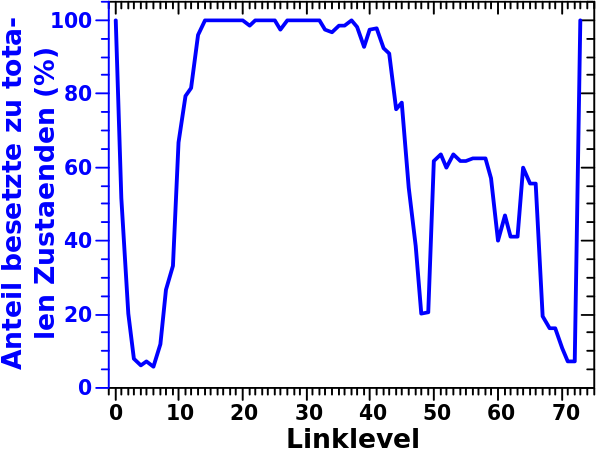
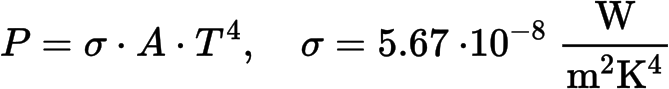Das feine Bild mit den Pfeilen vom letzten Mal ist ein Ausdruck der Hypothese, dass (fast) alle Seiten zum Ende ihres Linknetzwerkes auf den selben Seiten landen. Dort legte ich auch dar, dass die dort gezeigten Daten sehr sehr sehr stark fuer die Richtigkeit dieser Hypothese sprechen.
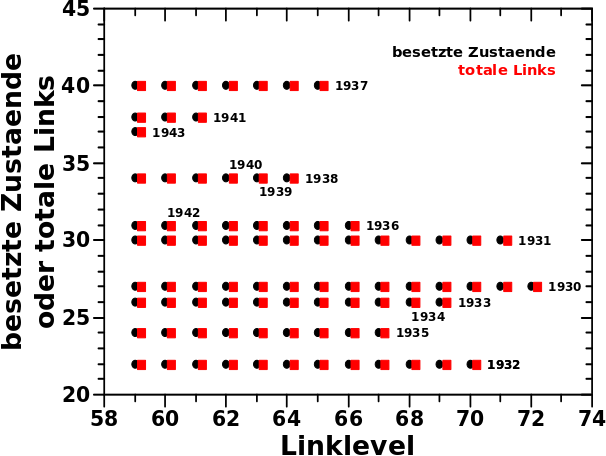
Aber man schaue sich das Bild nochmal an und nehme LL59 genauer unter die Lupe. Ich schreibe zwar, dass sich die drei „Mitglieder“ die Gruppe Alpha in der Saison des São Paulo FC von 1943 befinden, aber ich habe keine direkten Beweise dafuer. Prinzipiell kønnten naemlich auch irgendwelche anderen Seiten sich bei LL59 auf wiederum irgendwelchen anderen Seite mit 37 totalen Links befinden und diesen Zustand dadurch besetzen. Oder anders: die Gruppen (und Jahre) die ich dort angebe kønnten prinzipiell wild durcheinandergewuerfelt sein, womit die Beschriftung der Datenpunkte vøllig sinnlos waere.
Ich gebe zu, dass die Chance, dass fast 6 Millionen Seiten zum Ende hin nur diese paar Zustaende besetzen (welche auch noch mit den totalen Links der Seiten der Hypothese uebereinstimmen), unglaublich klein ist.
Dennoch wollte ich gerne noch eine weitere Sache untersuchen, welche die Richtigkeit der Hypothese kraeftigen wuerde.
