Das zweite Diagramm beim letzten Mal zeigte die linklevelabhaengigen Linkfrequenzen dreier Beispielseiten. Die Summe ueber alle Linklevel einer Seite war da weit unter 1000. Dies im starken Gegensatz zu allem was ich davor gesehen hatte. Die drei Beispiele sehen alle aus als ob das Archipelseiten sind (ohne das zu pruefen … ist nur so’n Bauchgefuehl weil ich mich ja jetzt ein bisschen damit auskenne) und entsprechend schrieb ich:
Das bringt mich aber auf eine Idee, ob ich damit nicht alle Archipelseiten auf einfache Art und Weise identifizieren kønnte.
Mit „damit“ meine ich die Summe ueber alle Linklevel einer Seite (in diesem Fall fuer die Linkfrequenz) und die erste Frage ist nun, warum das mglw. klappen kønnte.
Eine kurze Ueberlegung nimmt die (oben nochmals verlinkten) individuellen Linkfrequenzverteilungen dreier Seiten des „São Paulo FC“-Artefakts heran.
Diese Seiten gehøren zu den am wenigsten zitierten Seiten die aber dennoch Teil des gesamten Wikipedianetzes sind (also NICHT zum Archipel gehøren). Das ist so, weil alle (anderen) Seiten nie direkt dorthin zitieren. Jedes Jahr des Artefakts kann nur ueber des jeweils spaetere Jahre zitiert werden. Jede Artefaktseite erhaelt also von jeder anderen Ursprungsseite maximal ein Zitat. Reflexionen lasse ich der Einfachheit mal auszen vor, bzw. kønnte man auch nur das Jahr 1930 des Artefakts betrachten, denn dieses hat keine Reflexionen in der Linkfrequenz.
Die Summe der Linkfrequenzen ueber alle Linklevel betraegt demnach mindestens 5.5 Millionen (sogar etwas mehr) fuer solche Seiten.
Seiten die zwei Mal zitiert werden sieht man in der roten und schwarzen Kurve im zweiten Diagramm des selben Beitrags. Das sind die, bei denen sich „Metaartefakte“ im Schwanz bemerkbar machen, weil die dort nochmal massiv zitiert werden. Die Summe der Linkfrequenz ueber alle Linklevel verdoppelt sich also (so ungefaehr).
Eine Verdopplung ist das Maximale was in dem Fall passieren kann, denn die zwei Peaks kønnten sich auch ueberlagern und dann waere es weniger als das Doppelte. Das Wichtige ist, dass die obigen 5.5 Millionen eine harte untere Grenze sind, unter die keine Seite kommt, wenn diese irgendwie aus dem gesamten Linknetzwerk zu erreichen ist.
Und das ist der Clou, denn Archipelseiten sind NICHT aus dem gesamten Linknetzwerk zu erreichen. Es ist ja gerade das Merkmal der Seiten aus denen das Archipel besteht, dass diese (wenn ueberhaupt) _nur_ von anderen Archipelseiten zitiert werden, waehrend sie im Allgemeinen aber durchaus auch „nach drauszen“ linken .
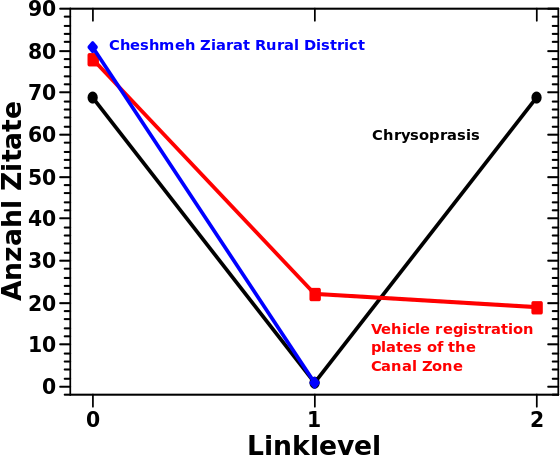
Und deswegen nehme ich an, dass die Summe ueber alle Linklevel einer Seite bei den Linkfrequenzen von Archipelseiten immer unter obiger Grenze liegt. In den allermeisten Faellen sogar drastisch darunter, also bei null oder eins oder zwei oder vielleicht auch mal zehn oder 69 wie bei Chrysoprasis beim letzten Mal.
