Bevor ich meinen Rechner viele Stunden rechnen lassen wollte, schaute ich mir erstmal an, wie sich die Rechenzeit in Abhaengigkeit von den Parametern verhaelt.
Wir (also ihr, meine lieben Leserinnen und Leser, zusammen mit mir) erinnern uns: die Laenge bis zu der die Fibonaccifolge ausgerechnet und untersucht werden soll ist einer der Parameter und die Laenge der Zeichenketten die untersucht werden sollen die andere.
Bei Letzterem ist zu beachten, dass ich immer alle Zeichenketten BIS zu der maximalen Laenge untersucht habe. Wenn vierstellige Zeichenketten von Interesse sind, wurden also auch alle drei-, zwei- und einstelligen Zeichenketten mit untersucht.
Warum Daten nicht benutzen, die ohnehin mit anfallen? … jajaja … Das Programm haette ich auch anders schreiben kønnen, sodass die nicht anfallen. Aber da ich zu dem Zeitpunkt noch nicht wusste, was ich an Daten brauche, habe ich alles „aufgesaugt“ was geht. Sozusagen wie google und facebook und die nsa und der sog. Verfassungs“schutz“ usw. usf. … ihr, meine lieben Leser und Leserinnen, versteht sicherlich, worauf ich hinaus will.
Aber ich schwoff ab.
Die Rechenzeit in Abhaengigkeit von der Gesamtlaenge der Folge und von der Laenge der zu untersuchenden Zeichenkette schaute ich mir in einer weniger lang dauernden Voruntersuchung an. Bei dieser Voruntersuchung rechnete der Rechner nur ca. 1 1/2 Stunden. Ich extrapolierte dann die Daten um festzulegen, bis zu welcher Zeichenkettenlaenge ich, in der laenger dauernden Untersuchung, die Fibonaccifolge analysieren møchte und wie lang diese werden soll.
Bei dieser Voruntersuchung kam es zu einigen Resultaten, mit denen ich, gelinde gesagt, nicht gerechnet hatte und die mir so einiges Kopfzerbrechen bereiteten.
Aber hier nun die schønen Grafiken. Zunaechst die Rechenzeit in Abhaengigkeit von der Laenge der Folge; die Abhaengigkeit von der Laenge der zu untersuchenden (laengsten) Zeichenkette ist durch verschiedenfarbige Datenpunkte angedeutet.
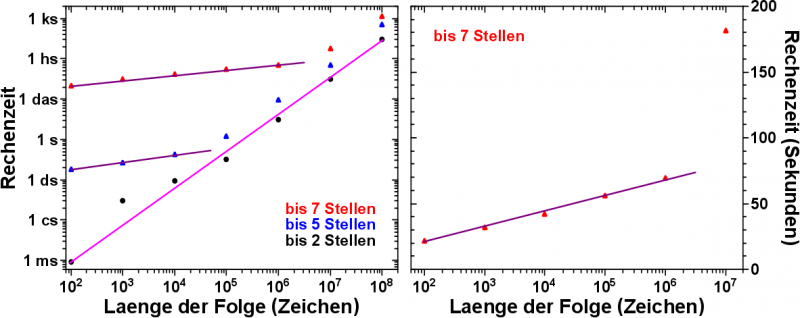
Erwartet haette ich, dass mit jeder hinzukommenden Potenz der Reihe, also mit jeder Erhøhung der Anzahl der Zeichen in der Folge um den Faktor 10, die Rechenzeit auch um den Faktor 10 zu nimmt. Wenn ich 10 Millionen Zahlen erstellen und untersuchen muss anstatt nur 1 Million, so ist diese Annahme durchaus plausibel.
Wenn ich nur Zeichenketten mit bis zwei Zeichen untersuche (schwarze Punkte), so stimmt das Ergebis gut mit dieser Annahme ueberein.
Es kommt zu Abweichungen bei kuerzeren Folgenlaengen, aber man beachte diesbezueglich die logarithmische Darstellung. Ob der Rechner drei Hundertstelsekunden rechnet, oder nur eine Hundertstelsekunde ist im Ganzen kein groszer Unterschied, macht sich aber bei dieser Darstellung ueberdeutlich bemerkbar.
Die hell-lila Gerade durch diese Datenpunkte zeigt doch eindruecklich, dass die Annahme plausibel ist.
Die erste Ueberraschung war, dass sich bei laengeren zu untersuchenden Zeichenketten (blaue und rote Vierecke), die Rechenzeit fuer kuerze Folgenlaengen zunaechst linear entwickelt (dunkel-lila Geraden), bevor sie denn in das erwartete exponentielle Verhalten uebergeht.
