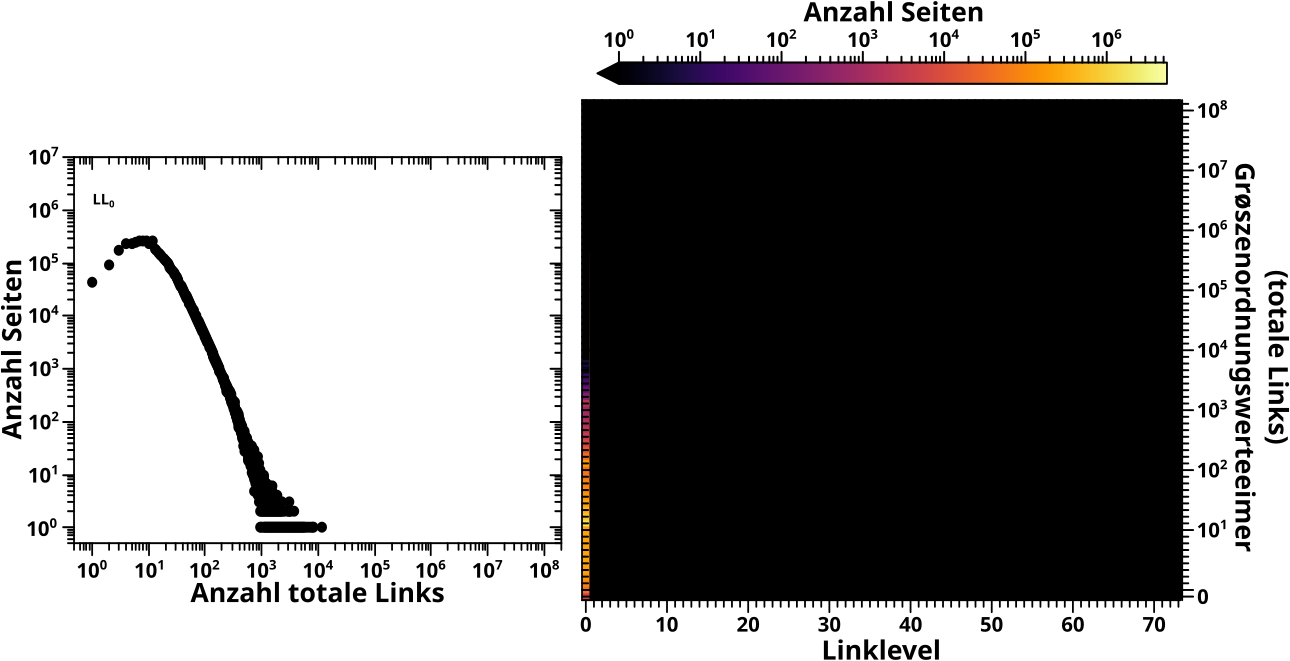
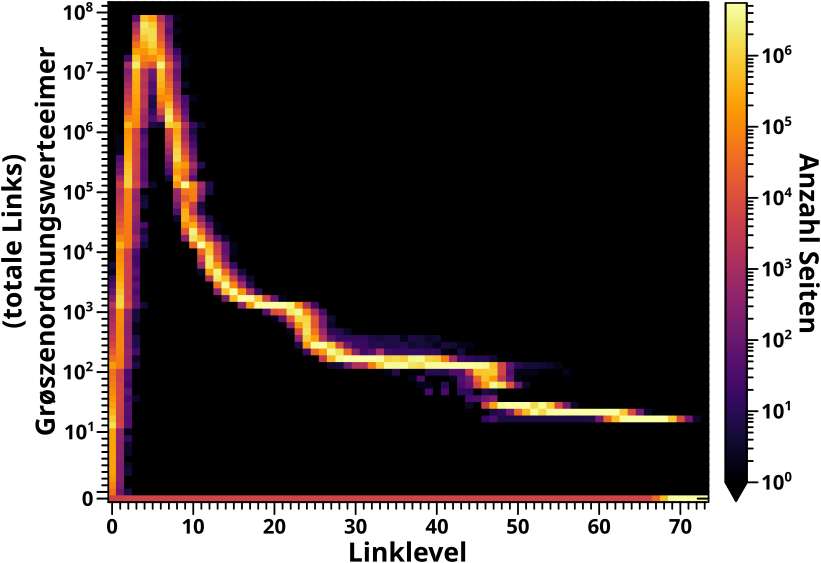
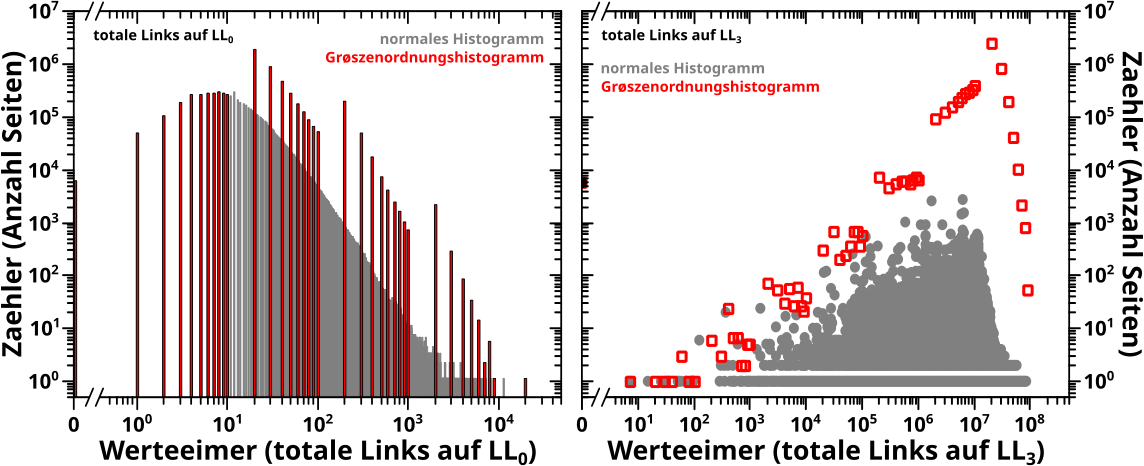
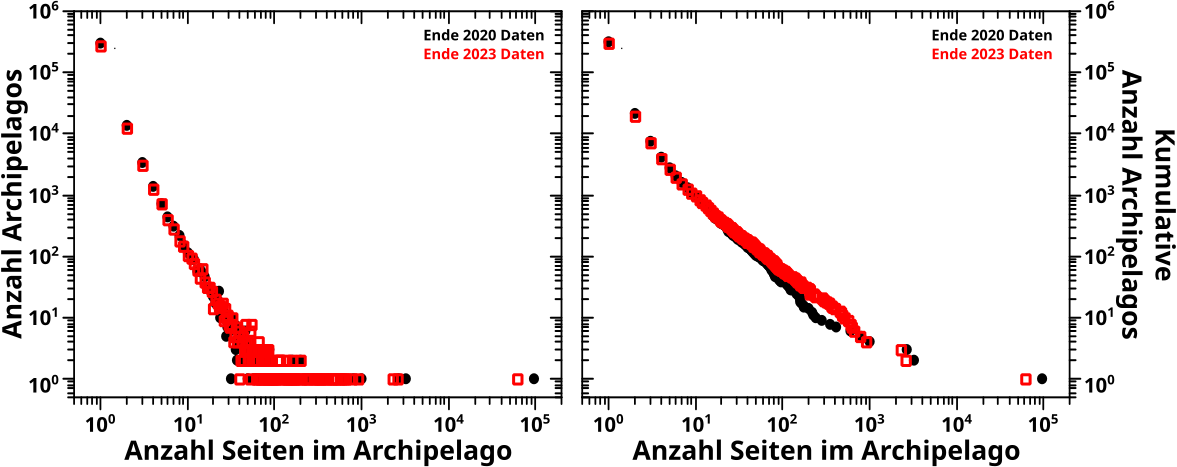
Heute wird’s etwach technisch und sehr „kleinteilig“ … das ist aber dafuer da, um die Fetzigkeit des (im uebernachsten Beitrag zu sehenden) Fetzigen zu verstehen :) .
In diesem Projekt hab ich (sehr) viele Verteilungen von (nicht nur „Mess-„) Grøszen gezeigt. Das nennt man auch Histogramm … und hier geht’s schon los mit dem Problem, denn die Konstruktion eines Histogramms beginnt eigtl. mit dem „binning“ der Daten (das ist auch der dtsch. Begriff o.O ) … und das hab ich allermeistens nicht gemacht (darauf gehe ich weiter unten ein).
