Dieses Weblog macht ’ne kurze Pause, denn wenn dieser Beitrag erscheint bin ich gerade in der Luft und auf dem Weg nach Helsinki um dort einen andere groszen Metallvogel zu benutzen, der mich ans andere Ende der Welt bringt.
Das letzte Mal machte dieses Weblog vor langer Zeit (und aus weit schwerwiegenderen Gruenden) eine Pause. Dieses Mal liegt’s einfach daran, weil ich trotz deutlicher reduzierter Beitragsanzahl es nur gerade so schaffe, jede Woche einen Artikel zu haben. Eine Pause von vier Wochen hilft da ungemein.
Wieauchimmer, ich møchte die Pause mit etwas Besonderem fuellen und deswegen kann es nur etwas sein, was in Verbindung mit einem der Highlights meines Lebens im letzten Jahr steht; naemlich diesem Buch:

Und wie der Titel des Beitrags bereits vermuten laeszt, geht es mir um die Periheldrehung des Merkur. … … … Das sollte ich vielleicht etwas naeher erlaeutern, deswegen der Reihe nach.
Zunaech denke man sich, dass es NUR den Merkur und die Sonne gibt. Das wohlbekannte erste Keplersche Gesetz besagt dann, dass sich der Merkur in einer perfekten Ellipse um die Sonne bewegt. Das Perihel ist dabei der Punkt an dem der Merkur den geringsten Abstand zur Sonne hat. Bei nur 2-Kørpern ist dieser Punkt IMMER an der gleichen Position. Ihr, meine lieben Leserinnen und Leser ahnt sicher, worauf wir hier zusteuern, denn …
… es ist nun so, dass es in unserem Sonnensystem noch andere Planeten gibt. Einige davon sind ganz schøn schwer und alle zusammen støren die Bahn des Merkur. Das fuehrt zu einer leichten Verschiebung der Position des Perihels des Merkurs im Laufe eines Jahres. Ich habe das Prinzip hier mal vøllig uebertrieben skizziert:
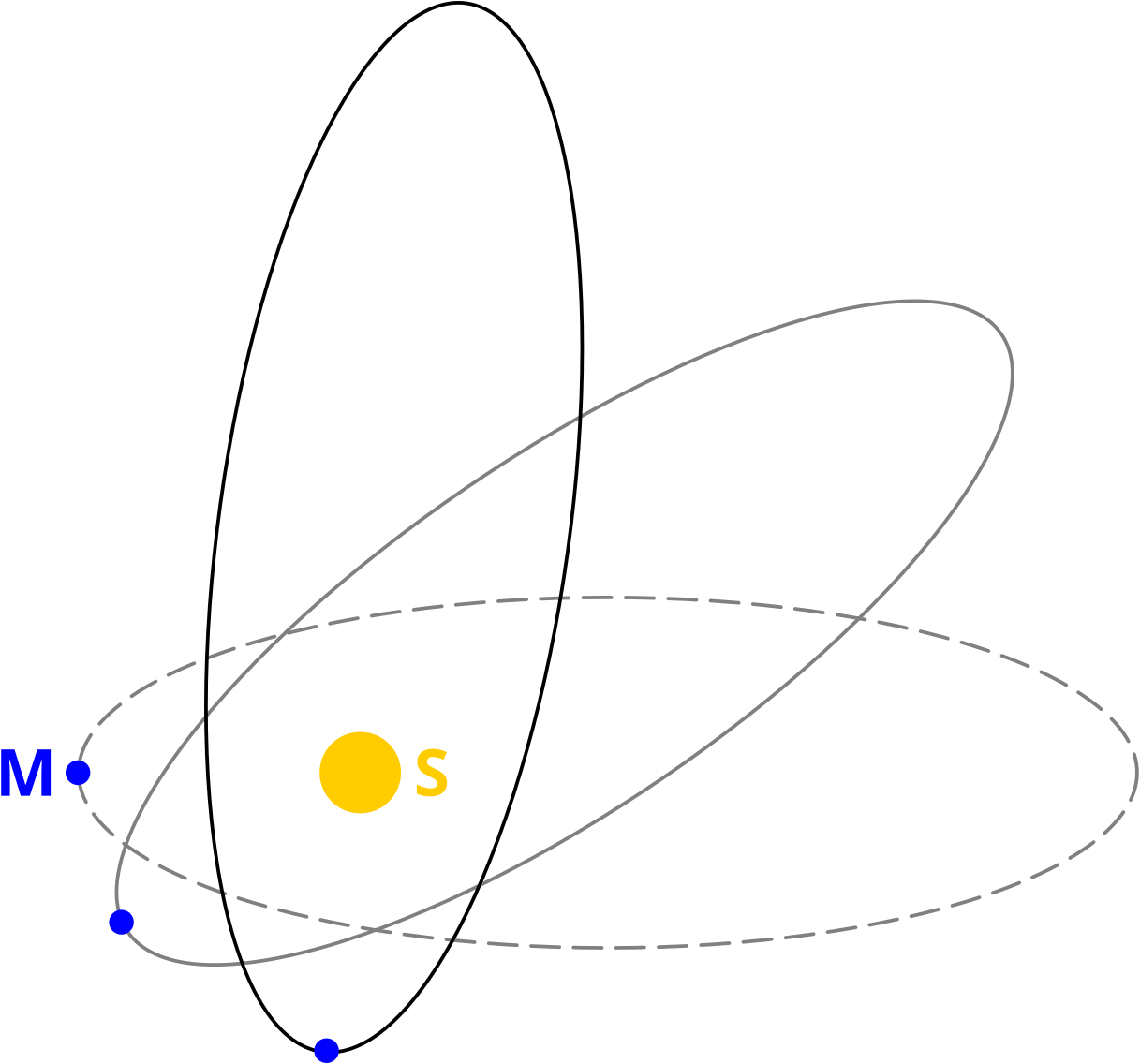
Das sind natuerlich idealisierte Momentaufnahmen und die Skizze ist auf die folgende Art und Weise zu interpretieren. Zur ersten Beobachtung schauen wir uns den Merkur an wenn er den geringsten Abstand zur Sonne hat und die graue gestrichelte Kurve beschreibt den mathematisch idealisierten Orbit des Merkur zu diesem Zeitpunkt. Im Laufe des Jahres nach der ersten Beobachtung geht die gestrichelte graue Kurve kontinuierlich in die durchgezogene graue Kurve ueber. Nach einem Jahr befindet sich der Merkur wieder in seinem Perihel und wir machen wieder eine Momentaufnahme. Die durchgezogene graue Kurve entspricht dann dem mathematisch idealisierten Orbit des Merkur zu genau diesem Zeitpunkt. Im Laufe des naechsten Jahres geht der Orbit dann in die schwarze durchgezogene Kurve ueber und den Rest schreibe ich jetzt nicht nochmal.