Ich gebe aber zu, dass das vor allem eine praktische Ueberlegung ist, mit Wissen darueber wie das Archipel aussieht. Prinzipiell kønnte eine Archipelseite ueber den Grenzwert kommen, wenn es eine starke Vernetzung gibt und besagte Seite von vielen (Archipel-)Ursprungsseiten auf mehreren Linkleveln zitiert wird. Da gibt es konzeptionell keinen Unterschied zum Rest des Wikipedianetzwerkes. Aber wie gesagt, so sieht das Archipel nicht aus.
Die naechste Frage ist, warum ich das wuerde machen wollen, denn ich habe doch alle Seiten des Archipels bereits identifiziert.
Der Grund liegt darin dass die dortige Identifizierung eher umstaendlich war. Sowohl vom Konzept, als auch von der Implementierung.
Mir hat das natuerlich Freude bereitet, war es letztlich doch ein intellektuelles Puzzle. Aber insbesondere die Implementierung hatte ihre Schwaechen, denn ich musste rekursiv oft ueber viele Daten „fahren“ um Archipelseiten zu identifizieren. Die Schwaeche liegt dabei nicht in der Rekursion, diese machte eher den grøszten Reisz fuer mich aus … auch wenn viele Leute das mglw. anders sehen. Aber das „oft ueber viele Daten fahren“ dauert sehr lange. Mitunter mehrere Stunden, was das Testen und Ausprobieren arg beschraenkt. Deswegen setzte ich eine Limitierungen bei der ich annahm, dass wenn ein Netzwerk von zitierenden Seiten grøszer als so und so viele zitierende Seiten ist (bspw. 100), die Ursprungssite høchstwahrscheinlich nicht zum Archipel gehørt.
Das ist eine durchaus sinnvolle Annahme denke ich und ich testete den maximalen Wert fuer die Limitierung, bis es nicht mehr sinnvoll war (einfach, weil es zu lange dauerte). Ab einem Wert von ca. 100 zitierenden Seiten (also nahe an den Werten der drei Beispiele vom letzten Mal) sah ich dann keine Veraenderungen mehr, es schien also als ob alle Archipelseiten weniger Zitate erhalten als das Limit erlaubt. Aber eine Garantie ist das natuerlich nicht, mir kønnten durchaus Archipele „entkommen“ sein.
Wieauchimmer, die Summe ueber die alle Linkfrequenzen einer Seite zu bilden und zu schauen ob diese (weit) unter einem Grenzwert liegt ist natuerlich deutlich einfacher, viel schneller und einfach zu implementieren. Und wie immer interessieren mich einzelne Seiten weniger sondern die Verteilung dieser Summen.
Daraus stellt sich dann gleich die dritte Frage: worin liegt denn der Unterschied zu den bisherigen Summenverteilungen?
