Die Darstellung der kumulativen Anteile der Anzahl Links pro Seite erinnerte mich, dass ich das bei den Zitierungen nur indirekt und mit Worten machte. Hier nun als Graph:
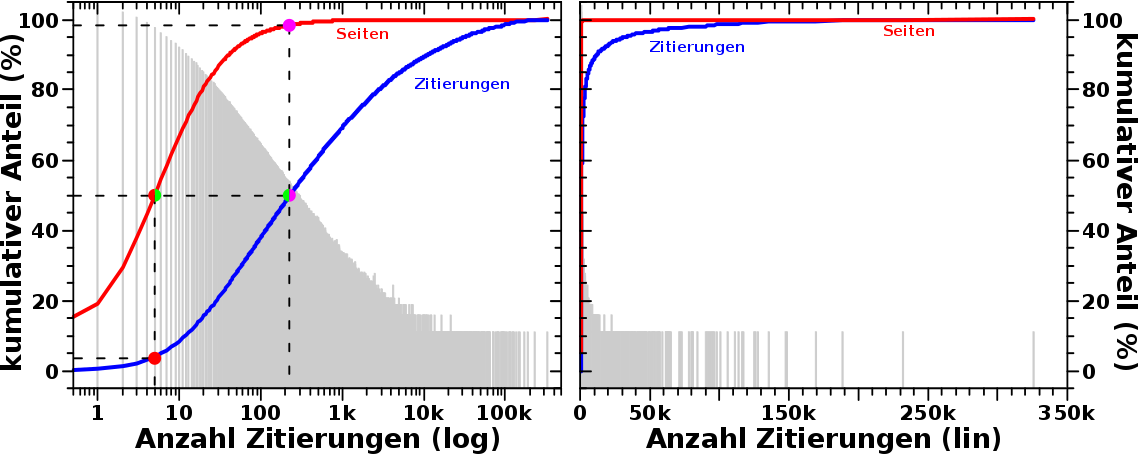
Im Hintergrund habe ich wieder die Verteilung reingelegt, wieviele Seiten wie oft zitiert wurden. Die rote Kurve stellt dann dar, wie vielen Seiten das insgesamt bis zum gegebenen Argument entspricht (in Prozent). Dito fuer die Zitierungen (blaue Kurve). Wie der Graph zu lesen ist erklaerte ich beim letzten Mal, ich markierte wieder die 50 % Werte.
Verglichen mit den Kurven beim letzten Mal ist der Unterschied zwischen den Anteilen VIEL krasser! Das sieht man noch deutlicher im Diagramm auf der rechten Seite, wo der Anteil der Seiten sich praktisch an die Ordinate anschmiegt und dann „sofort“ bei 100 % ist. Das ist eine Sache, die bei der Beschreibung mit Worten gar nicht soooo dolle rueber kam.
Kleine Abschweifung: beide Diagramme enthalten die gleiche Information (oder gar die Selbe?). Aber erst durch die verschiedenen Abszissen wird man erst auf bestimmte Dinge aufmerksam.
Warum zeige ich das hier? Nun ja, davon abgesehen, dass das ’n cooles Diagramm ist, ist es auch wichtig fuer das was ich im Folgenden besprechen werde. Denn diese Darstellung brachte mich auf die Idee, dass man die beruehmt-beruechtigte Relevanz mglw. messen kann. Nicht dass ich denke, dass das irgendwen umstimmen wuerde, aber es ist mal interessant anzuschauen.
Die Grundlage der „Messbarkeit der Relevanz“ ist ganz einfach: ein Artikel ist relevant wenn er ein wichtiger Teil der Diskussion ist. Ein wichtiger Teil der Diskussion ist ein Artikel, wenn dieser oft zitiert wird. Wie oft ist oft? Das ist dann im Allgemeinen nicht mehr so einfach zu quantifizieren.
