Zum Jubilaeum (heute vor einem Jahr erschien der allererste Beitrag in dieser nicht ganz so kurzen Miniserie) geht es endlich mal weiter mit Kevin Bacon. Auch wenn die Weise der Publizierung das nicht erkennen laeszt, so habe ich die Auswertung doch monatelang vor mich hergeschoben, weil das so viel ist.
Heute nun steige ich gleich voll ein und verliere mich in einer Sache, die zunaechst wie ein kleines, nicht ganz so wichtiges Detail aussieht. Zumindest erschien es mir so. Dann machte ich aber ein paar Ueberschlagsrechnungen und irgendwie stimmte das Hinten und Vorne nicht. Die Aufklaerung des Mysteriums war eine spannende Sache und legt dann bereits ganz am Anfang SEHR viel ueber das Linknetzwerk der Wikipedia dar.
Das ist als eine Art „Warnung“ anzusehen, dass dies ein laengerer Beitrag wird.
Als kurze Wiederholung:
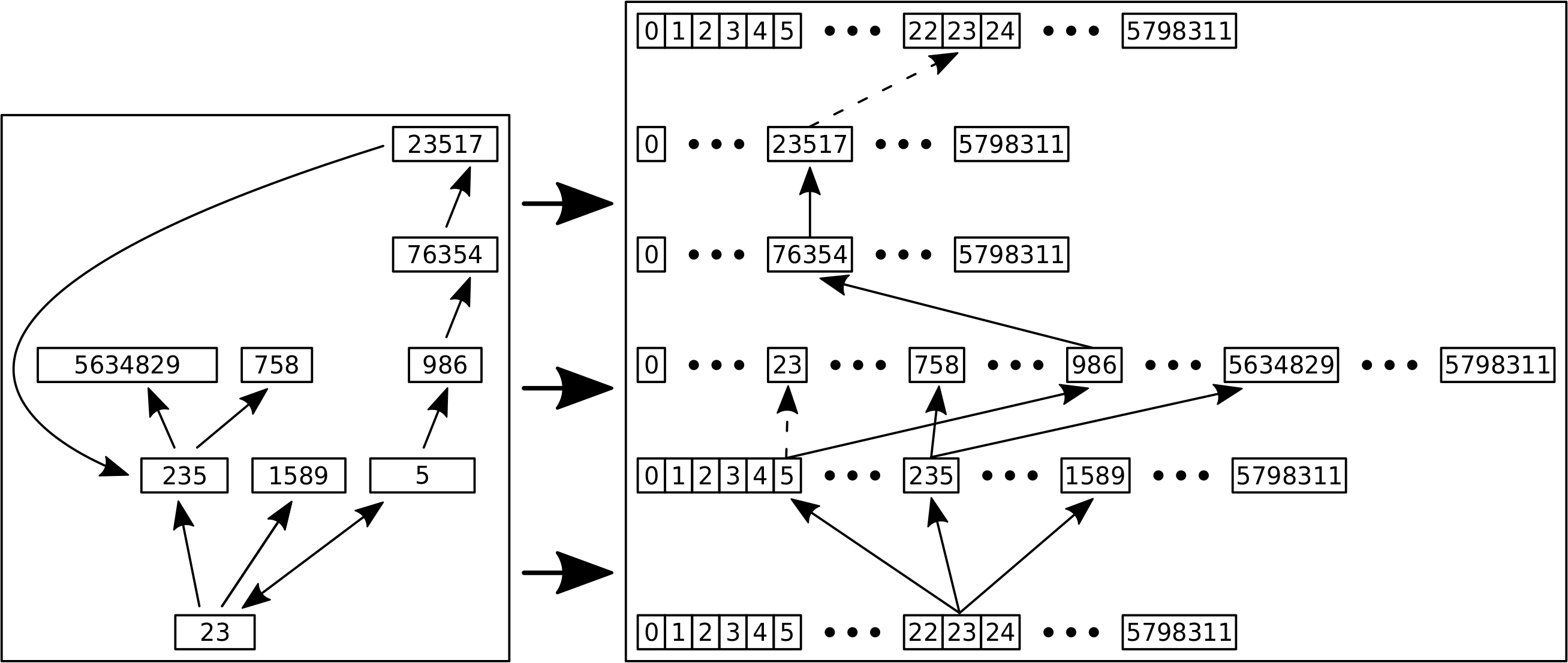
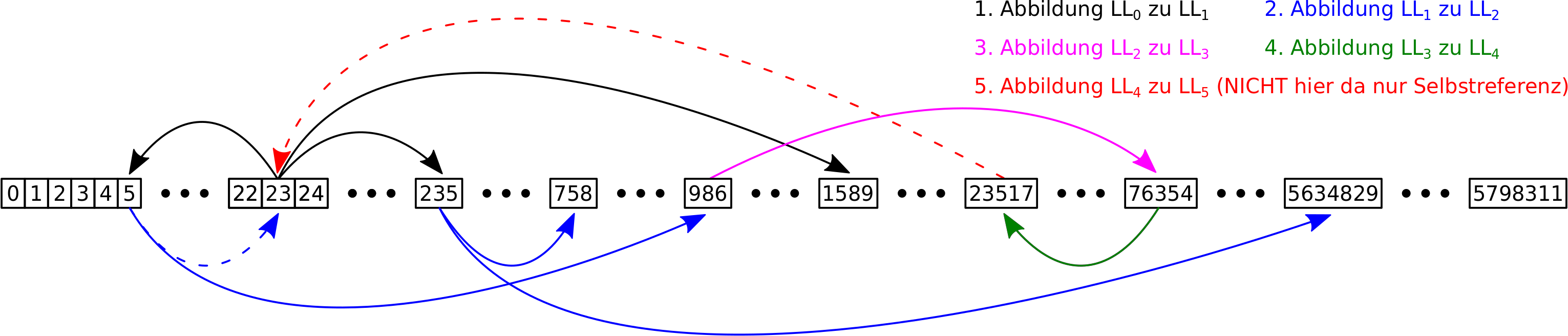
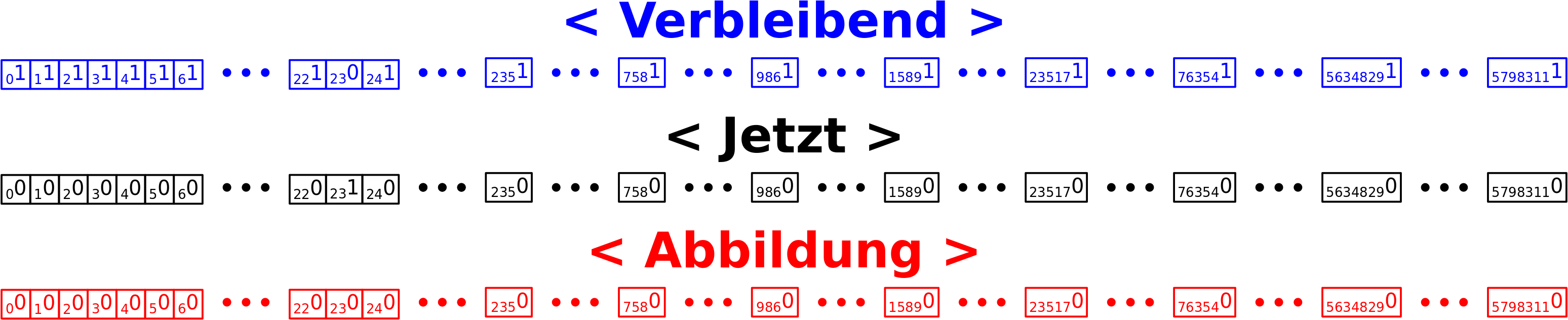
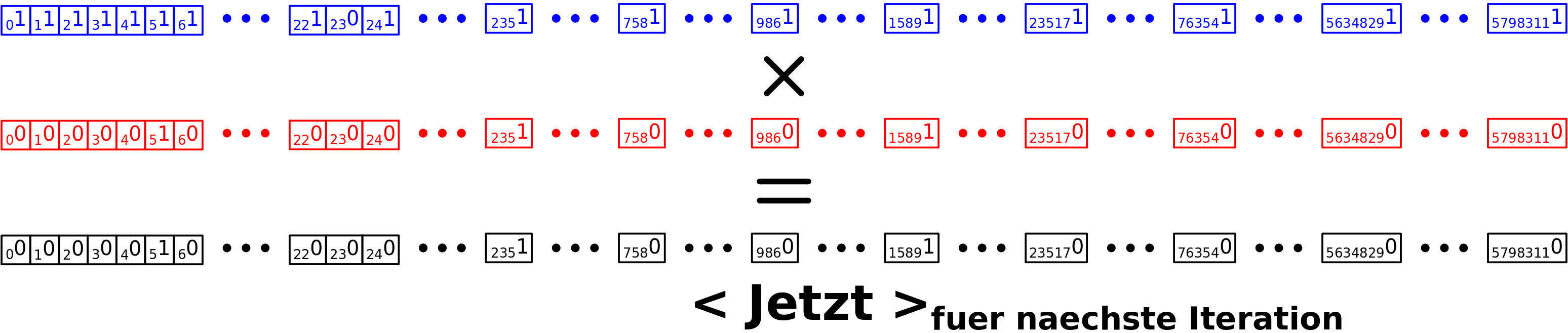