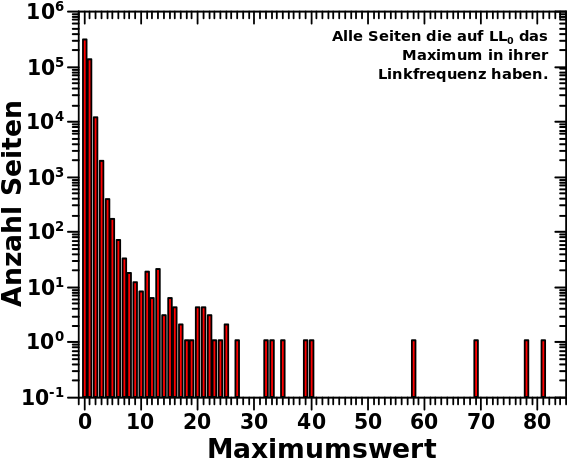
Nach all dem oben Geschriebenen sollte das einfach zu verstehen sein: bei allen vorherigen Summenverteilungen summierte ich fuer jedes Linklevel ueber alle Seiten. Das fuehrte zu linklevelahaengigen Verteilungen mit maximal 73 Werten. Hier aber summiere ich (wie bereits erwaehnt) ueber alle Linklevel einer Seite und das sollte bei ca. 6 Millionen Seiten zu einer Verteilung mit deutlich mehr als 73 Werten fuehren. Kurioserweise nur deswegen weil es das Archipel gibt, aber dazu mehr weiter unten.
Als Letztes stellt sich dann die Frage, warum ich das nicht schon mit den totalen / neuen Links bzw. den Selbstreferenzen gemacht habe.
Nun das ist ganz einfach zu beantworten: weil das nicht sinnvoll erschien … aber fuer die Begruendung der Antwort muss ich etwas ausholen und ich fange mit den totalen Links an.
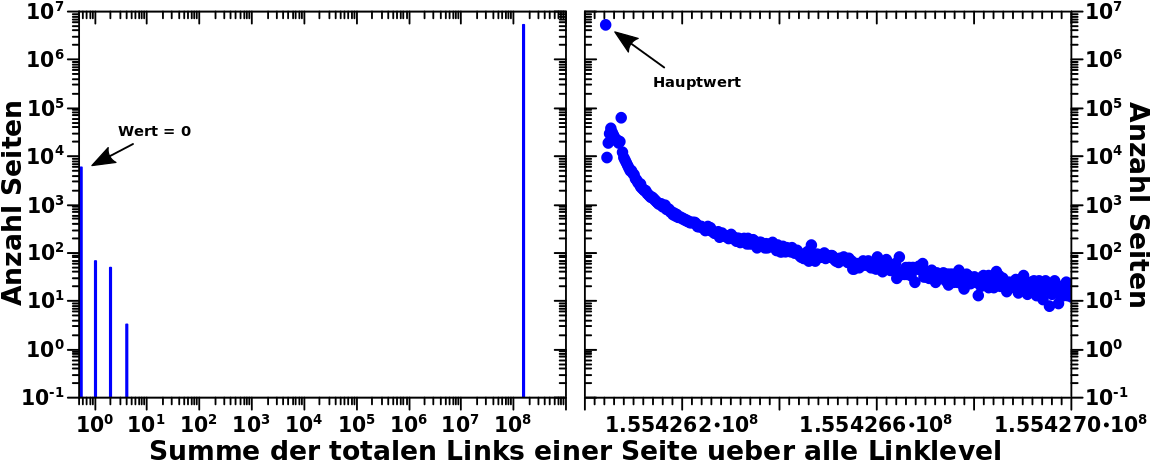
Zunaechst lasse ich die Archipelseiten auszen vor. Dies auch deswegen, weil ich vom Archipel noch nicht mal etwas ahnte, als ich die totalen Links genauer untersuchte. Unter der Annahme, dass es kein Archipel gibt, sollte die Verteilung der Summen ueber die totalen Links genau zwei Werte haben: Null und ungefaher 165 Millionen.
Der Wert Null kommt durch die Seiten zustande die zwar zitiert werden, aber selber keine Links haben. Hier sollten sich nur ein paar tausend Seiten tummeln. Der weitaus grøszte Anteil der Seiten sollte sich beim Wert von ca. 165 Millionen Wert aufhalten, denn das ist natuerlich genau die Anzahl aller Links ueber alle Seiten. Dies folgt daraus, weil jede Seite im Linknetzwerk zu jeder anderen Seite kommt and dadurch alle Links sieht. Das heiszt aber auch, dass jede Seite am Ende ihres Linknetzwerkes die selbe Anzahl an totalen Links gesehen hat wie jede andere Seite.