Aber das ist auch nicht wirklich nøtig, denn im Speziellen denke ich, dass ein Konsens darin gefunden werden kann, dass die paar Seiten (lila Punkt im linken Diagramm) die 50 % der Zitierungen (gruen/lila Punkt) auf sich vereinen mit Sicherheit relevant sind. Einfach aus der (messbaren und damit objektiven (?)) Tatsache, dass die so krass viele Zitierungen auf sich vereinen, obwohl es sich dabei um nur ein bisschen mehr als 1.5 % aller Wikipediaseiten handelt. Zur Erinnerung: hier hatte ich die 50 meistzitierten Seiten aufgelistet.
Damit stellt sich dann als naechstes die Frage: wer zitiert diese Seiten eigentlich so oft? Oder anders: „wer“ sorgt eigentlich dafuer, dass diese Seiten relevant werden (sind)? Und DAS ist messbar … wird aber ein dreidimensionales Datenfeld mit 32,433,025 Millionen Werten … aber ich greife vor.
Zunaechst einmal: wie kann das gemessen werden?
Nun ja, das ist (mehr oder weniger) ganz einfach. Ich habe fuer jede Seite die Zitate (vulgo Links zu anderen Wikipediaseiten). Nun gehe ich zum ersten Mal durch die Daten, schaue fuer jede Seite wie oft die von anderen Seiten zitiert wird und merke mir das. Damit habe ich nun ein Masz fuer die „Wertigkeit“, „Wichtigkeit“ oder eben „Relevanz“ einer Seite. Je mehr Zitierungen desto „relevanter“.
Dann gehe ich ein zweites Mal durch die Daten und fuer jede zitierte Seite merke ich mir dann, von welcher Wichtigkeit die Seite war, welche diese Zitierung ausgesprochen hat. Letzteres weisz ich ja vom ersten Durchgang.
Das muss ich zwar fuer jede Seite in Erfahrung bringen, aber die Information wird zusammengefasst in Gruppen nach ihrer Relevanz. Also bspw. wann immer eine Seite die fuenf Mal zitiert wurde von einer anderen Seite die drei Mal zitiert wurde zitiert wird, dann zaehlt der Zaehler dieser 3-5-Gruppe einen hoch. Damit habe ich 3596 mal 3596 Gruppen. Wie? Nur so wenige? Mindestens eine Seite wird doch deutlich mehr als 300-tausend mal zitiert. Die Erklaerung liegt darin (wie man im Diagramm auf der rechten Seite sieht), dass da ganz schøn viel „Luft“ zwischen den Balken mit groszer Anzahl an Zitierungen ist.
Lange Rede kurzer Sinn: der Relevanzwert entspricht der Anzahl der Zitierungen ohne Luecken. Dabei muss man dann im Kopf behalten, dass die Relevanzwerte von 0 bis 2075 tatsaechlich dem entsprechen wie oft eine Seite zitiert wurde. Hingegen entspricht der Relevanzwert 5695 der einen Seite, die mehr als 325-tausend mal zitiert wurde und der Relevanzwert von 5694 eben jener Seite die „nur“ ein bisschen mehr als 231-tausend mal zitiert wurde; usw. rueckwaerts is alle Luecken geschlossen sind.
Das ist gar nicht so verwirrend, wie es sich erstmal anhøren mag. Ich bilde nur die groszen Werte auf kleineren Werten nach einer gegebenen (determinischen) Zuordnungsfunktion ab. Im Wesentlichen zaehle ich nur etwas anders.
Auch wenn das eine deutliche Reduktion des Problems ist, so sind das dennoch die weiter oben erwaehnten 5695 mal 5695 = 32,433,025 Millionen Werte.
Als ich das das Erste Mal programmierte hackte ich nur kurz zusammen, was mir gerade in den Kopf kam. Die beiden Durchlaeufe brauchten zwei Tage. Dann merkte ich, dass ich einen Fehler gemacht hatte, korrigierte den und liesz das nochmal zwei Tage laufen.