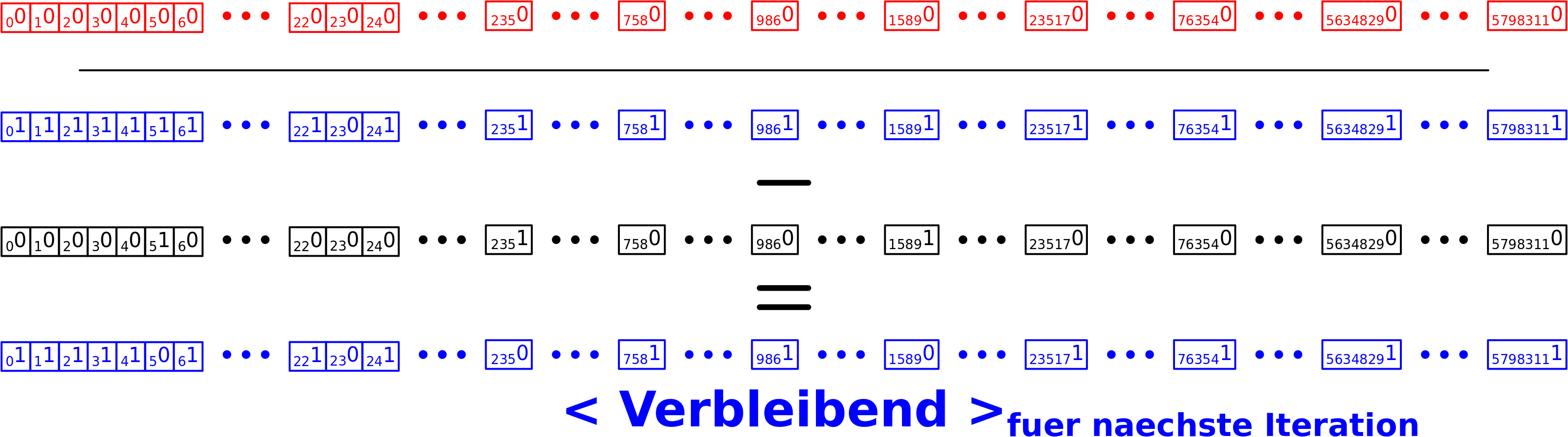
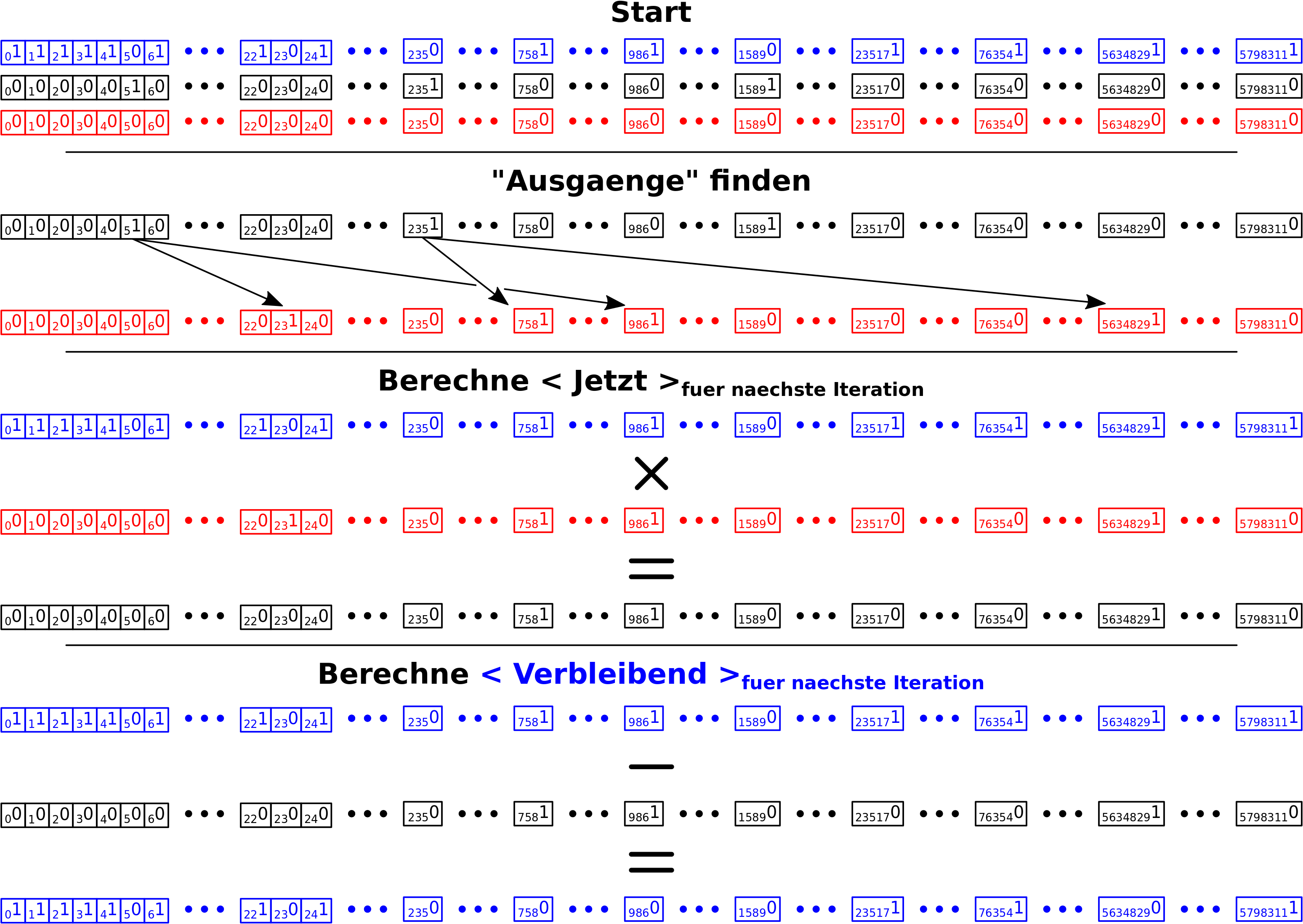
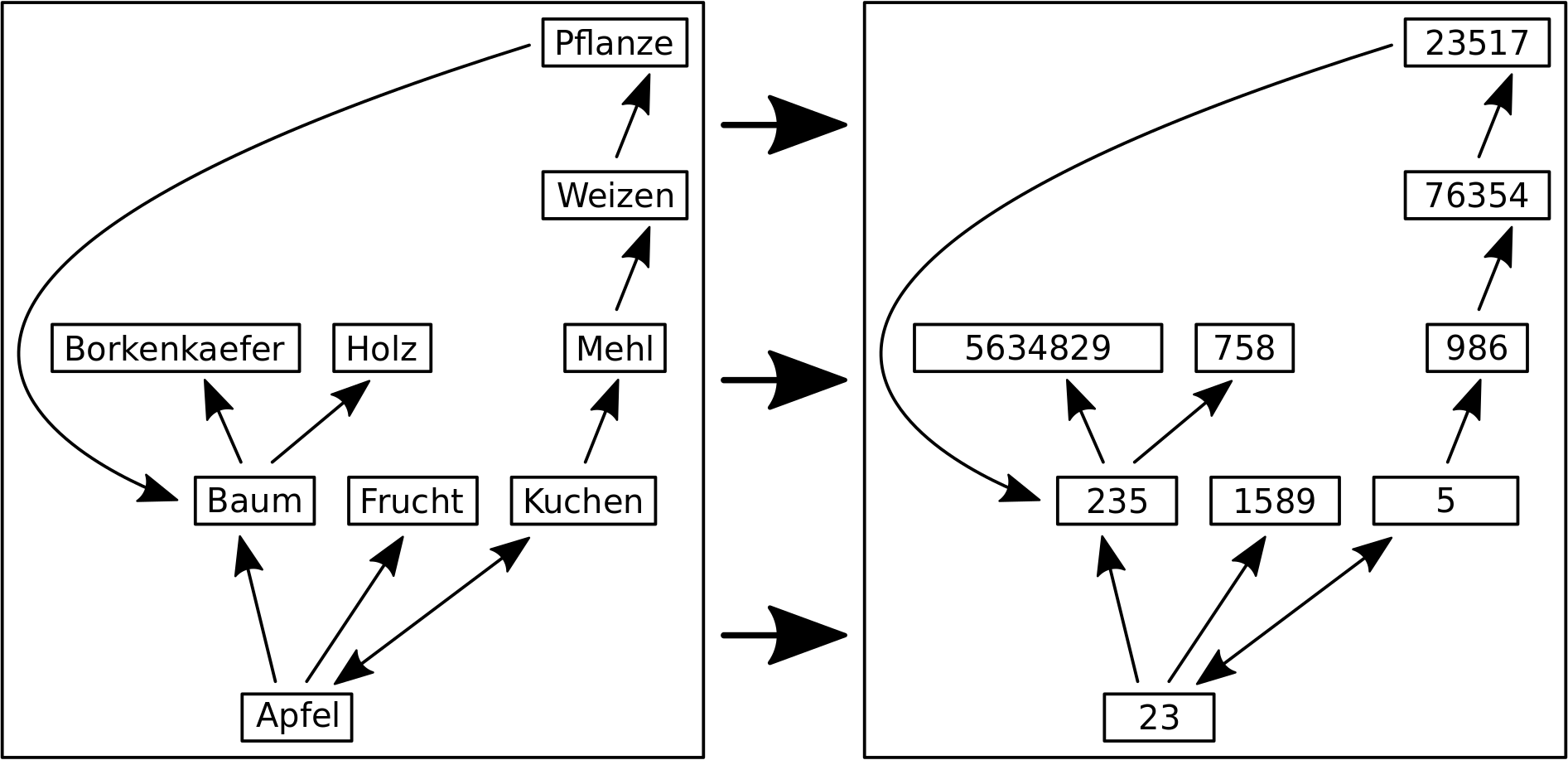
– Ich rede von Linkleveln und die Nummer des Linklevels sagt aus, wie viele „Schritte“ ich im Linknetzwerk getan habe um dort hinzukommen.
– Die Linklevel fangen an bei Null zu zaehlen, was dann natuerlich dem Titel / der Wikipediaseite entspricht, dessen Linknetzwerk ich jetzt gerade untersuche.
– Links die in vorherigen Schritten besucht wurden, werden nicht nochmal besucht.
