… in Schweden Joe Kurt kaufen:

Tihihihi. Ich fand das zu witzig um das einfach so im Kuehlregal stehen zu lassen und wollte meine Freude gerne mit euch, meine lieben Leserinnen und Leser, teilen :) .
If we have an affinely parametrised geodesic in the metric g …
… in Schweden Joe Kurt kaufen:
Tihihihi. Ich fand das zu witzig um das einfach so im Kuehlregal stehen zu lassen und wollte meine Freude gerne mit euch, meine lieben Leserinnen und Leser, teilen :) .
Uff, noch eine neue Miniserie … aber ich versuche mich an kuerzeren, leichter „verdaulichen“ Beitraegen, damit die laengeren und mglw. etwas schwerer zu „verdauenden“ Kevin Bacon Artikel ertraeglicher werden. Das bedeutet aber, dass ich Themen „zerschneiden“ muss.
Wieauchimmer, vor einigen Jahren merkte ich an, dass
[f]alls Dinosaurier intelligent waren dann wuerden wir das gar nicht mitbekommen.
Meine Argumentation lief letztlich auf die Vergaenglichkeit aller Zeugnisse einer wie auch immer gearteten Kultur hinaus.
Mir scheint, dass Schmidt, G. A. und Frank, A. diesen Beitrag gelesen haben und die Idee geklaut davon inspiriert worden sind, den Artikel „The Silurian hypothesis: would it be possible to detect an industrial civilization in the geological record?“ im International Journal of Astrobiology, 18(2), 2018, pp. 142–150 zu schreiben … … … Meine erste Reaktion war: das ist ja wohl mal urst toll wa!
Die Autoren sondieren die im Titel des Artikels gestellte Frage deutlich gruendlicher als ich und ich werde deren Ueberlegungen, Argumente und Ergebnisse im Zuge dieser Miniserie vorstellen.
Gleich vorweg kann ich sagen, dass die Autoren zum selben Ergebniss kommen wie ich. Wenn man nur ein paar wenige Millionen Jahre zurueck geht, hat man ein hinreichend groszes Signal, welches auf Wesen deuten laeszt, die dem Tierreich entstiegen sind:
[…] (the last 2.5 million years), there is widespread extant physical evidence of, for instance, climate changes, soil horizons and archaeological evidence of non-Homo Sapiens cultures […].
Darueber hinaus findet man aber eigentlich nur noch was, wenn man danach buddelt … wobei damit aber i.A. nicht die lustige archaeologische Exkursion in der Wueste Gobi gemeint ist, sondern Bergbau! Und selbst dann kommen nur ein paar wenige Millionen Jahre dazu.
Bleiben Fossilien oder (Abdruecke) von Objekten. Nur dass sich ueberhaupt Fossilien bilden ist EXTREM unwahrscheinlich (mal ganz abgesehen davon, dass man die dann auch noch finden muss):
[…] it is clear that species as short-lived as Homo sapiens (so far) might not be represented in the existing fossil record at all.
Lange Rede kurzer Sinn, die Autoren kommen (wie oben erwaehnt) zu dem Schluss, dass …
[…] for potential civilizations older than about 4 Ma, the chances of finding direct evidence of their existence […] is small.
Deswegen dreht sich der Artikel um …
[…] physicochemical tracers for previous industrial civilizations […]
… denn diese sind nicht lokalisiert (man denke hier an Treibhausgase, Uebersaeuerung der Meere oder Mikroplastik). Voll spannend, wa! Aber dazu mehr beim naechsten Mal.
Zum Abschluss sei noch gesagt, dass die Autoren auch Argumente geben, warum es wichtig ist, sich Gedanken zu machen bzgl. dieser Frage in einem professionellen Kontext … als ob es einer Begruendung braeuchte, sich ueber mglw. raumfahrende Dinosaurier Gedanken zu machen … pfffffff!
Ach ja … zur Begruendung wird (unter anderem) die Drake-Gleichung herangezogen, die in diesem Weblog ja auch bereits Thema (einer Miniserie) war.