Der Punkt ist: aufgrund von Størungen des Orbits dreht sich die Position des Perihels um die Sonne. Im Grunde gar nicht so schwer zu verstehen.
Nun ist es so, dass ich den Eindruck habe, dass die Periheldrehung des Merkur als DER (erste!) Triumphmoment von Einsteins Gravitationstheorie ueber Newton angesehen und gelehrt wird. Und das auf eine Art und Weise, dass ich bis vor Kurzem dachte, dass Newton das ueberhaupt nicht beschreiben kann. Und das ist beinahe komplett falsch, denn ich erwaehnte ja bereits oben den Einfluss anderer Planeten und dieser Einfluss kann sehr wohl mittels Newtonscher Mechanik beschrieben werden.
Ein weiterer Størfaktor auf den Orbit des Merkur ist der Fakt, dass die Sonne keine perfekte Kugel ist. Die dreht sich naemlich um sich selber und ist deswegen abgeflacht. Das fuehrt dazu, dass das Gravitations“feld“ (genauer: das Gravitations_potential_) der Sonne (gravitative) Multipolmomente hat. In der Physik ist das was ganz normales (und es ist eigtl. immer Ausgangspunkt voll fetziger Phaenomene) und das kann auch ganz „klassisch“ mittels Newton beschrieben werden.
Ich gebe zu, da haette ich von alleine drauf kommen kønenn, aber wenn das beim „Triumph Einsteins“ ueberhaupt nie erwaehnt wird, dann sei mir hoffentlich verziehen, dass das immer an mir vorbeigegangen ist.
Denn es stimmt AUCH, dass es einen NICHT-klassischen Einfluss auf den Merkurorbit gibt, der nur durch Einstein erklaert werden kann. ABER: der ist WINZIG! Und ich dachte immer, dass der (relativ) grosz ist.
Der Einsteinsche Anteil an der Periheldrehung ist so klein, dass Newton davon ueberhaupt nix wissen konnte. Die Diskrepanz wurde gerade mal 20 Jahre vor Einsteins Geburt entdeckt, weil erst dann die Messinstrumente gut genug waren. Und das ist der erste Punkt, warum es mich ein bisschen anpiept, dass das als „Triumph“ dargestellt wird … mal davon abgesehen, dass es mich ohnehin anpiept, dass in den Medien vermittelt wird, dass Wissenschaft mittels „Triumphen“ funktioniert; dem ist mitnichten so, auch wenn es von auszen und mit (oft groszem) zeitlichen Abstand so aussieht … aber ich schwoff ab, denn eigtl. wollte ich sagen, dass es echt arschig waere, wenn ein Gewinner der Olympiade zu jemandem im Publikum geht und mit seiner Medaille angibt, obwohl Letzterer ja gar nicht am Wettkampf teilgenommen hat.