– Auf jedem Linklevel sammle ich Daten und heute geht es um die totale Anzahl von Links die zum naechste Linklevel fuehren. Siehe dazu mein Artikel von neulich (gut, dass ich den geschrieben habe).
– Ich bin i.A. nicht an einzelnen Seiten interessiert, sondern an der Gesamtverteilung der Grøsze(n) von Interesse ueber alle Titel.
Und nun geht’s los und immer schøn der Reihe nach.
In der Gesamtheit sieht die Verteilung der totalen Anzahl von Links per Linklevel ueber alle Wikipediaseiten so aus:
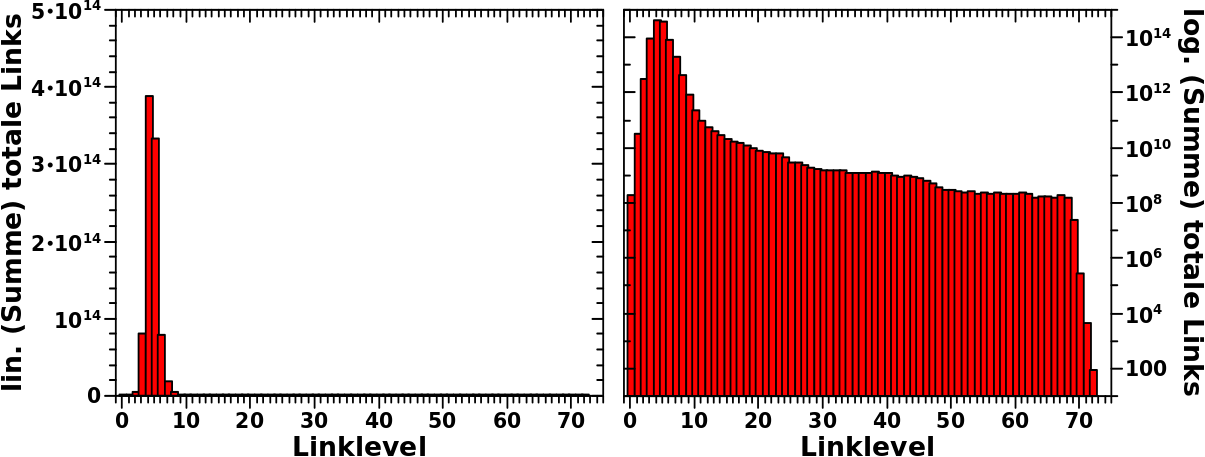
Das sieht einfach aus, denn Verteilungen hatte ich hier ja schon ein paar Mal. Aber wenn man das auf sich wirken laeszt, dann sind da eine Vielzahl von Beobachtungen. Viele dieser Beobachtungen sind allgemein und treten auch so, oder zumindest in aehnlicher Form, bei anderen Grøszen von Interesse auf. Weil wir, also ihr, meine lieben Leserinnen und Leser, und ich, dem hier zum ersten Mal begegnen, møchte ich etwas naeher darauf eingehen.