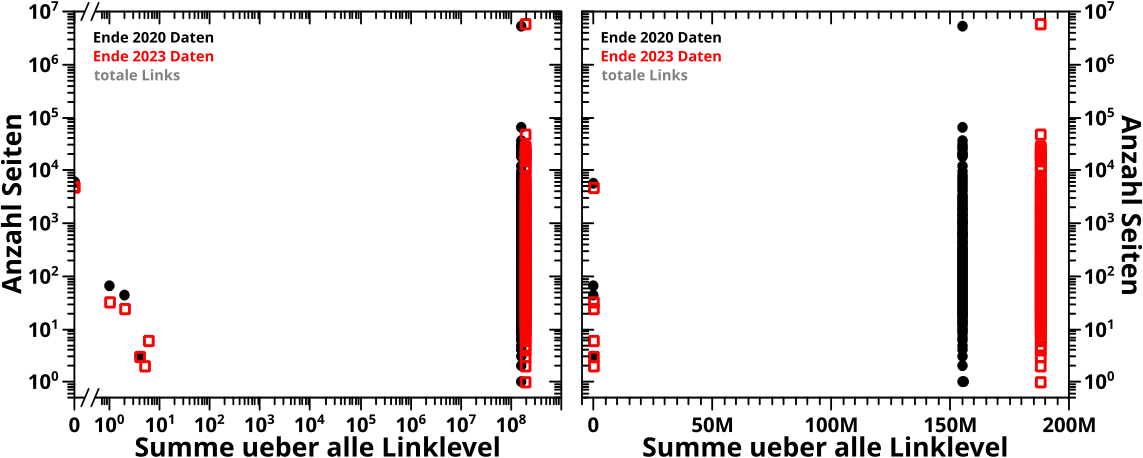
Natuerlich zeigen alle hier gemeinten Grafen Verteilungen; konkret: die Anzahl der Wikipediaseiten, die einen bestimmten Wert fuer eine grøsze von Interesse haben. Deswegen sind’s eben doch alles Histogramme.
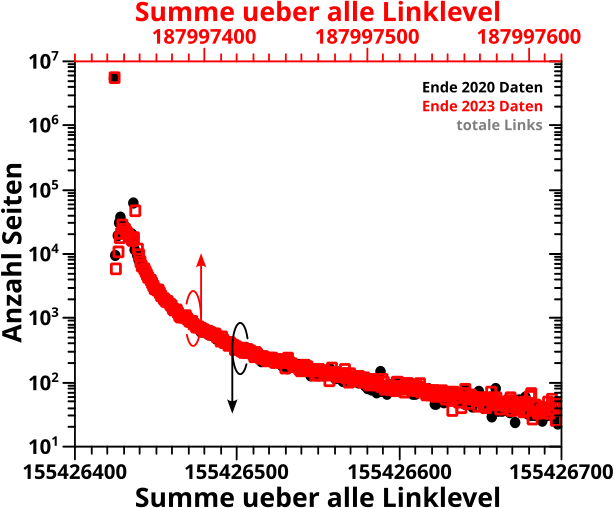
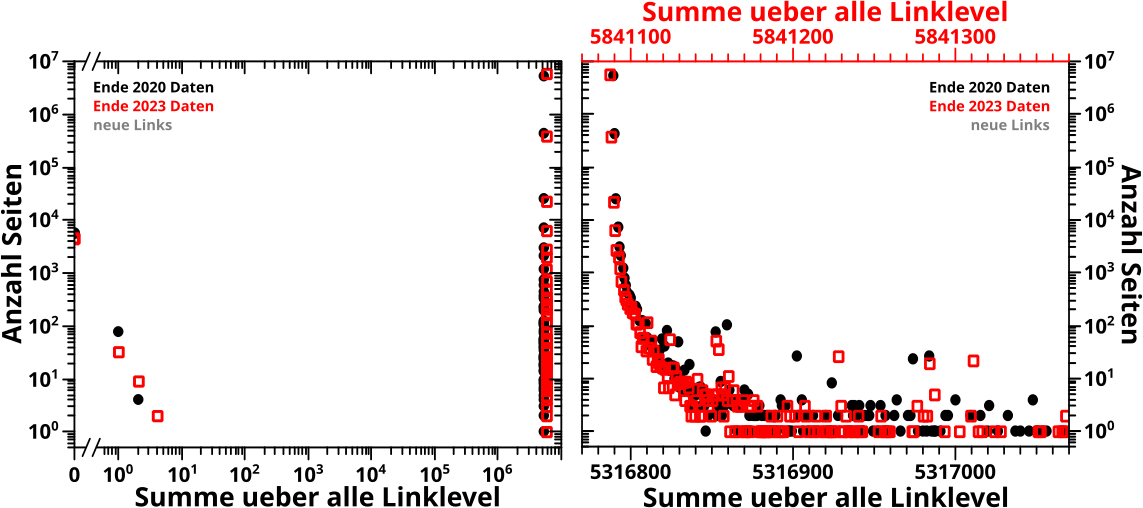
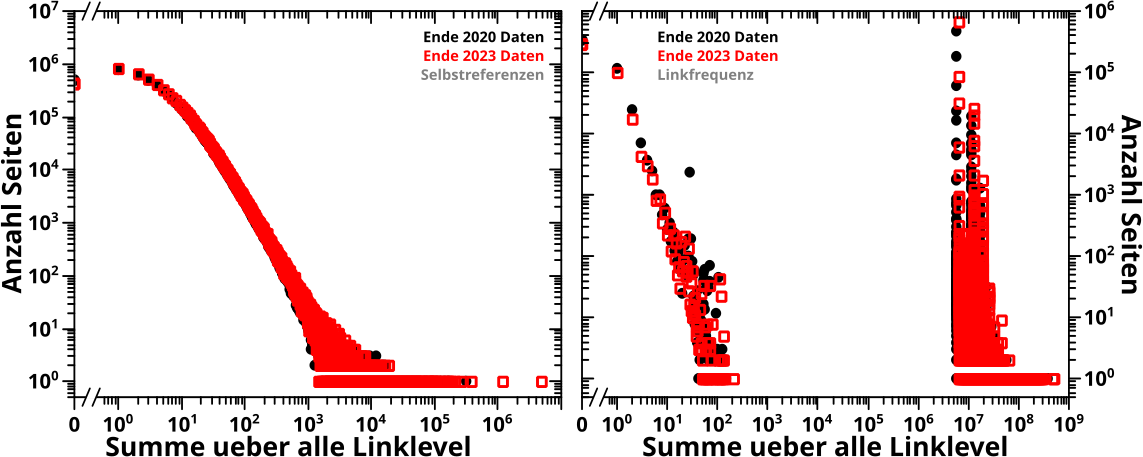
Wieauchimmer, ich erwaehnte bereits, dass ich die Daten in den meisten Faellen nicht gebinnt habe. Und der Grund ist, dass die Verteilungen sich ueber mehrere Grøszenordnungen erstrecken.
Histogramme kommen meist mit gleich groszen „Werteeimern“ … auf dtsch.: Klassen, aber das hørt sich nicht so spaszig an wie „Eimer“ und Datenanalyse ist spaszig) … in welche die entsprechenden Beobachtungen einsortiert werden. Es ist møglich unterschiedlich grosze Werteeimer zu haben, aber deren Nutzen ist eher begrenzt (weswegen die nicht sehr haeufig zu sehen sind) und wenn sich die Darten ueber mehrere Grøszenordnungen erstrecken, dann hilft auch das nicht mehr.
Wenn die Daten nicht gebinnt sind, dann kann man bei normalen Diagrammen (oft doppelt) logarithmische Skalen benutzen um das Problem der „Undarstellbarkeit“ einer Verteilung ueber mehrere Grøszenordnungen verschwinden zu lassen.