Nun ja, wie sagte einer meiner ehemaligen Professoren es mal so schøn: wer bei doppellogarithmischer Darstellung keine Gerade durch die Datenpunkte legen kann, muss schon ziemlich blød sein. Eine Gerade mit flacherem Anstieg muss also nicht unbedingt bedeuten, dass es sich auch im lineares Verhalten handelt.
Deswegen trug ich die Abhaengigkeit der Rechenzeit von der Laenge der Folge linear (!) auf, nur fuer den Datensatz zur Analyse von siebenstelligen (und kuerzeren) Zeichenketten (rechte Grafik). Eine Gerade in dieser Darstellung bedeutet dann natuerlich, dass sich die Rechenzeit tatsaechlich zunaechst linearar entwickelt.
Hierbei ist zu beachten, dass nicht die eigentliche Laenge der Folge von Interesse ist. Also schon, aber nur in „Schritten“ von Zehnerpotenzen. Genauer gesagt verhaelt sich also die Rechenzeit linear in Abhangigkeit von der Potenz der Laenge der Folge.
Wie ist dieses unerwartete Verhalten aber nun zu erklaeren? Ich schlage folgendes vor und hoffe, dass mich Experten, die sich besser mit Speicherzugriff usw. auskennen, berichtigen (oder bestaetigen).
Nehmen wir eine Laenge der Folge von 1 Millionen Zeichen (106) an. Dann gibt es in dieser Folge auch 1 Millionen „Zahlen“ die 7 Stellen lang sind. Es gibt aber 10 Millionen (!) unterschiedliche Zeichenketten, die 7 Stellen lang sind. Alles von „0.000.000“ bis „9.999.999“ (ohne die Punkte natuerlich). Ich sehe also nur 10% aller 7-stelligen Zeichenketten. So lange wie die Folge so kurz ist, muss ich also nur auf 10% des Speichers fuer 7-stellige Zeichenketten zugreifen. Bzw. nur 10% aller 7-stelligen Zahlen ueberhaupt analysieren (im Sinne von umwandeln eines Strings in eine Zahl und dann diese Zahl erkennen und deren Vorkommen um eins erhøhen). Erst bei der naechsten Potenz der Folge (wenn ich also 10 Millionen Zeichen untersuche) wird die Analyse- und Speicherzugriffszeit relevant. Vorher ist der Anstieg der Rechenzeit also deswegen deutlich geringer, weil auf nicht so viele Speicherzellen zugegriffen und weil nicht so viel analysiert werden muss.
Gerade beim letzten Teil der Erklaerung bin ich unsicher und hoffe wirklich, dass sich da eine Expertin oder ein Experte unter meinen Lesern befindet.
Hierbei ist das zu bedenken, was ich bereits im zweiten Artikel dieser Reihe ansprach. Die „Groesze“ der Tabelle der Haeufigkeiten der untersuchten Zeichenketten wird (fast) nur durch die Laenge der laengsten zu untersuchenden Zeichenkette bestimmt.
Nun kommt die Abhaengigkeit der Rechenzeit von der Laenge der zu untersuchenden Zeichenketten, fuer eine gegebene Laenge der Folge.
Hier ist das Resultat:
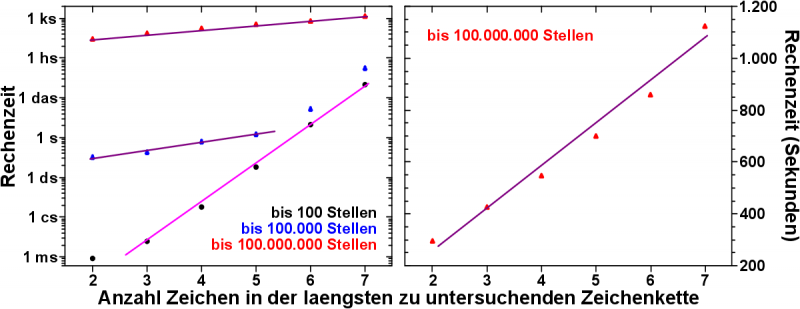
Erwartet haette ich hier, dass sich mit jeder Stelle die die zu untersuchende Zeichenkette laenger wird, die Rechenzeit linear zu nimmt.
Warum diese Annahme? Der bereits mehrfach beschriebene Analysealgorithmus – extrahiere Zeichenketten mit der maximalen Laenge, analysiere diese, schneide von dieser Zeichenkette ein Zeichen ab, analysiere diese neue, kuerze Zeichenkette usw. – ist mit einer einfachen Schleife zu realisieren.
