also einem Muenzwurf entspricht, ob bei einer gegebenen Ursprungsseite eine andere Seite schon erreicht wurde.
An der roten Kurve kann man ablesen, dass das im Durchschnitt zwischen dem dritten und vierten Linklevel passiert. Wobei der Wert auf LL3 mit 35 % bereits recht grosz ist und meine Stichproben aus dem allerersten Beitrag …
[…] nach mehreren Versuchen [habe ich] immer drei Verbindungen (in seltenen Faellen zwei oder vier) [erhalten] …
… zu bestaetigen scheint.
Kurzer Einschub: sixdegreesofwikipedia.com benutzt die gesamte Wikipediaseite um die Wege zwischen zwei Seiten zu finden zu finden; also auch die langen Listen mit oftmals nichtmal relatierten Links die am Ende einer Wikipediaseite auftauchen. Ich hingegen schmeisze insbesondere (aber icht nur) Letztere bei meiner Analyse raus, weil mich nur die „Konversation“, also der eigentliche Text, interessiert. Das hat zur Folge, dass der kumulative Anteil „meiner“ Wikipedia ein bisschen nach rechts verschoben sein sollte, weswegen die rote Kurve auf LL3 erst 35 % hat, waehrend mir die Stichproben das Gefuehl geben, dass ich schon ueber 50 % lag.
So weit so gut. Das ist aber nur die eine Richtung; wieviele Schritte muss eine Seite im Durchschnitt machen um irgendeine andere Seite zu sehen. Im Durchschnitt sollte das auch andersrum gelten, also wieviele Schritte muessen ANDERE Seiten machen um die eine Seite zu sehen …
… aber fuer spezifische Seiten gilt das nicht zwangslaeufig. So braucht man drei Schritte um von Magdeburg nach Pencil zu gelangen, aber man schafft den Rueckweg mit nur zwei Schritten
Hier kommt nun die Linkfrequenz ins Spiel, denn diese misst auf welchen Linklevel eine gegebene Seite von anderen Seiten gesehen wird (also der „Rueckweg“ der Situation die den neuen Links entspricht). Leider schlaegt die oben erwaehnte Informationsminderung (die vonnøten war um eine derartige Grøsze ueberhaupt zu messen) hier voll zu. Die Interpretation der Daten scheint zwar einfach und „geradeaus“, aber das muss im Detail betrachtet werden, damit man auch wirklich versteht, warum das rauskommt, was rauskommt.
Weswegen ich das auf das naechste Mal verschiebe.