Ich finde dies ist ein toller Jahresabschluss … ich wuensche einen guten Rutsch :)
… ist das dritte Buch welches ich von Simon Stålenhag habe. Als ich es nach dem Kauf durchblaetterte, war ich zunaechst enttaeuscht, denn es schien auf den ersten Blick eine Abkehr vom Konzept der vorangehenden zwei Buecher zu sein.

Dementsrpechend wartete ich nach dem Kauf recht lange, bevor ich es las. Zu meiner Ueberraschung stellte sich mein erster Eindruck zwar durchaus als richtig, aber meine Reaktion als unbegruendet heraus.
Das zugrundeliegende Konzept der ersten beiden Buecher — imaginierte Kindheit und Jugend in einer Gegend die voll ist mit seltsamen technischen Artefakten welche dem Ganzen eine Art Semi-Endzeitstimmung geben — gibt nunmal nur so viel her bevor es repetitiv wird. In diesem Buch schafft Stålenhag die erfolgreiche Erweiterung dieses Konzepts. Altes wird erhalten und Neues kommt dazu. Genauer ist hier ein ganzes Land (høchstwahrscheinlich der ganze Planet) und alle Bewohner „betroffen“ von den Artefakten; anstelle einer kleinen Gegend in Schweden und den wenigen Leuten die dort wohnen. Auszerdem muss es eine ganz andere Welt sein, denn die Artefakte sind zwar immer noch technisch, aber ganz anderer Natur.
Stålenhag ist sehr geschickt in der Praesentation dieser (neuen) Welt in Text und Bildern und deswegen wurde trotz meiner anfaenglichen Bedenken dieses (dritte) Buch meine Favorit :) .
Mein Weihnachtsbeitrag von mir an euch, meine lieben Leserinnen und Leser. Dieses Mal versuche ich ein bisschen zu vermitteln, warum ich mir das mit Kevin Bacon eigentlich „antue“. Warum ich nun schon seit bald 2 Jahren den kleinen Diskrepanzen so hinterherforsche (selbst wenn ich mich da auch mal verlaufe). Dies passt naemlich so schøn zusammen, worueber ich in dieser Maxiserie die letzten Wochen geschrieben habe. Aber genug der Vorrede.
In den letzten Artikeln habe ich die ganze Zeit von Archipelen oder Gruppen und Untergruppen gesprochen. Implizit meinte ich damit, dass dies unabhaengige Netzwerke sind, aber ich habe versucht letzteren spezifischen Begriff zu vermeiden.
Der Grund liegt darin, dass ich das urspruengliche Problem bereits mit diesem Begriff verbunden hatte — das Wikipedialinknetzwerk. Dieses entsteht, wenn eine Seite andere Seiten zitiert und man der Kette von Zitierungen folgt; Start zu Ende. Ich komme darauf gleich nochmal zurueck.
Was ich in den letzten Artikeln naeher betrachtete war aber eher eine Art spiegelbildliches Problem: ich schaute, welche Seiten von welchen anderen Seiten zitiert wurden. Man beachte den Unterschied in der Reihenfolge, ist das doch Ende zu Start.
Dies hat ein paar ganz erstaunliche Dinge ueber das Wikipedialinknetzwerk offenbart, die mit der urspruenglichen Herangehensweise vermutlich verborgen geblieben waeren. Aber der Reihe nach und ich muss auch etwas ausholen.
Das Linknetzwerk besteht aus den einzelnen Seiten und den Verbindungen dieser Seiten untereinander. Als (zugegeben weit hergeholtes) Analogon denke man sich, dass die materielle Welt aus Elementarteilchen besteht und wie die sich zueinander verhalten bestimmen die Naturgesetze (sozusagen als Verbindung zwischen den Elementarteilchen).
Ein Elementarteilchen hat nun gewisse Eigenschaften und eine davon ist die Ladung. Eine Eigenschaft der Seiten ist, dass diese von anderen zitiert werden, dass ist sozusagen deren (Selbst)“Zitierladung“. (In Anlehnung an die Farbladung, die ja weder eine Farbe noch eine Ladung ist.)
Anstatt dreier Ladungszustaende wie beim Elementarteilchen (positiv, negativ, neutral) gibt es bei der „Zitierladung“ nur zwei: ein binaeres ja wenn ueberhaupt zitiert wurde, egal wie oft, und nein, wenn eine Seite nicht zitiert wurde.
