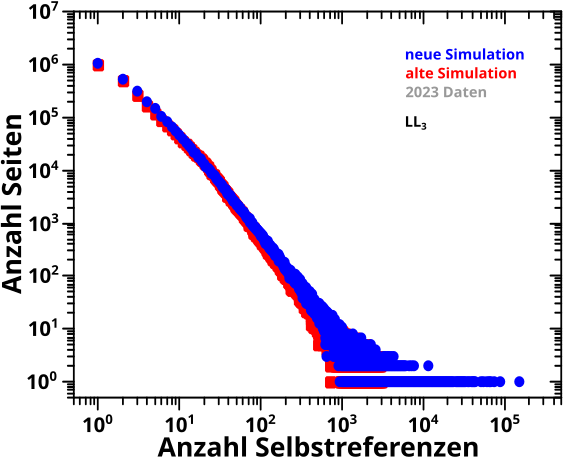
Zur Simulation der Selbstreferenzen via „atomistischer Naeherung“ (die ich an sich eigtl. nicht nochmal machen will, weil ich das Gefuehl hatte, dass das nicht viel gebracht hat) benøtigte ich auch die Abhaengigkeit der Anzahl der Selbstreferenzen die eine Seite auf einem gegebenen Linklevel hat, von der Anzahl der Selbstreferenzen dieser Seite auf dem vorherigen Linklevel. Oder anders und an einem konkreten Beispiel: hat eine Seite mit vielen Selbstreferenzen auf LL5 auch viele Selbstreferenzen auf LL6?
Nachdem ich das „Konzept“ „entwickelt“ hatte, wandte ich das dann auch auf die totalen und neuen Links und die Linkfrequenz an. Viel ist dabei nicht rumgekommen … aber ich habe den Code dafuer neu geschrieben und deshalb liegen die Ergebnisse jetzt auch fuer die 2023 Daten vor.
Hinzu kommt, dass ich fuer’s letzte und vorletzte Mal ein Werkzeug schrieb, mit welchem ich ([deutlich mehr als] halb-)automatisiert Diagramme erstellen und schøn machen kann. Anstatt also nur ein paar repraesentative Beispiele zu zeigen, kann ich nun ohne all zu viel arbeite ALLES diagrammisieren … was in diesem Falle hiesz, deutlich ueber 200 Bilder zu erstellen. Zugegeben, die meisten davon sind nur „Zwischenschritte“ im automatischen Prozess und nicht direkt im Endergebnis zu sehen … aber erstellt werden mussten die trotzdem. Das Endergebnis sind dann nur vier bewegte Bilder; eins pro Messgrøsze. Die enthalten jeweils zwei Diagramme („Rohdaten“ und Durschnittswerte … macht schonmal acht Diagramme) und laufen ueber jedes Linklevel. Bei ungefaehr 80 zu zeigenden Linkleveln macht das ueber 600 Bilder die ihr, meine lieben Leserinnen und Leser gleich sehen werdet.
Ich schreibe das hier nochmal ausfuehrlich, weil es so ein schønes Beispiel fuer einen wichtigen Teil des wissenschaftlichen Prozesses ist: hier habe ich keine „neue“ Methode entwickelt, sondern ein effektives Werkzeug geschaffen, mit dem man viel mehr abstrakte Daten (in der Form langer Zahlenreihen) in verstaendlichere Information (in Form von „bewegten“ Diagrammen) bringen kann. Das aendert nichts an den urspruenglichen Schlussfolgerungen und Ergebnissen, erøffnet aber die „Dynamik“ eines Systems im Detail zu untersuchen … was ich aber nicht mehr machen werden.