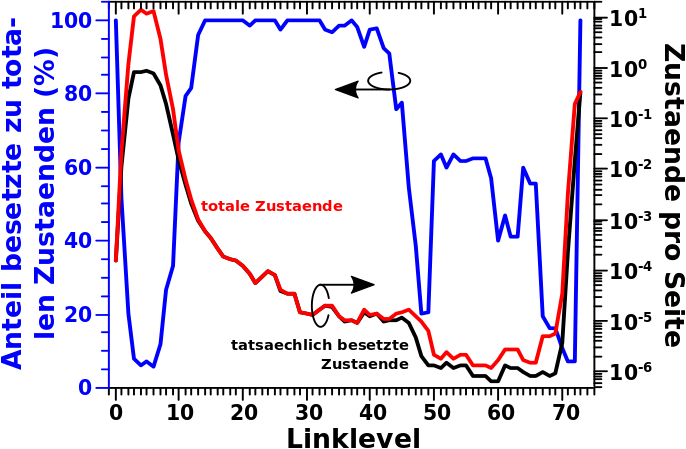
Diese weitere Sache ist die Høhe der Balken, oder besser ausgedrueckt die Amplitude des „gemessenen“ Signals.
Bisher habe ich mir nur die Position der Balken angeschaut. Im uebertragenen Sinne waere das so, wie wenn ich Nachts in den Himmel schaue, dort den Vollmond sehe und daraus schliesze, dass das wohl die Sonne sein muss. Die Sonne ist (fuer mich gesehen) naemlich eine leuchtende „Scheibe“ (Signal) mit gleicher Grøsze am Himmel (Position). Erst die Auswertung der „Leuchtkraft“ (Signalstaerke/Amplitude) erlaubt mir zwischen Sonne und Mond zu unterscheiden.
Hier wird es nun ein klein bisschen komplizierter, denn ich muss zwischen zwei verschiedenen Amplituden unterscheiden: der gemessenen Signalstaerke in jedem Zustand und der Amplitude der einzelnen Gruppen.
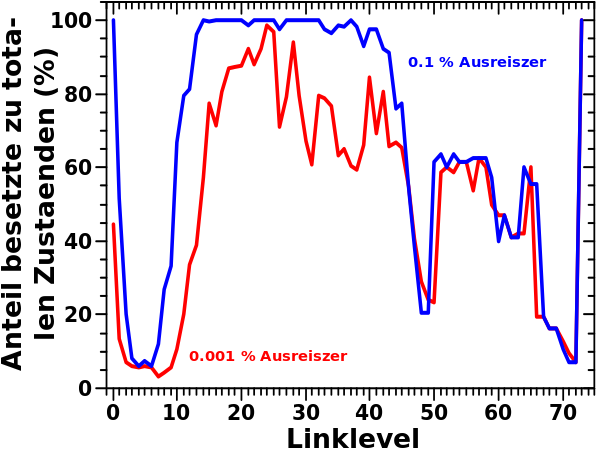
Ersteres kann ich aus den einzelnen Verteilungen einfach ablesen. Letzteres ergibt sich aus der Verteilung der „Aussteiger“ pro Linklevel, denn alle Wikipediaseiten die beim selben Linklevel aussteigen gehøren zu einer Gruppe. Hier nochmal der relevante Teil von Letzterem ein bisschen modifiziert.
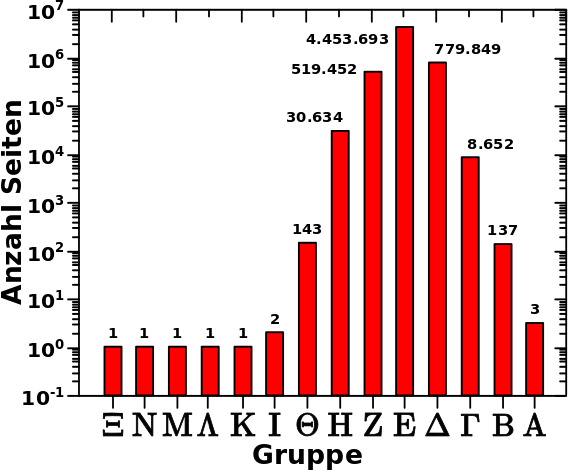
Laut der Hypothese sollte diese Verteilung sich genau so wie sie ist, d.h. OHNE Veraenderung der Amplitude der einzelnen Zustaende, durch die letzten Linklevel ziehen.