Wie so oft sehen wir, dass die Darstellung mit linearer Ordinate im linken Bild nicht viel hergibt. Andererseits sehen wir bei lineraer Darstelung, wie schnell alles passiert und dann auch wie schnell alles wieder vorbei ist. Das Maximum ist nach nur vier Schritten erreicht. Und bereits auf Linklevel 3 tuen sich fast 100 Billionen Links auf. Das heiszt bei ca. 6 Millionen Titeln, habe ich nach nur 3 Schritten im Durchschnitt bereits ca. 150 Millionen weiterfuehrende Links vor mir.
Das erklaert natuerlich, warum man die meisten Titel von jedem anderen Titel mittels nur drei (oder vier) Schritten erreichen kann. Das war ja eine ganz konkrete Sache, ueber die ich mich bereits im allerersten Beitrag dieser Reihe (wenn auch nicht direkt) wunderte und die in mir ueberhaupt erst das Interesse an dem ganzen Thema weckte. Damit waere das nach einem Jahr dann endlich geklaert. Toll wa!
Bei logarithmischer Ordinate sieht man dann aber, dass auch nach dem Maximum noch laengst nicht alles vorbei ist. Und ach du meine Guete! Die Dynamik in dieser Verteilung geht von (knapp unter) 100 bis 1014 … das sind 12 Grøszenordnungnen! Das ist so viel, dass ich hier nicht mal mehr die kleinen Striche an der Achse zeichne. Dabei finde ich die doch so toll, weil sie so charakteristisch fuer logarithmische Achsen sind :) .
In Zukunft werde ich Verteilungen mit lineare Ordinaten nur noch zeigen, wenn es zu Informationsgewinn fuehrt. Bei einer solchen Dynamik ist es ziemlich offensichtlich, dass die logarithmische Darstellung der linearen ueberlegen ist.
Auch wenn das Allermeiste nach Linklevel 8 vorbei, so sieht man auch, dass es Wikipediaseiten gibt, die noch viel mehr Schritte benøtigen, bevor man diese erreicht hat. Hier nehme ich dann meine Aussage von oben teilweise zurueck und sage, dass mich dann doch interessiert, welche Seiten das sind.
Aber auch die letzte Ecke des Weltwissens ist nach maximal 73 Schritten erreicht. Der letzte Balken ist auf Linklevel 72 und das bedeutet, dass es nur noch von dort „Ausgaenge“ zu Seiten gibt, die ich vorher nicht besucht habe. Dies wird aber an anderer Stelle genauer betrachtet.
Das sind allgemeine Sachen. Heute von Interesse ist nur das Maximum (man beachte, dass die Ordinate nicht bei Null, sondern erst bei 10 Millionen anfaengt; die Balken sind also „eigentlich“ viel laenger) …
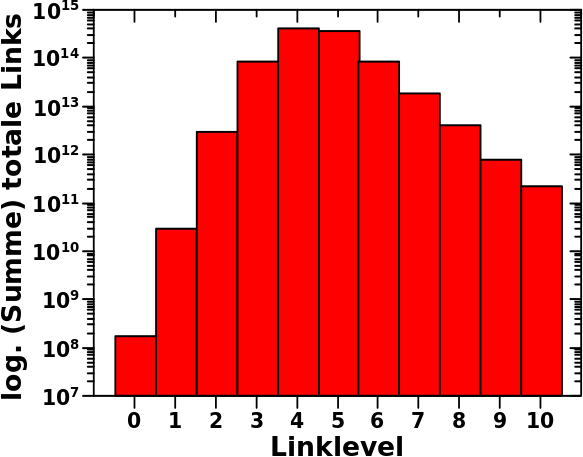
… und eigentlich interessiert mich gar nicht das Maximum an sich, sondern nur der Aufstieg von Linklevel 1 zu Linklevel 2 … und was dies ueber das Linknetzwerk sagt. Aber der Reihe nach.