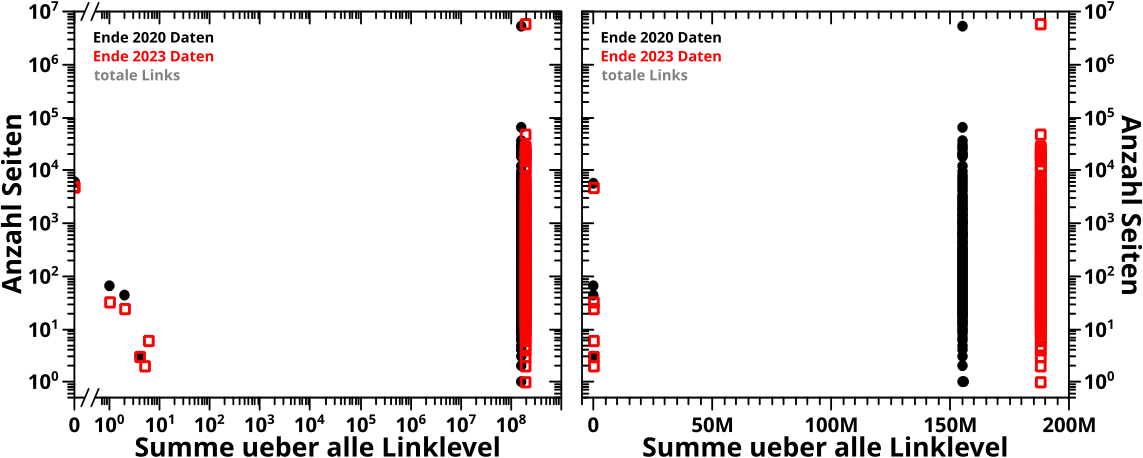
Damit genug der langen Vorrede. Hier ist die Entwicklung der totalen Links auf einem gegebenen Linklevel in Abhaengigkeit der totalen Links auf dem vorherigen Linklevel dargestellt:
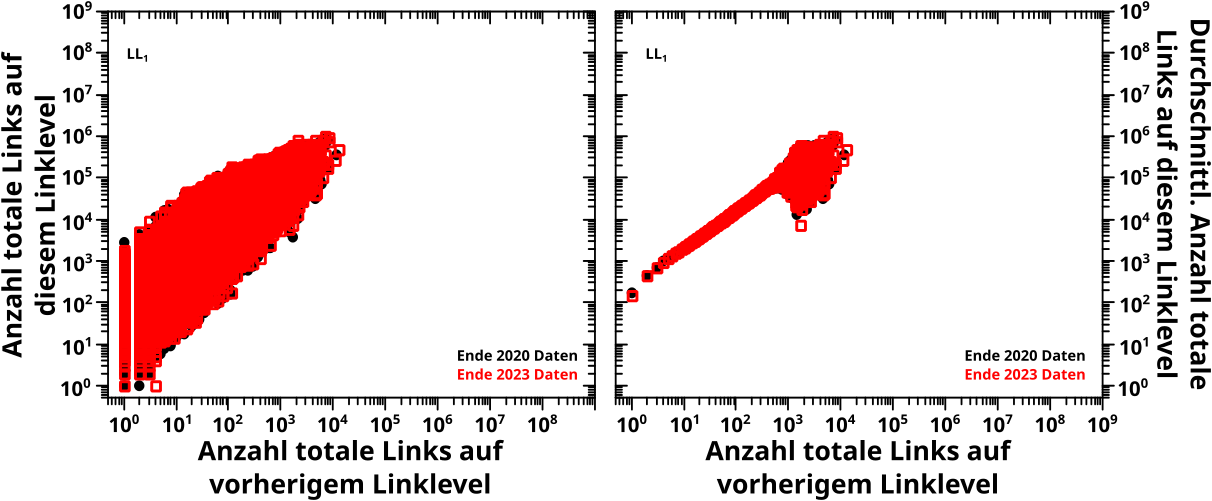
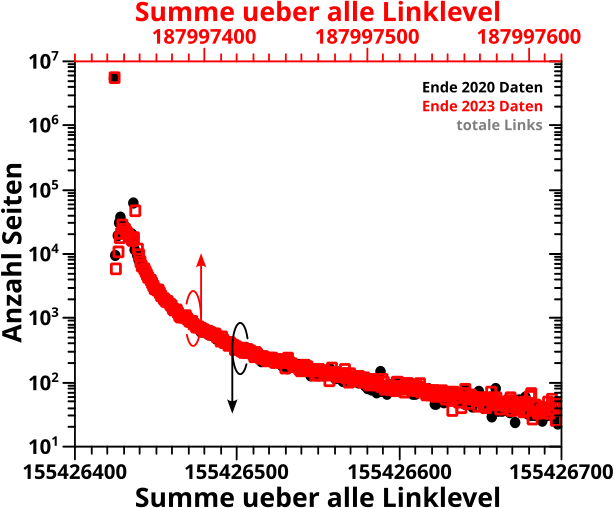
Im linken Diagramm sind die „Rohdaten“ zu sehen. Im Wesentlichen entspricht jeder Punkt einer Seite … und hier geht’s auch schon los. Nicht nur wird einem gegebenen Wert auf der Abzsisse oft mehr als einen Wert auf der Ordinate zugeordnet. Viele (in spaeteren Linkleveln alle) zu sehende Datenpunkte sind „degeneriert“. Das heiszt, dass mehrere (viele) Seiten das selbe (Anzahl-Links-auf-LLi-1, Anzahl-Links-auf-LLi)-Paar haben. Ich komme darauf gleich nochmal zurueck.