Die Zitierladung kann ich direkt messen und dabei sehen ich fuer jede Seite, dass die sich immer in einem der beiden Zustaende befindet. So weit ist das leicht zu verstehen.
Bei einem Elementarteilchen kann ich den Ladezustand auch indirekt ermitteln, indem ich schaue, wie dieses in einem elektrischen Feld abgelenkt wird. Die Ergebnisse folgen den Naturgesetzen.
Dass ich nach Selbstreferenzen schaute war eine solche indirekte „Messung“ der Zitierladung. Selbstreferenzen folgen direkt aus der Eigenschaft der Zitierladung der Seiten welche im Linknetzwerk miteinander „agieren“. Die Regel haette ich anfangs so formuliert: hat eine Seite eine Zitierladung, so hat diese eine Selbstreferenz. Klingt ja erstmal logisch, nicht wahr, analog zum Elektron das im elektrischen Feld abgelenkt wird bzw. dem Neutron welches nicht abgelenkt wird.
Waehrend die „direkte Messung“ eindeutige Ergebnisse erbrachte (Zitierladung ja/nein), so war das bei der indirekten Messung zu meiner Ueberraschung nicht so. Das war der erste Balken in der Verteilung der Maxima, der viel grøszer war als erwartet.
Einen groszen Teil des besagten Balkens konnte ich durch die „Ergbenisse direkter Messungen“ erklaeren — Seiten ohne Zitierladung haben natuerlicherweise keine Selbstreferenz. Einen weiteren Anteil kam durch Fehler zustande (das Artefakt der Selbstzitierungen auf Linklevel Null).
Es blieb aber eine Diskrepanz: Seiten die definitiv eine „Zitierladung“ hatten, aber die dennoch keine Selbstreferenz aufwiesen. Das ist ungefaehr so, wie wenn ein Elektron im elektrischen Feld nicht abgelenkt wird.
Der Versuch diese Diskrepanz zu erklaeren fuehrte dann dazu das gesamte Problem spiegelbildlich zu betrachten, ohne aber die urspruengliche „Richtung“ der Zitierungen zu vergessen. In den letzten Artikeln musste ich immer beides im Kopf behalten.
Aber nochmals: Vorsicht! Denn auch wenn ich sage, dass die Archipele vom Linknetzwerk unabhaengig sind, so stimmt das ja gar nicht. Selbst eine Seite des Archipels hat Zugriff auf das gesamte Wikipedialinknetzwerk; sans die Archipele selber (denn da fuehrt ja kein Link hin und natuerlich von den Seiten die keine Links haben abgesehen).
Die Seiten der Archipele scheinen somit bei normaler Betrachtungsweise (beinahe) ununterscheidbar in das Wikipedialinknetzwerk integriert. Erst die Diskrepanz bei der „indirekten Messung“ der Selbstreferenzen machte mich ueberhaupt auf die Archipele aufmerksam. Die „Unabhaengigkeit“ derselben folgt also nur, wenn man sich das Problem anders anschaut.
Und auf diese Integration wollte ich nochmal direkt hinweisen, denn weil die Unabhaengigkeit der Archipele mein Untersuchungsschwerpunkt in den letzten Artikeln war, befuerchte ich, dass Ersteres vielleicht nicht richtig rueber gekommen ist.
ich schreibe dies alles nochmal, weil der Metaaspekt des Ganzen so urst cool ist.
Wenn eine Seite eine Zitierladung, aber keine Selbstreferenz hat, so kommt Letzteres nicht durch eine Eigenschaft des Teilchen zustande, sondern ist eine Art „Wechselwirkung“ des Wikipedialinknetzwerkes auf das Teilchen. Was ich da also entdeckt habe ist eine Eigenschaft des Netzwerkes an sich. Im Gegensatz zu den totalen oder neuen Links pro Linklevel laeszt sich diese Eigenschaft nicht direkt aus den Teilchen(eigenschaften) ableiten, sondern nur aus deren „Interaktion“ miteinander im Netzwerk.