Das kønnen wir aber, in der Art und Weise wie die oben verlinkten individuellen Verteilungen bisher gezeigt wurden, nicht, bzw. nur indirekt, sehen. Das hat zwei Gruende. Der Erste ist, dass im obigen Bild die Gruppen gezeigt sind, die Abzisse der individuellen Verteilungen aber aufsteigende Zahlen die møgliche Anzahl der totalen Links (bzw. die møglichen Zustaende) wiederspiegelt. Der zweite Grund ist, dass manche Jahre/Saisons des São Paulo FC gleich viele totale Links haben und somit mehrere Gruppen in den selben (!) Zustand des gemessenen (!) Signals fallen.
Ersteres kann durch eine Achsentransformation geløst werden, Letzteres durch abzaehlen und aufpassen.
Etwas detaillierter: laut der Hypothese werden die Jahre/Saisons der Reihe nach (rueckwaerts) durchlaufen. Diesen Prozess habe ich beim letzten Mal im Detail beschrieben. Nun trage ich auf der Abzsisse nicht alle Zustaende auf, sondern _nur_ die tatsaechlich Besetzten. Auszerdem trage ich diese nicht in der Reihenfolge auf in der sie innerhalb der natuerlichen Zahlen auftauchen, sondern in der Reihenfolge, in der diese (rueckwaerts „laufend“) von Gruppe Alpha „aktiviert“, und dann der Reihe nach von den anderen Gruppen durchlaufen, werden. Mehrfach besetzte Zustaende tauchen mehrfach auf, unterschieden durch Indizes.
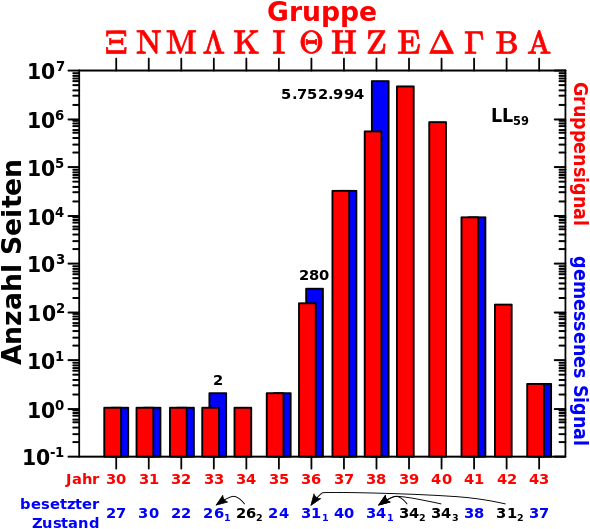
Ein Bild sagt mehr als 1000 Worte:
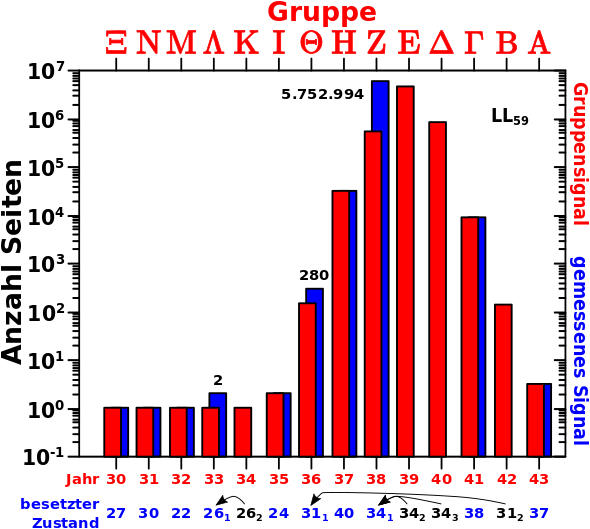
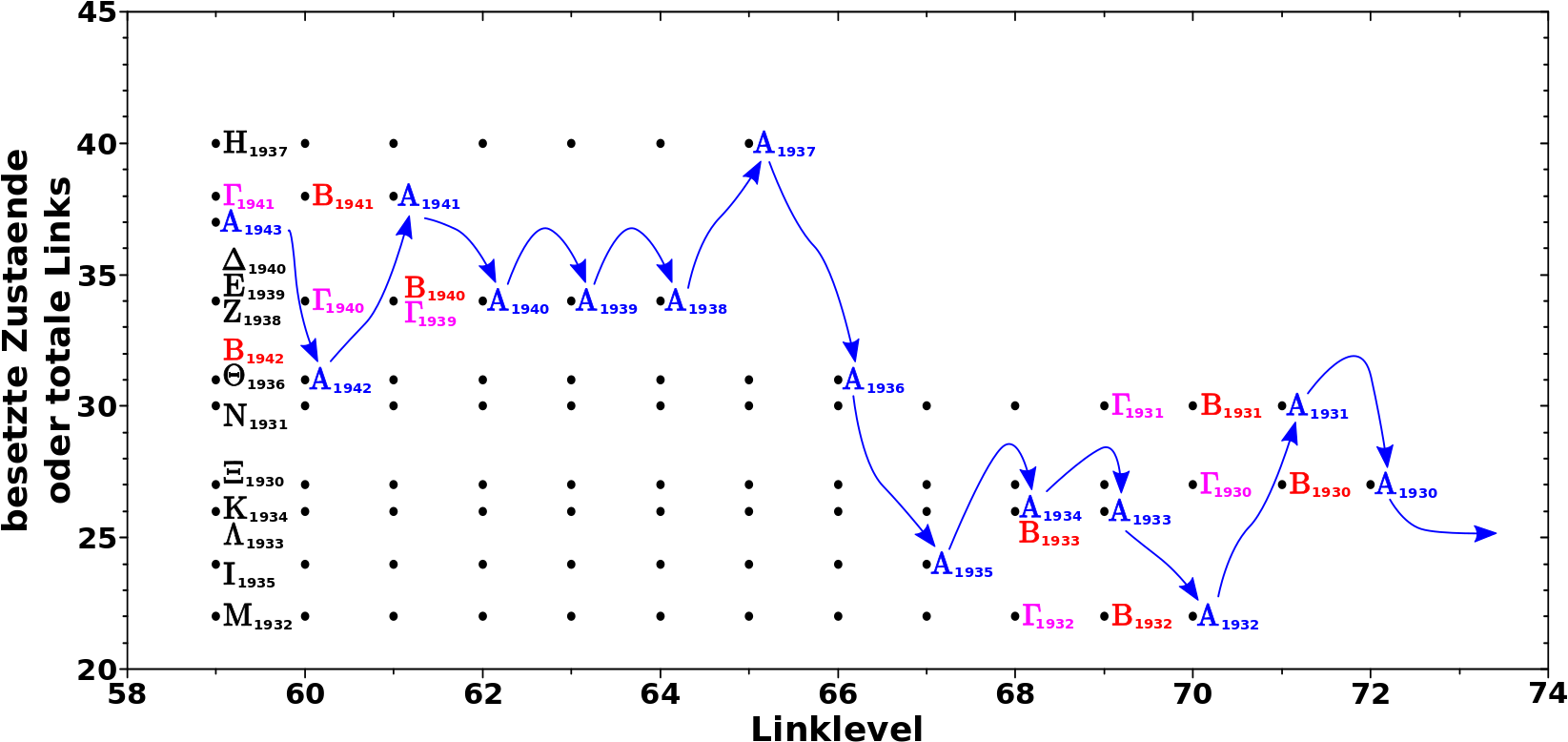
Hier sehen wir das gemessene Signal auf LL59 als blaue Balken; ich komme darauf gleich zurueck. Die roten Balken sind identisch mit denen aus dem vorigen Bild; die obere Abzsisse zeigt an welche Gruppe dem jeweiligen (roten) Balken zuzuordnen ist. Cool wa! Bisher hatte ich unterschiedliche Farben wenn dann nur an den Ordinaten … das geht natuerlich auch bei den Abzsissen … aber ich schweife ab.