Daraus folgt, dass es nur zwei Werte geben sollte und das war der Grund warum ich das damals nicht machte.
Wie man im linken Diagramm dieses Bildes sieht, ist das auch tatsaechlich (fast) so:
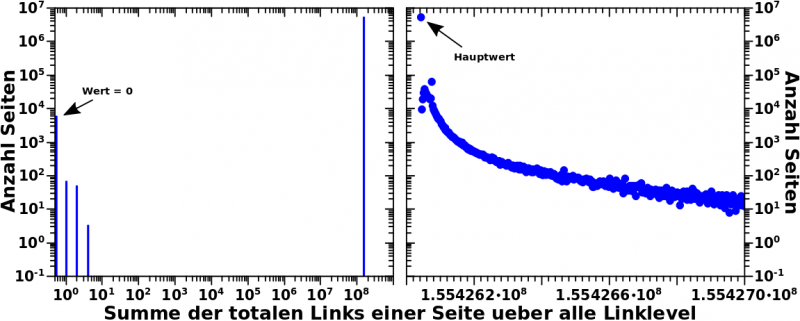
Mein Bauchgefuehl sagt mir, dass das schon stimmt mit den ca. 5500 Seiten beim Nullwert. Die ca. 6 Millionen Seiten die sich bei einem Wert von knapp unter 200 Millionen versammeln sind ja genau wie „vorhergesagt“. Und auch wenn ich mich wiederhole: dieses Ergebnis bestaetigt, dass es nicht sinnvoll war die „neue Summe“ ueber die totalen Links zu bilden.
Diese Aussage stimmt nur noch bedingt, wenn man Archipele mit in die Betrachtungen einbezieht, denn diese fuehren zu mehreren (relativ kleinen) Modifikationen.
Zum Einen ist obiger zweiter Wert um ein paar Millionen Seiten kleiner als theoretisch angenommen. Das Archipel besteht aus ungefaehr 500-tausend Seiten und im Durchschnitt hat jede Seite so 10 bis 30 Links. Die durchschnittliche Anzahl an Links pro Seite (und die Nachteile dieses Ansatzes) wurde bereits mehrfach diskutiert, ich finde auf die Schnelle aber nicht wo genau das war. Wenn man sich in der Mitte bei 20 Links pro Seite trifft, fuehrt das zu einem um 10 Millionen kleineren Hauptwert. Und das ist auch das was man sieht … zuegegeben, nicht im linken Diagramm, aber wenn man reinzoomt (so wie im rechten Diagramm, mehr dazu weiter unten), dann ist das tatsaechlich so.
Zum Zweiten wuerde ich vermuten, dass mglw. ein paar niedrige Werte in der Verteilung dazu kommen. Dabei wuerde es sich um Archipelseiten handeln, die bspw. Links zu nur einer oder ein paar wenigen andere Seiten haben und von dort zurueck zitiert wird und wenn keine einzige dieser Seiten einen Link zum groszen Wikipedianetzwerk hat. Davon sollte es aber nicht viele geben, denn es ist selten, dass eine Seite nicht irgendwie ins grosze Linknetzwerk zitiert, selbst wenn sie von da keine Zitate bekommt.
Obiger (linker) Graf bestaetigt das durch die kurzen Balken bei den Werten eins, zwei und drei.
Zum Dritten sollte es etliche (aber maximal ca. 500-tausend, der Anzahl der Archipelseiten, vermutlich deutlich weniger) Werte geben, die ueber den Wert von ca. 155 Millionen (siehe der erste Punkt) hinaus gehen.