Desweiteren ist zu sagen, dass ich alle „Nullwerte“ weglasse. Also alle Daten die entweder keine (in diesem Fall) Links auf diesem oder dem vorherigen Level hatten. Ersters entspricht einem „Nullwert“ auf der Abzsisse, Letzteres einem „Nullwert“ auf der Ordinate. Bei den totalen Links kann Letzteres nur in der Form einer „Doppelnull“ auftreten (deswegen ist das allerletzte Diagramm auf LL84 leer), aber bei den Selbstreferenzen weiter unten sind beide Faelle møglich.
Ich habe mich zu diesem Schritt aus der Not heraus entschlossen, denn die Nullen bei logarithmischen Achsen mit reinzubringen ist in der Kombination meines Diagrammerstell- und Diagrammschønmachprogramms ziemlich umstaendlich. Das ist der wirkliche Grund. Ich kønnte natuerlich auch darauf zeigen, dass die Achsen bei einem Wert von jeweils 0.5 aufhøren und ein Wert von Null darunter liegt … aber das hat mich frueher ja auch nicht gestørt … als noch keine drei Grøszenordnungen weniger Diagramme zu erstellen waren.
Beim rechten Diagramm sieht man den Durchschnittswert der totalen Links zu einem gegebenen Wert auf der Abzisse. Ein Beispiel: die (totalen) Links ALLER Seiten die auf LL23 fuenf Links haben werden aufsummiert und das wird durch die Anzahl dieser Seiten dividiert. Die dabei entstehende Zahl wird im Diagramm fuer LL24 genommen und auf der Abzsisse ueber dem Wert fuenf als Punkt dargestellt. Wichtig: auch die „Nullwerte“ zaehlen dazu, zwar nicht wenn die Summe gebildet wird (plus Null macht ja nix) aber sehr wohl bei der Anzahl der Seiten durch die dividiert werden muss.
Das Feine ist nun, dass damit (zwangslaeufig) jedem Wert auf der Abzsisse nur ein Wert auf der Ordinate zugeordnet wird. Auszerdem gibt es (zwanslaeufig) auch keine „degenerierten“ Punkte mehr im Diagramm.