Aber so kommt mir das in diesem Fall vor. Obwohl Newton ueberhaupt nichts von der Diskrepanz wissen konnte (da die Messinstrumente zu seinen Lebzeiten noch gar nicht gut genug waren), hab ich das Gefuehl dass das in den meisten Buechern (und heutzutage auch anderen Medien) so dargestellt wird, das Einsteins Gravitationstheorie ja was Besseres ist, weil die das eben „richtig macht“.
In diese Effekthascherei verfaellt mein dickes schwarzes Buch zum Glueck nicht, denn das ist ein wissenschaftliches Buch und dort wird das von Anfang an im korrekten Zusammenhang dargestellt.
Und nun zum zweiten Punkt warum mich das „Triumphgehabe“ so anpiept. Den hatte ich schon erwaehnt, denn es geht um die Winzigkeit des Effekts. Es ist UNGLAUBLICH frech (finde ich), dass „Periheldrehung! Einstein! Hurra!“ zelebriert wird, ohne zu erwaehnen, dass es eigtl. „Periheldrehung! NEWTON! HURRA HURRA HURRA HURRA!“ heiszen muesste. Aber am besten zeige ich dazu die Tabelle in Box 40.3 „Perihelion Shifts: Experimental Results“ (S. 1112f) aus meinem dicken schwarzen Buch (von Interesse ist hier nur der „Quantity“-Teil):

Wait! What? Die Periheldrehung ist zu (fast) 90 % NUR ein Beobachtereffekt (Punkt (b), „general precession“) und ueberhaupt nicht real wenn man von weit weg auf unser Sonnensystem schaut! … AARGHGHG!!! Noch so eine eigentlich urst krass wichtige Sache (fast 90 % des gemessenen Effekts!) die KOMPLETT unerwaehnt bleibt!
Und vom Rest sind UEBER 92 % komplett mittels Newton erklaerbar! Einsteins Beitrag ist also geringer als 1 %!
Es geht mir nicht in den Kopf, dass Einsteins „Beitrag“ zur Periheldrehung so massiv „ueberhøht“ werden muss! Einsteins Gravitationstheorie ist ein Triumph (mit Absicht benutzt) der Wissenschaft an sich (so wie Newtons Mechanik oder Darwins Evolutionstheorie) und zwar einfach deswegen, weil sie das Universum noch besser erklaert ohne auf Hokuspokus zurueckgreifen zu muessen!
Ja klar! Die interessanten, von Newton abweichenden, Effekte liegen im (sehr) Kleinen … aber das macht die deswegen doch nicht weniger spannend! Und auszerdem gibt’s da noch eine Vielzahl anderer Effekte die klassisch ueberhaupt nicht auftreten kønnen … die aber nur dann zu sehen sind, wenn man EXTREM genaue Messinstrumente hat … auch dann, wenn sie am Ort der Entstehung ungeheuerlich grosz sind (bspw. Gravitationswellen).
Najut … genug aufgeregt, denn eigentlich hatte ich mich urst gefreut, als ich obige Tabelle das erste Mal las. Ich fuehlte førmlich, wie sich mein „Tellerrand“ etwas erweiterte … *freu* … was der Grund ist, warum ich da unbedingt drueber schreiben wollte.
Und damit, meine lieben Leser und Leserinnen, entlasse ich euch (und mich) in den wohlverdienten Sommer.
Ach doch, eine Sache noch: die Position des Perihels ALLER Planeten aendert sich im Laufe eines Orbits und wir kønnen das heutzutage sogar messen. Aber nur beim Merkur „lohnt“ es sich drueber zu reden.
Und dann noch eine andere Sache: die Størung des Orbits des Merkur durch das gravitative Quadrupolmoment der Sonne betraegt gerade mal 0.6 Promille (!) von dem was Einstein ausmacht … ist zwar klassisch, aber trotzdem winzig … ich find gravitative Multipolmomente nur so fetzig (denn nur die kønnen Gravitationswellen machen … wenn sie mindestens Quadrupole sind … anders als bei elektromagnetischen Wellen, kønnen Graviationswellen NICHT durch gravitative Dipole erzeugt werden), dass ich das unbedingt erwaehnen wollte.