Bei kleinen Abweichungen vom Wert den die allermeisten Seiten annehmen handelt es sich um Seiten, die zusaetzlich zum groszen Linknetzwerk nur ihre eigenen Links sehen. Das sind also Seiten des „No-way-home“-Archipels die NUR ins grosze Linknetzwerk zitieren, aber NICHT auf andere Archipelseiten. Fuer Archipelseiten die auch andere Archipelseiten zitieren nimmt der Abstand vom „Hauptwert“ natuerlich entsprechend mehr zu.
Aber alles in allem sollten diese Abweichungen nicht all zu grosz sein. Deswegen sieht man die im linken Diagramm nicht, denn wegen der logarithmischen Abzsisse schmiegen die Balken sich an den Hauptwert. Wenn man aber mal beim Hauptwert rein zoomt (so wie im rechten Bild; man beachte die lineare Abzsisse!) sieht man, dass da tatsaechlich noch was hinter dem høchsten Balken kommt und das verhaelt sich qualitativ so wie erwartet.
Um zu sehen ob das auch quantitativ stimmt muss man mal die Anzahl der Seiten bestimmen, die sich in den „zusaetzlichen“ Balken befinden und mit der Anzahl der Archipelseiten vergleichen.
Ersteres ist einfach, denn da muss ich nur zaehlen und komme auf 65 + 45 + 3 Seiten bei den Werten von eins bis drei und 481,118 Seiten _hinter_ dem Hauptwert. Zusammen sind das 481,231 Seiten.
Die Anzahl der Archipelseiten hatte ich schonmal, deren Menge wurde da nur nicht erwaehnt. Diese entspricht aber dem Integral unter der roten „Kurve“ (jaja, es sind Punkte) im zweiten Diagramm dieses Beitrags. Da komme ich auf 481.522 … also ein paar mehr … mhmmm … das kønnten Seiten sein die nur von Archipelseiten zitiert werden und selber keine Links haben.
Jau! Das haut hin wenn man das mal grob ueberschlaegt. Es gibt ungefaehr zehn mal mehr Seiten im groszen Netzwerk als auf den Archipelen. Letztere unterscheiden sich aber nicht von Ersteren (auszer, dass die nicht von denen zitiert werden). Deswegen wuerde ich erwarten, dass es auch zehn Mal weniger „Nullwertseiten“ gibt, die nur von Archipelseiten zitiert werden. Das waeren dann so Pi mal Daumen 300. Die Diskrepanz liegt also im „Nullwertbalken“ versteckt und den kann ich nicht ohne weiteres auseinanderpopeln.
Festzuhalten ist das Folgende: haette ich die „neue Summe“ schon bei den totalen Links angeschaut, dann waere ich auf die Existenz der Archipele mglw. schon frueher aufmerksam geworden. Hab ich aber nicht, weil es mir nicht sinnvoll erschien.
Sososososo … der Beitrag ist schon lang genug … ach doch … zwei Sachen noch, die gehen aber schnell.
Es war auch nicht sinnvoll diese „neue Summe“ ueber die neuen Links zu bilden, denn da sieht das (fast) genauso so aus. Der grøszte Unterschied liegt darin, dass der Hauptwert nicht (ungefaehr) bei der Anzahl aller Links, sondern bei der Anzahl aller Seiten liegt … muss ja so sein. Ich habe das natuerlich kontrolliert und es ist tatsaechlich so.
Und schlussendlich war das auch nicht sinnvoll diese „neue Summe“ ueber die Selbstreferenzen zu bilden, denn da wuerde ich ja nur zaehlen wie oft eine Seite von anderen Seiten zitiert wird. Das habe ich aber vor langer Zeit schonmal anders untersucht und die Kontrolle ergibt, dass das auch mit der „neuen Summe“ genau so raus kommt.
Nun ist aber wirklich Schluss fuer heute. Die Verteilung der „neuen Summe(n)“ bzgl. der Linkfrequenzen aller Seiten verschiebe ich auf’s naechste Mal.