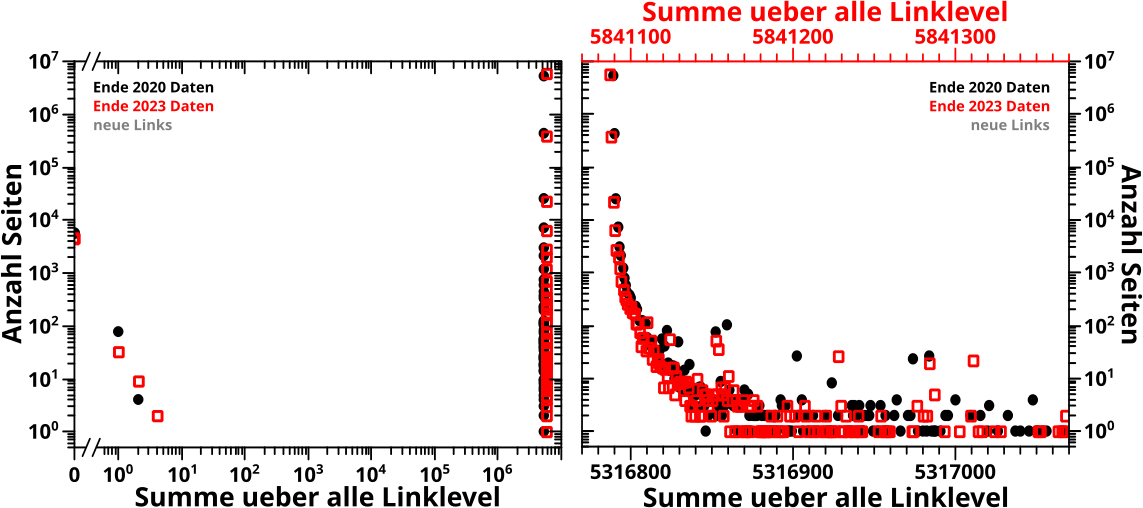
Als naechstes das gleiche fuer die Anzahl der neuen Links:
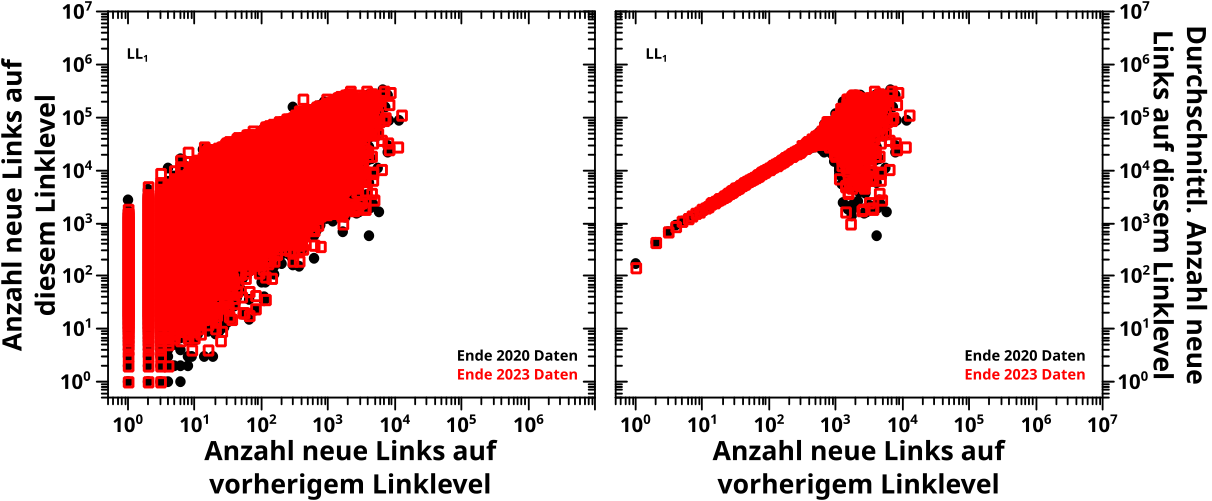
Die Achsen reichen nicht so lang (war zu erwarten) und zum Ende hin Ende zappelts nicht mehr so doll, ja steht gar still (war auch zu erwarten, wg. der „Ketten“). Kurios ist die „Verzweigung“ zwischen LL7 und LL10. Ich weise da aber nur drauf hin, ich habe das nicht weiter untersucht und werde es auch nicht tun. Das ist aber ein schønes Beispiel fuer den oben erwaehnten Prozess, dass man mittels neuer Werkzeuge (bspw.) die „Dynamik“ eines Systems besser untersuchen kann. Das ist beim Zeigen repraesentativer Datensaetze nicht aufgetaucht (denn es ist definitiv nicht repraesentativ), aber gleichzeitig aendert es auch nichts an den wesentlichen Aussagen.
Wieder gilt: die 2023-Daten reproduzieren die 2020-Daten gut.
