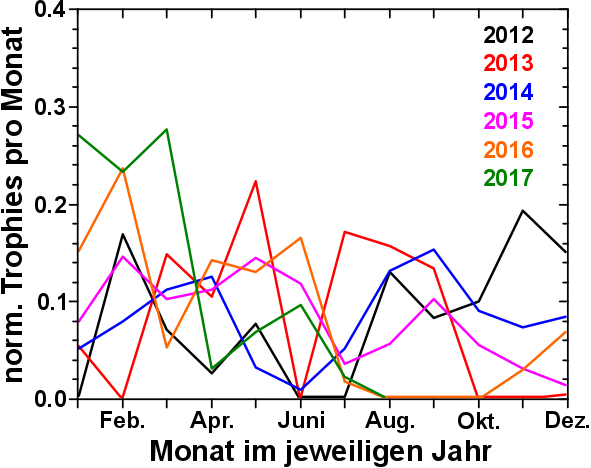
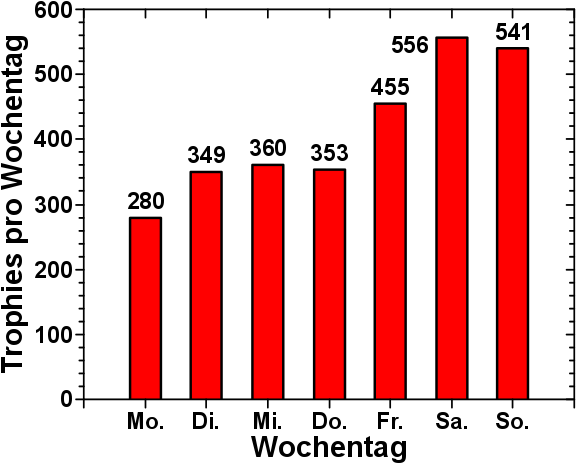
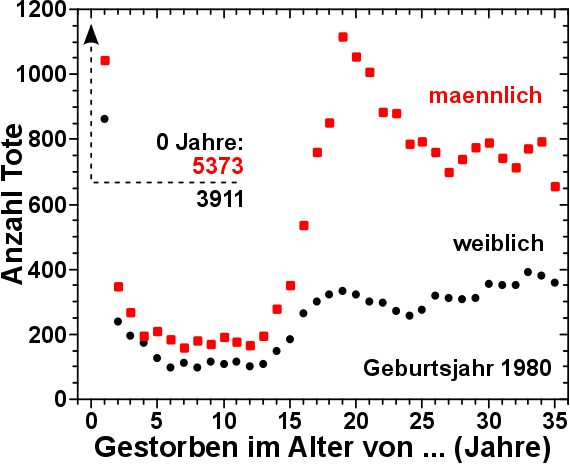
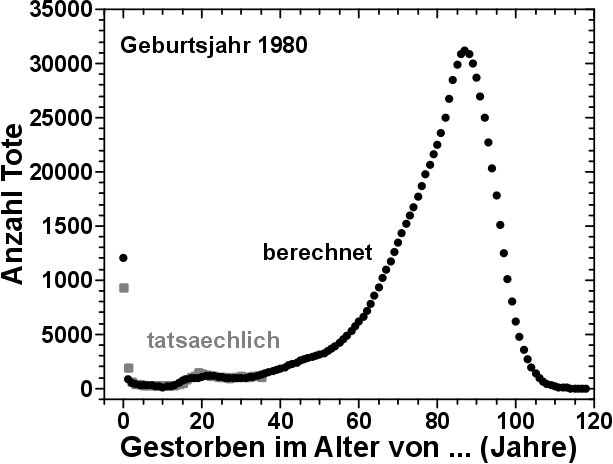
1. Satz: Ich weisz nicht, wie ich das was hier am Ende stehen wird, in Worte fassen kann.
2. Satz: Ich werde mich wie immer irgendwie durchwurschteln und hoffe einfach, dass ein halbwegs kohaerenter Beitrag dabei zustande kommt.
Also: Das Folgende ist bisher nur so ’ne Art „Gefuehl“ … zwar durchaus bestaetigt, wenn man „die Fakten“ auf eine gewisse Art und Weise interpretiert, aber insgesamt kann ich nicht mit dem Finger drauf zeigen, was ich eigtl. meine.
