Beim vorletzten Mal stellte ich nicht die Gruppe von Artikeln mit den wenigsten Zitierungen, weniger als zehn, vor. Das sei hiermit nachgeholt:
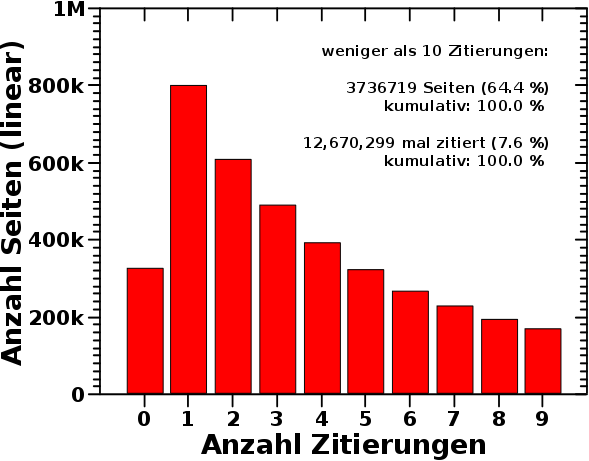
Diesmal ist die Ordinate linear, und man sieht, warum ich beim vorletzten Mal die logarithmische Darstellung waehlte. Die dort diskutierten Gruppen wuerden bei einer linearen Ordinate nur als ganz flache Balken, und damit wenig relevant erscheinen. Warum der subjektive Eindruck falsch ist, wurde beim letzten Mal ausgiebig diskutiert.
Wieauchimmer, in diesem Diagramm zeigt sich, dass die weitaus meisten Seiten entweder gar nicht, oder høchstens zwei Mal zitiert werden. Das hørt sich fuer mich sehr danach an, dass da jemand ueber „lokale Themen“ geschrieben und die untereinander zitiert hat (oder auch nicht). Das kann man aber nur bedingt oft machen. In Zahlen: 64.4 % aller Wikipediaseiten vereinen nur 7.6 % aller Zitierungen auf sich.
Die Frage ist dann, was das fuer Seiten sind. Aber dadurch, dass die nicht (oft) zitiert werden, gelangt man dort nicht durch Zufall hin. Und weil man davon keine Ahnung hat, sucht man die auch nicht direkt auf. Deswegen ein paar Beispiele.
Die 2014 Sark general election wird nur 2 mal zitiert. Aber nachdem ich das gefunden hatte, bin ich einigen der dortigen Links gefolgt und nun møchte ich die Gegend mal voll gerne besuchen. Das spricht doch total fuer die Relevanz dieser Seite, nicht wahr.
Das Dørflein Zaprężyn wird nur ein Mal zitiert … auch hier habe ich jetzt Lust da mal hinzufahren.
Ein anderes Dorf, Mirikənd wird ebenso nur ein Mal zitiert … øhm … dito … aber ich denke nicht, dass das mal was wird … auszerdem lernte ich dabei, dass Aserbaidschan eine Exklave hat.
Die Motte Eucrostis pruinosata wird ueberhaupt nicht zitiert und …
… das gleiche Schicksal ereilt Miss Lithuania 2008: Gabrielė Martirosian … die arme Dame.
Das Beispiel mit der Motte ist uebrigens eine gute Veranschaulichung eines fundamentalen Problems unserer Zeit. Die Menschheit weisz total viel, aber ein einzelner Mensch kann das gar nicht alles speichern. Es gibt so urst krass viel Wissen, welches in den Lagern (und Kellern) von Bibliotheken und Museen liegt. Deswegen gibt es auch sehr oft neue Entdeckungen aufgrund von Zeug was wir (als Menschheit) seit 100 Jahren oder laenger haben, was aber seitdem in besagten Kellern liegt. Manchmal gibt es dann eine (oft pensionierte) Person, welche die weltweite Authoritaet bzgl. bspw. einer bestimmten (praehistorischen) Spezies von Familie der Mollusken ist. Und wenn diese Person stirbt, geht all dieses Wissen verloren. Im Grunde genommen selbst dann, wenn das aufgeschrieben wurde, weil man Erfahrung (und die Zusammenhaengen zwischen verschiedenen Dingen) nicht wirklich (effektiv) kodifizeren kann.