Nehmen wir an, einstellige Zeichenketten sollen untersucht werden. Die Analyse einer einstelligen Zeichenkette dauert dann eine Zeiteinheit. Nehme ich jetzt zweistellige Zeichenketten, so dauert die Analyse zwei Zeiteinheiten. Die Zeit, die es braucht um die zweistellige Zeichenkette zu erfassen und den Zaehler um eins zu erhøhen und die bereits vorher auch benøtigte Zeit, um die einstellige Zeichenkette zu analysieren. Bei dreistelligen Zeichenketten kommt wiederum nur eine einzige Zeiteinheit hinzu.
Im rechten Bild (Achtung: lineare Skala!) sieht man diese Annahme bestaetigt. Ist die Fibonaccifolge sehr lang, nimmt die Rechenzeit linear mit der Laenge der zu untersuchenden Zeichenkette zu.
Im linken Bild (doppellogarithmische Skala!) hingegen sieht man, dass man im Wesentlichen das umgekehrte Verhalten zur vorherigen Problemstellung hatte. Kurioserweise ist das qualitative Resultat das Gleiche.
Ist die Laenge der Fibonaccifolge kurz (100 Zeichen, schwarze Punkte), so nimmt die Rechenzeit exponentiell (und nicht linear) zu mit jedem Zeichen, dass die zu untersuchende Zeichenkette laenger wird.
Wird die Folge laenger, so ist die Abhaengigkeit zunaechst linear, bis sie dann bei laengeren Zeichenketten zu exponentiellen Verhalten umschlaegt.
Darueber musste ich etwas laenger nachdenken. Hier ist eine møgliche Erklaerung.
Wenn in der zu untersuchenden Zeichenkette eine Stelle dazu kommt, dann muss 10 mal mehr Speicher “durchgerødelt” werden. Die oben erwaehnte Haeufigkeitstabelle. Auch wenn letztlich bei jedem Durchgang durch die Analyseschleife nur in eine Zeile in der Tabelle geschrieben werden muss, so muss der „Schreibstift“ (oder Schreibkopf oder Zaehler, oder vermutlich viel mehr programminterne Speicherzugriffsalgorithmen) erstmal immer bis zu dem Platz in der Tabelle „laufen“. 10 mal mehr Speicher „durchrødeln“ bedeutet exponentielles Verhalten.
Das Problem dabei ist, dass das auch bei langen Folgen der Fall waere. Ich wuerde also auch dort kein lineares Verhalten sehen, was ja aber der Fall ist.
Dies konnte ich mir nur dadurch erklaeren, dass dieser Effekt (das „Laufen“ des „Schreibstiftes“ an die Stelle zum schreiben) zwar vorhanden, aber absolut gesehen relativ klein ist. Der „Schreibstift“ ist sozusagen ein schneller „Laeufer“. An den Datenpunkten sieht man, dass dieser bspw. nur 20 Sekunden braucht, um bei einer 100-stelligen Folge, mehrfach durch die gesamte Tabelle fuer 7-stellige Zeichenketten zu gehen.
Ist die Fibonaccifolge nun kurz, so dauern die eigentlichen („Abschneide-“ und) Analyseschritte aber ebenso nicht so lange, sodass dieser Effekt signifikant wird.
Bei einer langen Folgen hingegen, dauern die eigentlichen Analyseschritte so lange (bspw. 1.000 Sekunden), sodass das „durchrødeln“ durch die Tabelle (der „Lauf zur richtigen Spalte“) NACH der eigentlichen Analyse nur noch ein paar Prozent an der der gesamten Zeit aus macht. 20 Sekunden (ja sogar 200 Sekunden) sind nicht so relevant bei 1000 Sekunden Gesamtrechenzeit.
Dummerweise habe ich das Gefuehl, dass ich hier Sachen durcheinanderwirble, die nicht zusammengehøren, aber es klingt erstmal plausibel.
Spannend, spannend all dies, nicht wahr.
Aber das hat mich alles etwas von der eigentlichen Aufgabe abgelenkt.
Ich entschied mich letztlich nur bis zu vierstellige Zeichenketten zu untersuchen, 10.000 Datenpunkte sind schon ganz gut. Dafuer aber die Statistik gut zu machen und die Folge bis zur 10-billionsten Stelle (1010) zu analysieren. Nun ja, streng genommen war es bis zur 10.000.062.095 Stelle. Aber die neu hinzuzufuegenden Elemente werden irgendwann recht lang, der „Fehler“ ist kleiner als 10-5 und ein bisschen mehr „Statistik“ schadet nicht.
Dazu dann aber mehr beim naechsten Mal.
Ach ja … die Gesamtrechenzeit bei diesen Parametern betrug ca. 15 Stunden, was gut mit den vorher ermittelten Daten uebereinstimmt.
Leave a Reply