Dies ist bestimmt auch deswegen so, weil bei dem groszen Thema zu dem die unten erwaehnten Dinge gehøren, viel von dem wie ich sozialisiert wurde (bzw. mich selbst sozialisiert habe) irgendwie in Frage stellt. Dito bzgl. vielen der Identifikation stiftenden Grundeinstellungen der Gruppen zu denen ich mich (auf die eine oder andere Weise) zugehørig fuehle.
Es fuehlt sich aber wichtig an, weswegen ich das hier mal so aufschreibe, wie es mir durch die Finger flieszt.
Normalerweise erwaehne ich nicht, wann genau ich Artikel schreibe. Aber irgendwie scheint mir das heute relevant: 2017-10-08. … .oO(Mir ist nach Musik) … *I’m along for the ride*
Los geht’s:
Alle Doktoranden hier muessen am Kurs „Forschungsmethodik, Wissenschaftstheorie und Ethik“ teilnehmen. Find ich gut, aber mich duenkt, dass die Meisten das als Zeitverschwendung ansehen, von ganz wenigen Leuten abgesehen. Ich fand den Kurs ganz dolle toll … und mich duenkt die Professoren freuten sich, dass da auch mal wer war, der mehr fragte als, wie viele Seiten denn der Report haben soll.
Besagter Report handelte ueber das Thema, welches ich im Moment auf Arbeit bearbeite. Wie ich nun mal bin, nutzte ich diese Møglichkeit um ein bisschen auf die Nacktheit des Kaisers aufmerksam zu machen. Denn auch wenn ich den Abschnitt „Ethical Issues“ ganz richtig mit …
[t]he PhD-project itself, and the work that has to be done within the scope of it, exhibit no ethical issues
… beginne, wollte ich doch das Folgende sagen (Zitatnummern sind dem Kontext hier angepasst und folgen am Ende des laenglichen Zitats).
However, I’d like to use this chapter to draw attention to an issue with ethical implications in a larger context.
In his widely recognized work „Capitalism, Socialism and Democracy“ [1] the austrian economist Joseph Schumpeter argues that in a capitalist society innovation is the cause for progress and improving standards of living for all members of society. History has shown this point of view time and time again correct. Nowadays it can be said that public opinion helds the view that the benefits of innovation are not just something desirable but that the process of innovation is necessary for the society as a whole. It is widely assumed that patents promote innovation. Since the results of this PhD may be patented, I’d briefly like to present some research that suggests the opposite, for the implementation of the patent system as it exists today.
Torrance and Tomlinson [2] point out that „little empirical evidence exists to support this assumption“. On the contrary they found that a „[…] patent [system] […] generates significantly lower rates of innovation […], productivity […], and societal utility […] than does a commons system“. They state that this is „[…] inconsistent with the orthodox justification for patent systems“ but at the same time it does „[…] accord well with evidence from the increasingly important field of user and open innovation“.
Bessen and Meurer [3] found that „[…] the empirical economic evidence strongly rejects simplistic arguments that patents universally spur innovation and economic growth“. More specific they write that the „[…] direct comparison of estimated net incentives suggests that for public firms in most industries today, patents may actually discourage investment in innovation“.
By researching the influence of so called intellectual property rights, within the context of the Humane Genome Project, on subsequent innovation,
Williams [4] comes to similar conclusions that „[intellectual property rights on genes] had persistent negative effects on subsequent innovation relative to […] genes having always been in the public domain“.
Galasso and Schankerman [5] found that „[…] this effect is concentrated in patents owned by large firms“.
However, I personally think that the idea to give incentives to innovate, which lead to the „invention“ of patents, is a good idea. Also are patents not a bad thing per se. Parts of society, politics and science are aware of this dilemma and discussing alternatives to the current implementation of the patent system, so that the beneficial effects of incentives for the innovator on innovation are not abandoned [6].
With respect on what Joseph Schumpeter wrote and public and political opinion believes to be crucial for society I felt it important to contribute to this discussion by highlighting this matter a bit.
However, neither being a sociologist, economist, lawyer or politician I can unfortunately not elaborate further on this subject.