Die rote Beschriftung der unteren Abzisse ist eigentlich nicht nøtig, hilft aber mglw. beim Verstaendniss und bezeichnet das Jahr in welchem sich die jeweilige Gruppe gerade befindet. Dies wird in der darunterliegenden Beschriftung in den richtigen Zustand der diesem Jahr entspricht projiziert.
Nun zu mehrfach besetzten Zustaenden. Die Seiten der Jahre 1933 und 1934 haben gleich viele Links — 26 — aber (laut Hypothese) befindet sich nur Gruppe Kappa im Jahre 1934 und nur Gruppe Lambda im Jahre 1933 (auf LL59). Das Gruppensignal aus dem Jahre 1934 — 1 — traegt dann mit dem Gruppensignal aus dem Jahre 1933 — auch 1 — zum gemessenen Signal im Zustand 26 — 1 + 1 = 2 — bei. Das sollen die Pfeile andeuten. Bei diesem Beispiel kann man das gut nachvollziehen. Aufgrund der logarithmischen Achse wird das aber schwerer (bzw. unmøglich) mit grøszeren Zahlen. Deswegen schreibe ich (hier) bei Zustand 31 und Zustand 34 ran wie viele Webseiten ich in diesen Zustaenden tatsaechlich messe. Und das stimmt ueberein mit der Summe der Signale der Gruppen die sich in diesen Zustaenden befinden.
Wie oben erwaehnt sollten sich bei voranschreitendem Linklevel die roten Balken so wie sie sind nach links schieben. Die blauen Balken sollten diese Verschiebung wiederspiegeln. Und das ist auch das was tatsaechlich passiert:
Oder vielmehr „passiert“ nur das gemessene Signal. Das schlieszt nicht aus, dass andere Seiten mit gleich vielen Links „besucht“ werden. Ich sehe die Gruppensignale nicht wirklich, ich nehme nur an, dass diese dem gemessenen Signal zu Grunde liegen. Aber, dass ueber mehrere Linklevel genau die richtigen Seiten mit der richtigen Anzahl an Links besucht werden und auch in genau der richtigen Menge sodass das gemessene Signal erhalten bleibt ist sehr unwahrscheinlich. Die einfachere und plausiblere Erklaerung ist meine Hypothese: die Gruppen besetzen tatsaechlich der Reihe nach die jeweiligen Zustaende.
Im uebrigen enthaelt das hier Gezeigte auch das was ich beim letzten Mal diskutierte. Das war aber leichter es so rum „aufzuziehen“ und so rum habe ich mich auch selber der Problemstellung genaehert.
Ich denke, dass ich nun genug gezeigt habe bzgl. des Artefakts in den Daten, welche letztlich den zweiten Phasenuebergang ausmachen. Fuer heute soll es genug sein. Beim naechsten Mal komme ich aber nochmal darauf in einem grøszeren und allgemeineren Zusammengang zurueck. Weil’s so cool ist :)
Ach doch, eine Sache noch. Auch wenn alles darauf hindeutet, so ist all dies natuerlich immer noch kein direkter Beweis, dass es sich bei den Zustaenden wirklich um die Seiten der Saisons des São Paulo FC handelt. Wenn ich es nicht vergesse, dann werde ich darauf an anderer Stelle nochmal zurueck kommen.