Dann hatte ich die Idee, dass ich das Ganze ja gleich in eine Matrix schreiben kønnte. Die eine Dimension der Matrix ist die „Relevanz“ einer Seite (in ganzen Zahlen mit oben erwaehnter Zaehlung). Die andere Dimension ist die Relevanz der zitierenden Seite. Und der Wert eines Felds ist dann wie oft diese bestimmte „Gruppe“ in den Daten auftauchte. Der Code wure dadurch viel einfacher und leichter zu verstehen und mit dieser (grundlegend alles veraendernde) Modifikation brauchte das dann nur noch 15 Minuten anstatt 2 Tage.
Das mit der Matrix ist ja eigentlich eine naheliegende Idee und da haette ich auch gleich drauf kommen kønnen. Aber als ich anfing hatte ich noch keine klare und eindeutige Vorstellung davon, was ich eigentlich untersuchen wollte. Also ich hatte das schon, aber „nur“ in Worten. Mein Geist brauchte ein paar Tage um das intern zu mathematisieren. Aber dann ging’s fix :) … also zumindest das Datensammeln. Zu interpretieren was ich da eigentlich sehe dauerte dann noch einige Tage mehr.
Und so sieht das aus fuer alle (!) Seiten die ein bzw. zwei Mal (schwarze und rote Punkte) zitiert wurden und fuer die zwei Seiten mit den Relevanzwerten von 5694 bzw. 5695 (lila und blaue Punkte):
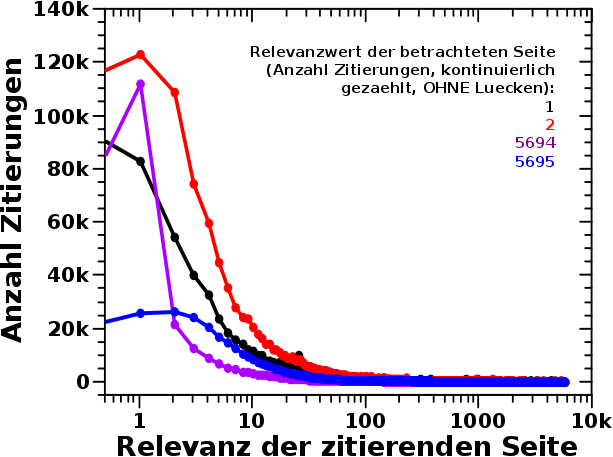
ACHTUNG: Die Linien sind nur zur Orientierung (der Richtung)! Es gibt keine Werte zwischen den ganzen Zahlen. Aber aufgrund der logarithmischen Abzsisse kann die Null nicht dargestellt werden und deswegen benøtigt es eine Orientierung der Richtung fuer den Verlauf vom Relevanzwert 1 zum Relevanzwert 0.
Fuer diese vier Beispiele sieht man, dass alle Seiten vor allem von „nicht relevanten“ Seiten zitiert werden. Fuer die selber „nicht relevanten“ Seiten bedeutet das mglw., dass die sich „im Kreis zitieren“. Sozusagen wenn Hintertupfingen Vordertupfingen zitiert, weil’s das Nachbardorf ist (und umgekehrt), aber beide von keiner anderen Seite zitiert werden.
Interssant ist, dass Seiten mit einem Relevanzwert von 1 vor allem von Seiten mit einem Relevanzwert von 0 zitiert werden, also von Seiten die ihrerseits NICHT zitiert werden.
Uebrigens tut das nix zur Sache, dass der høchste lila Punkt (von der am zweitmeisten zitierten Seite) deutlich høher ist als der høchste blaue Punkt. Das Integral unter der Kurve entspricht der Anzahl aller Zitierungen und die blauen Punkte sind zu groszen Relevanzwerten hin immer ueber den lila Punkten. Das sieht man aber in der linearen Darstellung nicht, weil die Werte unter 1000 liegen.
Die schwarzen und roten Punkte liegen da uebrigens nochmal drueber, denn alle Seiten die ein mal zitiert wurden sind ja viel mehr als die (buchstaeblich) zwei meistzitierten Seiten … oder anders: Kleinvieh macht auch Mist.