Das ist nicht ganz unaehnlich dem Baendermodell in der Festkørperphysik welches erklaert ob ein Material ein Metall, Halbleiter oder Isolator ist. Das folgt naemlich auch nicht aus den Elektronen und Atomruempfen an sich, sondern nur wenn ein freies Elektron sich in einem periodischen Potential (dem der Atomruempfe) bewegt.
Bevor es das Baendermodell gab, wusste man auch schon, dass Materie aus Atomen besteht, dass diese sich aus Atomkernen und Elektronen zusammensetzen und das Letztere den elektrischen Strom leiten. Dennoch war das Zustandekommen der unterschiedlichen Leitfaehigkeiten von Metallen und Isolatoren nicht aufgeklaert, bevor Bloch und Bethe sich dem Problem mit einer anderen, zugegebenermaszen komplizierteren, Betrachtungsweise naeherten.
Was ich sagen will: zunaechst nicht zu erklaerende „Messwerte“ bei den Selbstreferenzen erforderte die Entwicklung der Theorie der Archipele. Diese sind nicht direkt erkennbar (weil ja die Seiten der Archipele immer noch ins Netzwerk integriert sind) und eine Eigenschaft des Wikipedialinknetzwerks an sich (also nicht der einzelnen Seiten). Dadurch konnte ich recht viel Neues (und durchaus Spannendes) ueber das Netzwerk selbst heraus bekommen (besagte unabhaengigen Archipele) was ich nicht erwartet habe … und neue Erkenntnisse sind immer cool.
Eine kleine Diskrepanz førderte groszes Verstehen zutage … DAS ist Wissenschaft … … … Deswegen noch einmal: cool wa! … und dieser Metaaspekte passen so schøn in diese Zeit.
Damit schliesze ich und wuensche erholsame Tage.
Als ich das No-way-home-Archipel (nwhA) erdachte, erwaehnte ich dass es aus 39 Inseln besteht. Beim letzten Mal bemerkte ich, dass das falsch ist und es vielmehr 39 Stufen haette heiszen muessen und dass eine Stufe aus mehreren (unabhaengigen) Inseln bestehen kann.
Schnell fand ich heraus, dass ab Stufe #23 jede Stufe aus nur einer Seite besteht und die Stufen schon lange davor nur sehr wenige Seiten (meist zwei, manchmal drei) haben. Nach meiner Erfahrung mit dem São Paulo FC kam mir das sehr verdaechtig vor und ich vermutete hier im wesentlichen ein aehnliches Artefakt. Nur dass dieses nicht bei den totalen (oder neuen) Links zu sehen war, denn die Seiten gehøren zum nwhA und auf das wird ja nicht von Auszen zitiert.
Dennoch dachte ich mir, dass es ja mal ganz interessant sein kønnte nachzuschauen. Diesmal gehe ich rueckwaerts vor und schaue mir nicht an wer wen zitiert, sondern wer von wem zitiert wurde.
Auf Stufe #39 finde ich 1949 Waterford Senior Hurling Championship … the what? … wie so oft waehrend dieses Projekts habe ich mal wieder etwas gelernt. Ich war vøllig ignorant dem gegenueber, dass Hurling in Irland eine richtig wichtige Sache ist; man schaue sich nur mal das proppenvolle Stadion hier an.
Wieauchimmer, zurueck zur Sache und das sieht auf den ersten, zweiten und dritten Blick (und allen Blicken danach) tatsaechlich genau so aus wie das São Paulo FC Artefakt. Beim genauen Hinschauen komme ich zu dem Schluss, dass das Hurling Artefakt auch durch den gleichen Mechanismus entsteht, dass also NICHT Links aus dem Text ausgewertet wurden, sondern aus Infoboxen.
Wenn ich dann einen „Schritt“ hinunter gehe und schaue wer die 1949 Waterford Senior Hurling Championship zitiert, so finde ich auf Stufe #38 die 1951 Waterford Senior Hurling Championship. Und dann auf Stufe #37 die 1953 Waterford Senior Hurling Championship.