Auf Linklevel 0 … ach je, das wird mir zu umstaendlich das immerzu zu schreiben und ich kuerz das jetzt mit „LL“ ab und der Wert ist dann der Index … jedenfalls betraegt die Summer der totalen Links auf LL0 165,913,569. Diese Zahl kenne wir schon, denn es ist die Summe aller Links, die ich auf allen Wikipediaseiten finde. Zum ersten Mal sind wir auf diese Zahl bereits vor langer Zeit gestoszen.
Wenn ich nun diese ca. 165 Millionen „Ausgaenge“ zu LL1 nehme, dann treffe ich dort auf mehr als 27 Milliarden Links. Cool wa, wie schnell das waechst! … … … Moment mal! … wieso waechst das denn SO schnell? … Das kommt mir etwas komisch vor.
Und damit sind wir bei dem am Anfang erwaehnten Detail, welches leicht zu uebersehen ist.
Machen wir mal eine Ueberschlagsrechnung. Die ca. 165 Millionen Links auf LL0 verteilen sich auf ca. 6 Millionen Seiten. Das macht ca. 30 Links pro Seite im Durchschnitt … nicht ganz, aber es ist ja nur eine Ueberschlagsrechnung. Wenn ich nun 165 Millionen Seiten auf LL1 mit (durchschnittlich) 30 Links pro Seite multipliziere, dann komme ich auf ca. 5 Milliarden „Ausgaenge“ zu LL2.
Einen Faktor zwei haette ich mglw. als „Fehler“ abgetan, aber ’n Faktor 5 zu viel? Hier scheint ein nicht ganz so offensichtlicher Mechanismus zu wirken … SUPERSPANNEND!
Aber vielleicht ist es doch ganz einfach. Denn mglw. muss ich mit dem Median und nicht dem Mittelwert rechnen … da muss ich mal eine der aelteren Analysen raussuchen … *raussuch* … im Wesentlichen ist’s das hier … øhm … nø … das ist auch nicht des Raetsels Løsung, denn die Haelfte der Seiten haben 15 Links oder weniger … Mhmmmmm … aber Moment … wenn der Mittelwert bei ca. 30 liegt, dann bedeutet das doch, dass Seiten mit (deutlich) mehr als 30 Links pro Seite einen groszen Einfluss haben muessen … mhmmmmm …
Einschub: die Idee mit dem Median war, wenn man mal drueber nachdenkt, von Anfang an zum Scheitern verurteilt … aber das Resultat dieser Idee (der relativ grosze Unterschied zwischen Median und Mittelwert) fuehrte mich letztlich in die richtige Richtung … das ist das Schøne am Erforschen eines Themas … das klappt mitnichten alles beim ersten Mal, aber wenn man was probiert was zu nix fuehrt, wird man mitunter auf Details aufmerksam, die man so vorher gar nicht bemerkt hat … und dann kommt man ueber einen (mehr oder weniger) kurzen Umweg doch noch zur Løsung :) .
Da stellt sich nun die Fragen: wie grosz ist eigentlich der Einfluss vielzitierter Seiten?
Ich stellte die 50 meistzitierten Seiten bereits vor. Und eine Seite, die bspw. 1000 Links hat und 300-tausend Mal zitiert wird, wuerde zum Gesamtsignal 300 Millionen Links — also ca. 1 % — beitragen. Gleichzeitig wissen wir, dass das Maximum der Verteilung der Zitierungen bei eins liegt, waehrend das Maximum der Links pro Seite bei ca. 10 liegt. Diese zwei Dinge zusammen fuehren dazu, dass ich fuer die gleiche Signalstaerke die die 300-tausend Mal zitierte Seite hat, 30 Millionen Seiten braeuchte, die ein Mal zitiert werden (mit 10 Links pro Seite). So viele gibt es gar nicht und um besagte Signalstaerke zu erreichen muesste ich alle Seiten zusammen nehmen, die einmal, zweimal, dreimal, … neunmal, zehnmal zitiert werden.