Bemerkenswert ist nun, dass auch die zwei meistzitierten (und damit die zwei relevantesten) Seiten am haeufigsten von „nicht relevanten“ Seiten zitiert werden. Wait! What? Das wuerde doch bedeuten, dass die nur deswegen relevant sind weil sie von „nicht relevanten“ Seiten zitiert werden! Was im Umkehrschluss bedeutet, dass die ganze Relevanzdiskussion fuer’n Arm ist, weil es die einen nicht ohne die anderen geben kann.
Aber das sind nur vier Beispiele. Fuer die Gueltigkeit dieser Aussage muss ich das fuer alle (oder zumindest die Mehrheit) der relevanten Seiten zeigen. Nun weisz ich aber aus Erfahrung, dass man nix mehr erkennt, wenn man fast 5700 Kurven darstellt. Ich kann das aber als Falschfarbenbild darstellen. Dazu aber mehr beim naeachsten Mal … … … Na gut … hier schon mal ein Spoiler … tihihi:
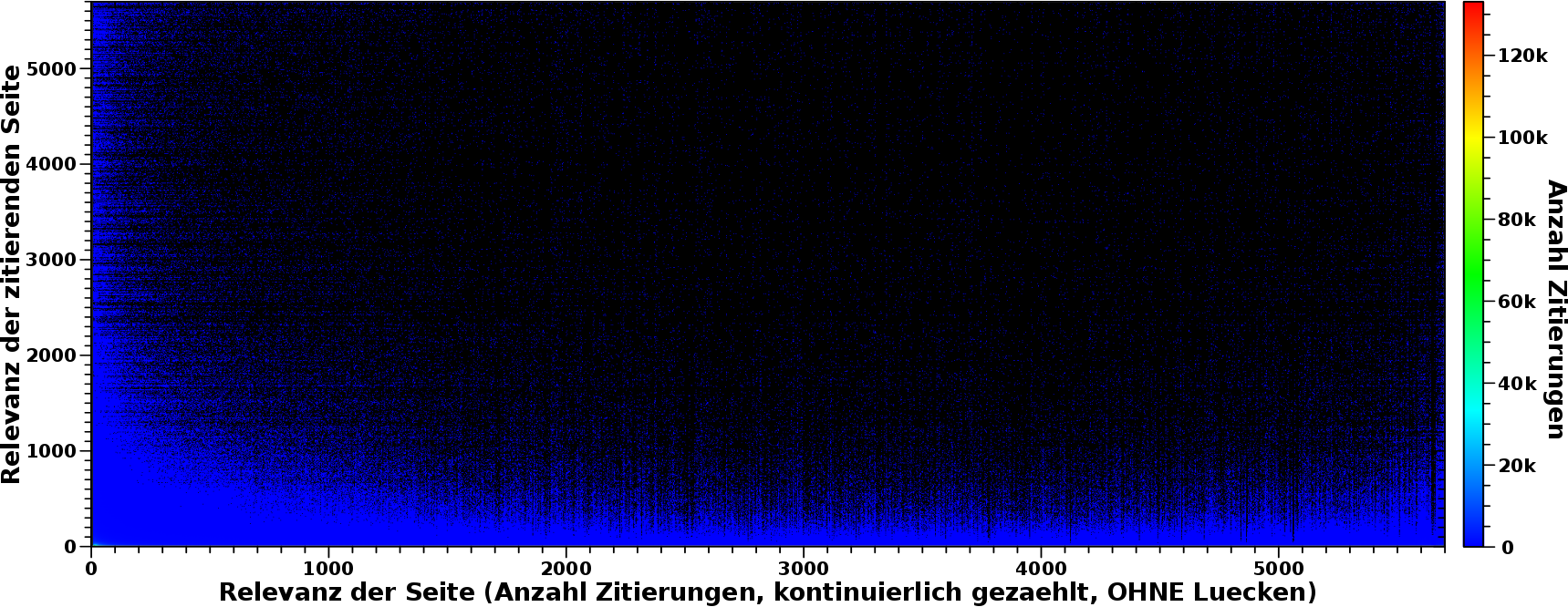
Keine Sorge, das wird noch spannend :) .
Leave a Reply