Da scheint das Problem geløst, aber an dieser Stelle tut sich innerhalb des Projekts an vielen Stellen ein damit gekoppeltes, zweites Problem auf. Nicht nur erstrecken sich viele Verteilungen ueber mehrere Grøszenordnung, sondern es gibt auch eine „zeitartige“ Entwicklung.
„Zeitartige“ Entwicklungen kann man dem Publikum im Wesentlichen in drei Formen praesentieren: als repraesentative Beispiele, als bewegtes Bild, oder als pseudo-3D Falschfarbenbild … vulgo: Heatmap (wieder: auch auf dtsch.) (Achtung: in dem verlinkten Beitrag sind KEINE „zeitartigen“ Entwicklungen zu sehen, es soll nur als Beispiel fuer Heatmaps herhalten).
Ersteres hat den Nachteil, dass man die „Dynamik“ eines Entwicklungsprozess anhand statischer Bilder nicht so richtig schøn sieht. Das ist aber eigentlich nicht so schlimm, denn es soll ja nicht unbedingt schøn aussehen, sondern stimmen. Und da liegt der schwerwiegendere Nachteil, denn man kann in den nicht gezeigten Daten die „Ungereimtheiten“ „verstecken“ und sich dann (mehr oder weniger zu Recht, oft (!) zurecht) mit dem Wort „repraesentativ“ rausreden.