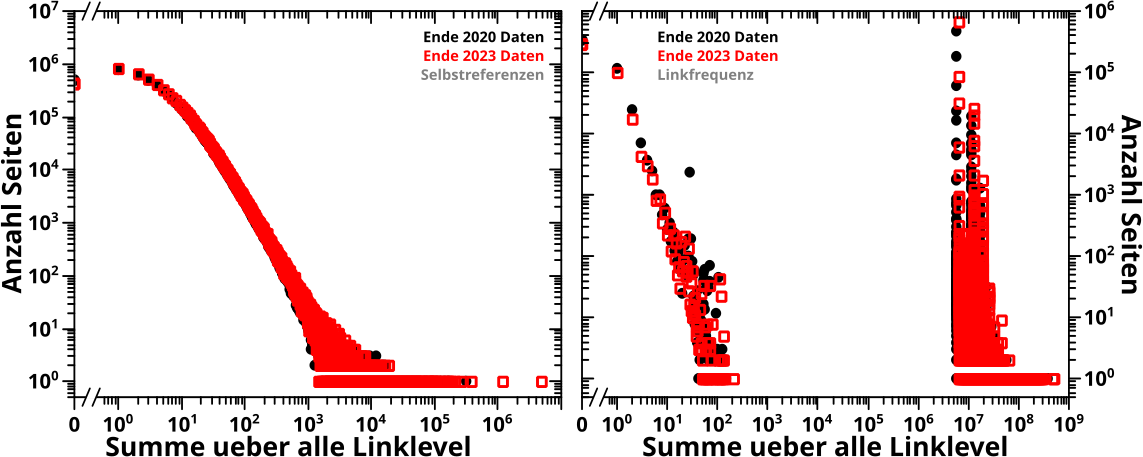
Auf zu den Selbstreferenzen:
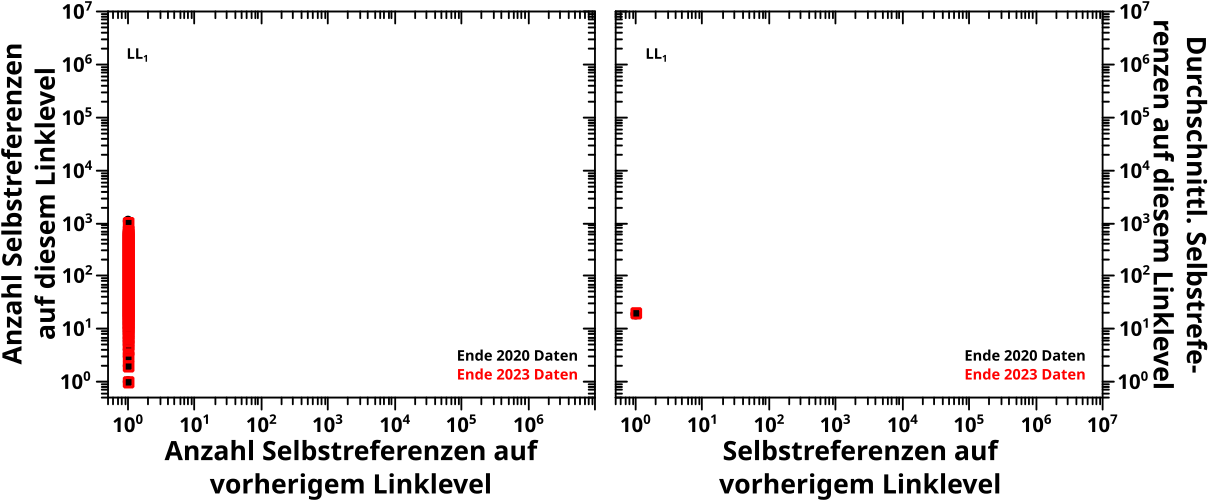
Hier wird im rechten Diagramm wichtig, was ich oben zu den „Nullwerten“ sagte … und dass die Grenze eigtl. schon bei 0.5 liegt. Denn hier sieht man øfter Punkte die gerade so ueber der Abzsisse „herumduempeln“, weil die einem Durchschnittswert von gerade mal ein kleines bisschen ueber 0.5 Selbstreferenzen entsprechen. Man sieht nicht, dass manchmal einige Punkte auch unter dem Wert von 0.5 liegen … denn die werden ja „unterdrueckt“.