Das ist definitiv ein Artefakt … … …na dann kann ich das auch schnell abhandeln (dabei lasse ich „Waterford Senior Hurling Championship“ weg und schreibe nur noch das Jahr): Stufe #36: 1954, Stufe #35: 1955, Stufe #34: 1956, Stufe #33: 1957, Stufe #32: 1958, Stufe #31: 1959, Stufe #30: 1960, Stufe #29: 1961, Stufe #28: 1962, Stufe #27: 1963, Stufe #26: 1964, Stufe #25: 1965, Stufe #24: 1966, Stufe #23: 1967, Stufe #22: … hier geschieht was Spannendes. Zunaechst habe ich hier das Jahr 1968 der Waterford Senior Hurling Championship; aber dann habe ich hier auch die Vehicle registration plates of the Dominican Republic.
Diese beiden Seiten wurden von Stufe #21 aus zitiert. Ersteres vom Jahr 1969 und Zweiteres von der Seite zu den Vehicle registration plates of the Canal Zone. Letzteres wurde von sehr vielen Seiten auf unterschiedlichsten Stufen zitiert.
Auf Stufe #20 mache ich bei der Waterford Senior Hurling Championship einen Sprung in das Jahr 1972 und auszerdem befinden sich hier die Vehicle registration plates of the United States for 1924 und die Vehicle registration plates of the United States for 1959. Aha! Also noch ein Artefakt. Damit ich das nicht immer ausschrieben muss, behalte ich fuer die Waterford Senior Hurling Championship nur die Jahreszahlen bei und fuer die Kennzeichen der Vereinigten Staaten benutze ich die Jahreszaehlen und schreibe ein „VP“ davor. Bei Letzteren sieht man, dass das Artefakt verzweigt ist. Aber nun mal weiter die Stufen hinunter.
– Stufe #19: 1974 und VP1922 / VP1944
– Stufe #18: 1975 und die Zweige der Vehicle registration plates of the United States verschmelzen zu einem mit VP1921
– Stufe #17: 1981 und VP1918
– Stufe #16: 1983 und VP1917
– Stufe #15: sieht die Verzweigung der Waterford Senior Hurling Championship mit 1986 und 1992 und natuerlich ist da VP1916
– Stufe #14: 1988 / 1993 und VP1915
– Stufe #13: sieht die Wiedervereinigung der Waterford Senior Hurling Championship mit 1994 und weiterhin ist da noch VP1914
– Stufe #12: 1995 und VP1913
– Stufe #11: 1996 und VP1912
– Stufe #10: 1997 und VP1911
– Stufe #9: 1998 und VP1910
– Stufe #8: 1999 und VP1909
– Stufe #7: 2000 und VP1908
Auf Stufe #6 wird es dann wieder spannend. Zu den 2001 Waterford Senior Hurling Championship und den Vehicle registration plates of the United States for 1907 gesellen sich die Monate February 1927 und April 1946, die Gleiter DTGL Sant‘ Ambrogio (einsitzig) und Horikawa H-22 (zweisitzig), der franzøsische Jihadist Gilles Le Guen, die United Nations Security Council Resolution 903 und zu meiner Freude auch ein Dinosaurier: Tarsodactylus.
Offensichtlich hørt hier das Artefakt auf und das richtige No-way-home-Archipel beginnt. Alle Stufen darunter haben deutlich mehr (mindestens hunderte) und irgendwann unhandhabbar gewaltig mehr (hunderttausende) zitierende Seiten, sodass ich dem nicht weiter folgte.
Auch wenn diese Uebung in groszen Teilen eher weniger spannend war, so war es mir wichtig herauzufinden, ob mein Bauchgefuehl, dass es sich bei der langen Kette um ein Artefakt handelt, richtig war. Zu meiner Ueberraschung stiesz ich dann sogar auf zwei Artefakte. Cool war auszerdem, dass ich wieder was Interessantes in Erfahrung gebracht (Hurling) und Seiten gesehen habe, die ich sonst niemals aufgesucht haette. Weswegen sollte ich mir auch die Kennzeichen der Vereinigten Staaten von 1913 anschauen? Ich wusste ja nicht mal, dass es so eine Wikipediaseite gibt.