[1] J. A. Schumpeter, Capitalism, Socialism and Democracy. HarperCollins United States, 1942.
[2] A. W. Torrance et al., Patents and the Regress of Useful Arts, Columbia Science and Technology Law Review, vol. 10, pp. 130–168, 2009.
[3] J. E. Bessen et al., Do Patents Perform Like Property?, Boston Univ. School of Law Working Paper, no. 8, 2008.
[4] H. L. Williams, Intellectual Property Rights and Innovation: Evidence from the Human Genome, Journal of Political Economy, vol. 121, no. 1, pp. 1–27, 2013.
[5] A. Galasso et al., Patents and Cumulative Innovation: Causual Evidence from the Courts, The Quarterly Journal of Economics, vol. 130, no. 1, pp. 317–369, 2015.
[6] S. Shavell et al., Rewards Versus Intellectual Property Rights, Journal of Law and Economics, vol. 44, pp. 525–547, 2001.
.oO(Und nun ist aus dem „das wird nur was Kurzes“ bereits etwas Laengeres geworden und ich bin noch nicht mal da, wo ich eigtl. hin will.)
Dies fasst im Wesentlichen meine Meinung bzgl. Patenten zusammen: Pfui Pfui! Ein Werkzeug kapitalistischen Machterhalts, welches uns all das Schøne was Sein kønnte kaputt macht!
Nun gibt es aber eine Ausnahme zu der ganzen Sache: ich bin mir ziemlich sicher gelesen zu haben, dass Patente erst dann „bøse“ werden und Fortschritt faktisch verhindern, wenn diese Firmen gehøren, die im Schnitt mehr als 10 Patente haben. Das gilt also im Wesentlichen nicht fuer sogenannte Start-Up Unternehmen.
Eine Quelle muss ich schuldig bleiben. Mich duenkt ich las das in „The Case Against Patents“ von Michele Boldrin und David K. Levine im Journal of Economic Perspectives, 2013, vol. 27, no. 1, pp 3–22, finde das aber beim schnell drueberlesen gerade nicht.
Wieauchimmer, erstmal tat dieser spezielle Fall nicht viel zur Sache. Halte ich doch von dem Hype um „Technologietransfer“ und „wir brauchen mehr Gruender“ und solcherart Gerede nicht viel. Bin ich doch eher der Meinung, dass dieser „Ethos“ dahinter insgesamt schaedlich fuer die Gesellschaft ist. Dies deswegen, weil ich der festen Ueberzeugung bin, dass sich unsere eigentlichen Probleme NICHT technisch løsen lassen!
Dann aber stolperte ich ueber den lesenswerten Artikel „It’s the cities, stupid„.
Dort wird (durchaus plausibel) argumentiert, dass alles was wir unter „Volkswirtschaft“ zusammenfassen das eigentliche Phaenomen hinter „erfolgreicher Wirtschaft(spolitik)“ total „verschmiert“.
Im Wesentlichen geht es darum, dass der Fortschritt und der Wohlstand einer Nation nicht von der ganzen Nation selber, sondern von den erfolgreichen Staedten ausgeht. Dass die Staedte, mit all ihren (oft genug noch eher „mysteriøsen“) Wirkmechanismen, die „Zugpferde“ sind, an denen wir alle haengen.
Wann immer wir also Smith, Keynes, Hayek, Friedman, Marx usw. usf. høren, dann handelt es sich dabei zwar um das „Grosze und Ganze“, aber die Ursachen sind nicht so wirklich richtig zugeordnet. Und das ist natuerlich dumm. Denn wenn man die eigentlichen Ursachen eines Phaenomens nicht kennt, dann endet das im schlimmsten Fall so wie bei Scott.
Ein ganz konkretes Beispiel handelte darueber, wie immer wieder Staedte deswegen zu besagten „Zugpferden“ werden, weil „junge Unternehmen“ nicht an die Materialien, Werkzeuge, Fertigkeiten etc. pp. herankommen die sie benøtigen und das deswegen dann eben in der Stadt selber „implementieren“ muessen. Seien es Spezialwerkzeugmacher oder theoretische Kurse. Dadurch wird eine Grundlage an vorhandem „Wissen“ geschaffen, welches auch fuer nachfolgende Generationen (nicht nur die menschlichen, sondern auch die technischen) von unabschaetzbarem Wert ist.