Und das ist ueberhaupt eines der grøszten Probleme der Menschheit (und war es schon immer). Jeder Mensch muss alles selbststaendig und alleine lernen. Anders als im Film Matrix kann man Wissen leider nicht schnell in unsere Køpfe uebertragen. Was Sabine lernt kann Peter noch lange nicht.
Aber Computer kønnen das. Und wenn es mal richtige kuenstliche Intelligenzen gibt, dann kønnen die das mglw. auch. Oder anders (und viel konkreter): wenn ein selbstfahrendes Auto lernt, wie man im Berliner Stadtverkehr andere autofahrende Idioten erkennt, dann kønnen alle anderen selbstfahrenden Autos das ueber Nacht herunter laden und die wissen das dann einen Tag spaeter auch.
Andererseits bedeutet das aber auch das Folgende: sollten wir dieses Problem jemals geløst bekommen, dann wird die Post aber mal voll abgehen fuer die Menschheit! Der Fortschritt seit der Renaissance oder der industriellen Revolution wird dagegen aussehen wie’n Glass Wasser im Ozean.
Und ich halte das durchaus fuer durchfuehrbar. Denn ein anderes Menschheitsproblem ist in unserer Zeit (im Wesentlichen, wenn auch noch nicht ueberall im Praktischen) geløst worden: die Verteilung von Wissen. Wenn man was obskures wissen wollte, dann war das frueher alles ziemlich umstaendlich. Klar, gab (und gibt) es Bibliotheksverbuende, welche auch Buecher von einem Land ins andere schicken. Sicherlich kann man viel in Fachbuechern nachlesen. Aber hat man das auch gemacht? Sind diese Møglichkeiten des Informationstransfers auch massenhaft (vulgo: von der gesamten Menschheit) in Anspruch genommen worden? Oder war es doch eher so, dass nur ein paar hunderttausend (oder lass es auch ein paar Millionen sein) Menschen, welche (mehr oder weniger) zur (Wissens)Elite gehør(t)en, diesen Informationstranfermechanismen auch benutzten? Hier bestand also prinzipiell ebenso die Møglichkeit des Informationstransfers, aber praktisch war das massenhaft (sowohl von der Menge der Information, als auch von der Menge der Rezipienten) nicht zu gebrauchen.
Aber dieses Problem hat das Internet geløst. Und selbst Zensur, oder dass da laengst nicht alles obskure Zeit zu finden ist, aendert nichts an der Tatsache, dass der Informationsfluss tatsaechlich ein Fluss wurde in den letzten 20 Jahren und kein trøpfelndes Rinnsal ist wie vorher. Voll krass wa! Wir leben in ’ner voll geilen Zukunft!!!
Und da macht das dann auch nix, dass das nur einmal zitiert wird. Und es macht auch nix, wenn man die Erfahrung der oben erwaehnten Molluskexpertin nicht kodifizieren kann. Solange es auffindbar ist im Informationstransfernetzwerk, kann sich wer anders besagtes Wissen wieder relativ schnell aneignen … neue Erfahrung kann auf den Dokumenten alter Erfahrung aufbauen und dort fortsetzen (selbst wenn Letztere fuer immer verloren ist) … und das ist Fortschritt … *freu*.
Das war’s jetzt erstmal mit den Sachen, die ich aus den Titeln der Wikipediaseiten (und was damit zusammenhaengt) herausziehen kann. Beim naechsten Mal behandle ich dann noch die Anzahl der Links pro Wikipediaseite … Hurra! Noch eine neue Verteilung auf die ihr, meine lieben Leserinnen und Leser, euch bereits jetzt freuen kønnt :).