Oben bei den neuen Links sieht man aber einen Hinweis auf die unterdrueckten Punkte „indirekt“, wenn man ganz schnell hinschaut. Denn das LL80 Durchschnittsdiagramm ist leer (die Rohdaten sind aber noch zu sehen); das erklaert sich natuerlich aus dem eben Gesagten.
Mehr gibt’s nicht zu sagen … ach doch: und nocheinmal reproduzieren die 2023-Daten die 2020-Daten gut.
Als Letztes dann die Linkfrequenz:
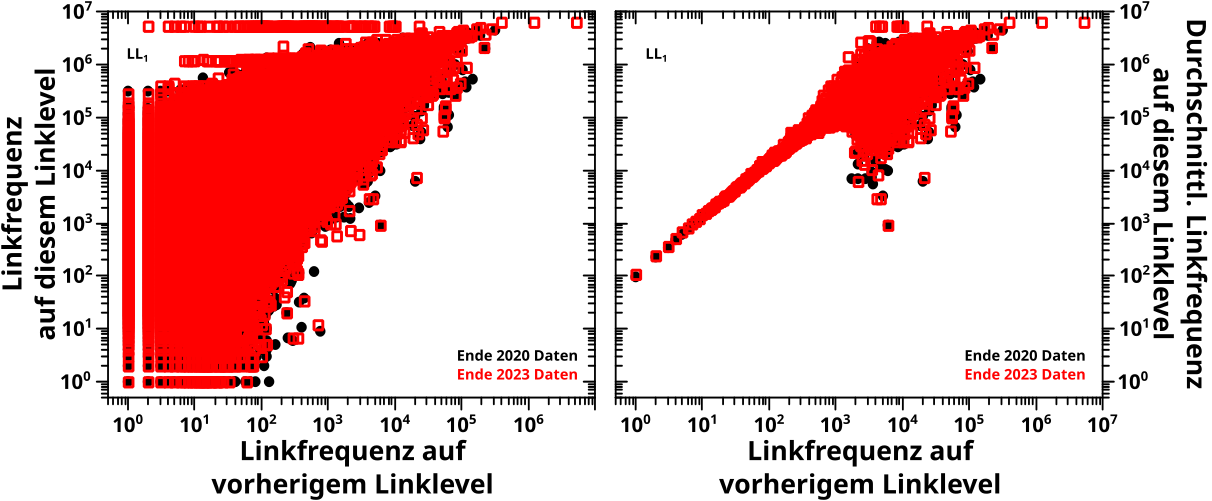
Auch wenn ab ca. LL15 deutlicher als bei den anderen Diagrammen zu sehen ist, dass die schwarzen und roten Punkte nicht mehr (beinahe) deckungsgleich sind, so bleiben alle Merkmale (Form, Verlauf und „Merkwuerdigkeiten“) erhalten. Deswegen bleibt mir nix weiter als zu sagen: auch hier ist die Reproduktion der 2020-Daten in den 2023-Daten gelungen.
Ach doch, eine Sache noch: waehrend der Durchschnittswert fuer die Links und Selbstreferenzen durchaus sinnvoll ist, gilt das fuer die Linkfrequenz mitnichten. Da kommt einfach keine (mehr oder weniger) gerade Linie bei raus, sondern die Ellipse bleibt bestehen. Man muss also immer die Sinnhaftigkeit und Interpretation der angewandten (nicht notwendigerweise nur mathematischen) „Umformungen“ der Daten gut durchdenken, damit man keinen Mist publiziert.
Und damit soll’s gut sein damit. Etwas wehmuetig habe ich das alles in nur einen Beitrag gepackt. Wehmuetig deswegen, weil trotz der (mehr oder weniger) automatisierten Bilderstellung, es noch fast ’ne Woche dauerte bis die hier zu sehenden Endresultate fertig waren … und die ganze Arbeit ist mit nur einem Beitrag „abgegessen“ … Uff! … Aber letztlich gibt’s nicht wirklich viel mehr dazu zu sagen und das ist auch gut so, denn um es muss noch mehr reproduziert werden … und ich will wirklich auch mal mit dem ganzen Projekt abschlieszen.