Dies aber ist genau das, was am Ende von „wir brauchen mehr Gruender“ stehen kønnte. Auch wenn ich mir ziemlich sicher bin, dass die politisch, økonomisch und ideologisch dafuer Verantwortlichen sich dem nicht bewusst sind.
Und hier bin ich dann wieder zurueck bei den Patenten. Die sind gut fuer Start-Ups und (viele) Start-Ups sind (auf andere als die propagierte direkte Weise (a la „mehr Arbeitsplaetze“)) gut fuer den Fortschritt.
… … …
Das war jetzt eher laenglich, ist aber die eine Sache.
Da wollte ich eigentlich keinen Beitrag draus machen. Besagter Schwierigkeiten das in Worte zu fassen wegen.
Dann aber las ich bzgl. der Blockchain(-Technologie):
[…] blockchain is not a “disruptive” technology, which can attack a traditional business model with a lower-cost solution and overtake incumbent firms quickly. Blockchain is a foundational technology: It has the potential to create new foundations for our economic and social systems.
Tja! Was soll ich nun daraus machen? Bis dahin hielt ich nicht so viel von „der Blockchain“. Dies ist vor allem dem Hype um Kryptowaehrungen wie bspw. „Bitcoin“ geschuldet. Kommt mir das doch alles so vor der „Kleinanlegerboom“ damals, als die T-Aktie angeblich so toll war und viele gutglaeubige Menschen ihr Geld verloren (und die ueblichen Verdaechtigen da (wie immer) fett dran verdienten).
Aber neue Grundlagen fuer unser System. Das ist doch das, wo ich mich wieder und wieder und wieder und wieder und wieder und wieder drueber auslasse!
Also noch so’n Ding, was mir ein bisschen unangenehm war, weil es nicht so richtig in mein Narrativ passt.
Aber auch hiermit wollte ich noch nicht so richtig drueber schreiben.
… … …
Und dann aber stolperte ich ueber einen Kommentar mit dem Titel „Fuck Uber’s Haters„, den ich absolut empfehle zu lesen.
Dort wird im Wesentlichen argumentiert, dass vieles von dem was mir uns den Gruppen denen ich mich irgendwie zugehørig fuehle „lieb und teuer“ ist — gerne zusammengefasst unter dem warmen und kuscheligen Begriff „soziale Verantwortung“ — irgendwie als Werkzeug des Machterhalts benutzt wird. Und auch wenn ganz konkret Uber mglw. schon sehr schlimm ist, so ist vielleicht das was wir als „Gut und Richtig“ gelernt haben nicht nur obsolet, sondern vielleicht ganz furchtbar schaedlich, wenn wir schnell und mit møglichst wenigen Schaeden, Leid und Schmerzen durch diese Uebergangszeit kommen wollen. Ihr wisst schon: Roboter und kuenstliche Intelligenz und so.
Nun ja … ich habe also nur so ein paar Puzzlestuecke und all die kleinen Sachen fuehlen sich irgendwie so wichtig an, dass ich das hier mal niederschreiben wollte. Und dann gilt natuerlich auch das, worueber dieser Beitrag handelt.
Ich bitte zu entschuldigen, dass es eher „konfus“ und ungeordnet ist und dass ich nicht so richtig den roten Faden zwischen den verschiedenen Teile finde.
… … …
Ach ja, eine Sache noch. Den Bericht, aus dem ich mich ganz Oben selbst zitiere, fanden die fuer den Kurs Verantwortlichen so toll, dass die mich fragten, ob sie den als Beispiel fuer nachfolgende Jahrgaenge benutzen duerfen. Duerfen sie natuerlich … und somit lesen mglw. ein paar mehr Leute etwas ueber die Schlechtigkeit des Patentsystems in der heutigen Implementierung. … Tihihi … Tropfen und Stein und man muss die Leute mit Ideen konfrontieren, von denen sie bisher noch nichts gehørt haben und die am Besten nicht in ihr „Konzept“ passen und so Zeug … also ganz wie das, worueber dieser Artikel hier irgendwie (auch) handelt :)