Diese kurze und einfache Ueberlegung zeigt bereits, wie krass ueberproportional der Einfluss nur einer vielzitierten Seite sein kann. Aber die 1000 Links oben habe ich mir nur ausgedacht und es stellt sich die naechste Frage: wie sieht denn die Anzahl der Links in Abhaengigkeit von den Zitierungen aus?
Nun ja, das ist etwas unuebersichtlich und sieht so aus:
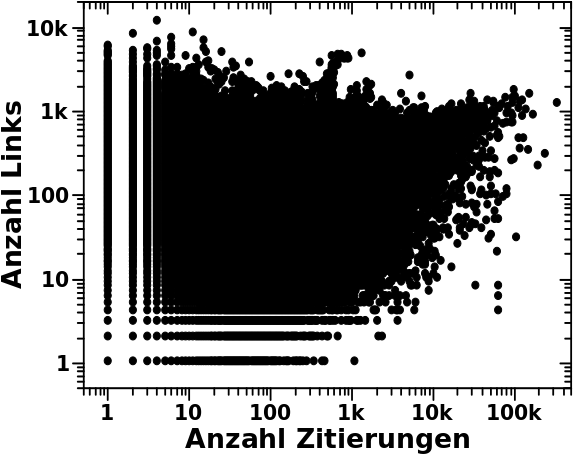
Wir sehen, dass wir erstmal nix sehen, auszer einem groszen schwarzen Fleck.
Der schwarze Fleck kommt durch die Ueberlappung sehr sehr sehr vieler Datenpunkte zustande. Wobei ich die Punkte fuer null Zitierungen bzw. null Links weggelassen habe, weil die hier nicht relevant sind.
Wenn man sich alles mal genauer anschaut, dann sieht man, dass die Seite mit den meisten Zitierungen tatsaechlich ca. 1000 Links hat. Das war aber reiner Zufall.
Desweiteren sieht man, dass Wikipediaseiten selten deutlich mehr als 1000 Links haben und dass die Anzahl der Links unabhaengig ist von der Anzhal der Zitierungen fuer Seiten die weniger als ca. 1000 Zitierungen auf sich vereinen.
Ab ca. 1000 Zitierungen haben die entsprechenden Seiten aber anscheinend eine Art „Mindestanzahl“ an Links, in Abhaengigkeit von der Anzahl der Zitierungen. Das sieht man an der schraeg liegenden „Abbruchkante“, welche die „Mindestanzahl“ an Links festlegt, die eine Seite haben „muss“, wenn sie bspw. 50-tausend Zitierungen auf sich vereint.
Das war erstmal ein _aeuszerst_ (!) ueberraschendes Ergebniss. Damit hatte ich nicht gerechnet. Ohne weitere Vorannahmen gibt es dafuer auch gar keinen Grund, denn warum sollte eine vielzitierte Seite nicht nur einen Link haben. Und das sieht man ja auch bspw. an den drei vertikalen Punkten bei ca. 60-tausend Zitierungen. Das sind drei so oft zitierte Seiten mit weniger als 10 Links.
Andererseits ist dieses Ergebniss dann doch nicht so ungewøhnlich wenn man bedenkt, dass vielzitierte Seiten vermutlich (eben wegen deren Popularitaet) sehr gut kuratiert sind. Das bedeutet dann, dass in diesen Artikeln vermutlich jedes kleine bisschen verlinkt ist. Je populaerer ein Artikel ist, um so mehr beinhaltet dieser vermutlich, was dann wiederum zu mehr Links fuehrt.
Dennoch, dies war eine spannendes Resultat, eben weil mich das so ueberrascht hat.
Wie genau hilft uns dies nun aber mit der obigen Frage? Nun ja, das ist ganz einfach. Ich muss fuer jede Wikipediaseite das Produkt aus der Anzahl der Links und der Anzahl der Zitierungen bilden. Die Summer aller dieser Produkte sollte dann die ca. 27 Milliarden| totalen Links von LL1 zu LL2 ergeben.
Aber an dieser Stelle breche ich ab. Es muss noch ziemlich viel erklaert werden und der Beitrag ist jetzt schon so lang.