Das hab ich bei allen meinen wissenschaftlichen Projekten so gemacht; natuerlich nur in (gerechtfertigten!) Ausnahmefaellen … und ja, auch bei denen, fuer die ich mit zwei Doktortiteln belohnt wurde … und auch in diesem hier. Alle anderen (mit realen Messdaten arbeitenden) Wissenschaftler machen das auch und es funktioniert. Wie gesagt: mehr oder weniger zu Recht, oft (!) zurecht. Als Beispiel fuer diese (durchaus legitime) Herangehensweise auch in der ganz groszen Wissenschaft, kann wer Interesse daran hat mal versuchen, mehr ueber die Daten in der Aequatorregion der (beruehmten) Planck Karte des kosmischen Mikrowellenhintergrunds herauszufinden. Wieauchimmer, das potentielle Problem repraesentativer Beispiele bleibt bestehen.
Zweiteres sieht imponierend aus … funktioniert aber nur digital … und seien wir ehrlich, wenn die letzten Frames des bewegten Bildes gezeigt werden, hat man (nicht nur) die Details der ersten Frames schon vergessen … *seufz* … schade um die viele Arbeit :( .
Dritteres ist am schwersten zu verstehen … aber wenn man’s verstanden hat, dann versteht man auch, warum es eine der coolsten Arten ist, dreidimensionale Information darzustellen, denn man hat alles Wesentliche sofort im Blick.
Fuer „zeitartige“ Evolutionen, bspw. solche die in den animierten PNGs im entsprechenden, oben verlinkten, Beitrag zu sehen sind, wuerde ich die Linklevel auf der Abzsisse abtragen, den Wert fuer die Grøsze von Interesse auf der Ordinate (in den bewegten Bildern ist das der Abzsisse zugeordnet), und die Anzahl der Seiten die diesen Wert haben waere dann farbcodiert (in den bewegten Bildern ist’s auf der Ordinate abgetragen).
Und hier schlaegt das erste Problem zu, denn Heatmaps wollen im Wesentlichen Pixel mit gleicher Grøsze (in eine gewaehlte Richtung).
Wenn ich die Daten einfach so in die Heatmap „reinknalle“, dann wird das zu viel. Nicht vom rechentechnischen Aufwand, aber sobald es mehr als … ich sag jetzt mal 200 Werte sind, werden die Pixel zu klein. Und hier gab es oft Verteilungen mit deutlich (!) mehr als 200 (gar bis zu ueber 5 Millionen) Werten. Und selbst wenn das fuer nur ein paar Linklevel (als „Zeitabschnitte“) der Fall ist, so sind die Millionen von Pixel bei allen anderen Linkleveln ja doch in der Heatmap vorhanden — auch wenn die „leer“ sind, so nehmen die ja doch Raum ein. Wie oben erwaenhnt, helfen einem logarithmische Achsen aus dem Dilemma, aber nur bei normalen Diagrammen.
Ich hab das mit unterschiedlich groszen Pixeln probiert (in Form einer logarithmischen Ordinate) … (keine) lange Rede, kurzer Sinn: es sieht scheisze aus, macht eine Heatmap noch schwerer zu verstehen und vermindert den groszen Vorteil einer solchen Darstellung betraechtlich — dass man auf einen Blick alles Wesentliche wahrnimmt, oder schøner ausgedrueckt mittels eines Zitats aus der Wikipedia:
[d]iese Visualisierung [Heatmaps] dient dazu, in einer großen Datenmenge intuitiv und schnell einen Überblick zu geben und besonders markante Werte leicht erkennbar zu machen.
Die letzten beiden Probleme kommen dadurch zustande, die grøszere Pixel unnatuerlich viel Raum in der Wahrnehmung einnehmen und dadurch hervorstechen … aber eigtl. sind die gar nix Besonderes … es ist aber unheimlich schwer diese (unterbewusste) Interpretation der „erhøhten Wichtigkeit“ wahrhaftig zu unterdruecken … und deswegen hab ich das hier nie gezeigt.
Das sehr spezifische Problem liegt also darin, dass ich eine „zeitartige“ Entwicklung der Verteilung einer Grøsze, deren Werte sich ueber mehrere Grøszenordnungen erstreckt, vollstaendig in nur EINEM grafischen Objekt unterbringen møchte.
Das „EINE Objekt“ in Verindung mit „vollstaendig“ laeszt nur Heatmaps zu. Die Verteilung ueber mehrere Grøszenordnungen wird mittels logarithmisch, unterschiedlich grosze Werteeimer hantiert … aber es muss eine weitere Abstraktion hinzukommen … die Details dazu beim naechsten Mal.