Es sei noch das Folgende gesagt. Auch wenn das hier grøsztenteils wieder nur ein Artefakt war, so tut dies bzgl. des allgemeinen Konzepts der Archipele nix zur Sache. Ja, das ist ein langer Schwanz, aber der besteht aus nur wenigen Seiten und geht unter in der Menge aller anderen Seiten welche die vielen hunderttausend echten Archipele konstituieren.
Das soll genug sein fuer heute. Der naechste Beitrag wird dann nochmal ein wichtiges Kommentar bzgl. des Archipelkonzepts und dann geht es endlich weiter mit den Selbstreferenzen.
Im, beim letzten Mal erwaehnten, Artikel von Ugai, T., et al werteten die Autoren unheimlich viele Daten aus.
Dabei ist natuerlich zu bedenken, dass jeder Datenpunkt ein Mensch ist … was mich direkt zum urspruenglichen und eigentlichen Problem zurueck bringt: man kann leicht auf den deprimierenden Gedanlen verfallen, dass alles was von einem am Ende uebrig bleibt, ein Zaehler in einer Statistik ist, der um eins hoch geht. Dann aber bildet sich dieses Problem auf sich selber ab: darueber will man nicht nachdenken und darum tun das die meisten Leute auch nicht. Aber wenn ich mich nicht mit meinen Aengsten beschaeftige, wie soll ich denn dann lernen denen zu begegnen? Und gerade das Thema des eigenen Todes ist unvermeidbar (und absolut).
Mir hilft dabei sehr dass ich dies eben in Datenpunkte abstrahieren kann. Womit der Kreis geschlossen ist … aber ich wollte das mal gesagt haben.
Wieauchimmer, beim Lesen des obigen Artikels erfuhr ich, dass bestimmte Krebsarten bei Menschen unter 50 Jahren mit so und so viel (wenigen!) Prozent pro Jahr zunehmen. Nach dem ersten Schreck stellte ich mir dann die Frage, wie hoch eigentlich die Chance ist, dass ich einen gewissen Krebs bekomme? Und wie sehr erhøht sich das, weil ich mich so wenig bewege?
Die gute Nachricht: die Zahlen sind im Allgemeinen viel (!) niedriger als man glauben mag … mit Einschraenkungen, aber darauf komm ich an anderer Stelle nochmal zurueck
Nochmal anders an Hand eines Fantasiebeispiels mit ausgedachten Zahlen: man nehme an, dass von 1000 Leuten 4 Schilddruesenkrebs bekommen (Bemerkung: die wirkliche Zahl ist eher 3 von 100-tausend … siehe die guten Nachrichten im vorherigen Satz). Desweiteren nehme man an, dass staendiges Sitzen diese Chance um 25 % erhøht (Bemerkung: viel Sitzen geht nicht auf die Schilddruese!). Dann waren das also 5 von 1000 … eine relativ geringe Chance und bei den Zahlen aus dem echten Leben ist die noch viel viel viel geringer.
Weiterhin gilt, dass selbst WENN ich einer von diesen fuenf Leuten bin, dann haette ich mit mehr als vier Mal høherer Wahrscheinlichkeit diesen Krebs auch dann bekommen wenn ich den ganzen Tag im Wald spazieren gehen wuerde!
Das ist wichtig, denn 25 % hørt sich nach URST viel an und auf den ersten Blick interpretierte ich das so, dass meine mir lieben und wichtigen Hobbies (Zocken, Lesen, Programmieren und Datenanalyse … nicht notwendigerweise in dieser (oder irgend einer) Reihenfolge) mich umbringen werden!
Wie aber bereits dieses Fantasiebeispiel mit viel zu groszen Zahlen zeigt, ist dem mitnichten so! Die erste Aussage zeigt, dass ich høchstwahrscheinlich eh keinen Schilddruesenkrebs bekommen werde. Die zweite Aussage bedeutet, dass selbst wenn es doch passiert, es nicht wegen meiner Hobbies war.
Diese Erkenntnisse fand ich spannend und deswegen machte ich mich daran, die wirklichen, altersspezifischen Zahlen zu finden … aber dazu mehr beim naechsten Mal (auch wenn ich oben schon ein Resultat gespoilert habe).
Beim letzten Mal wies ich die Existenz von 8.258 Archipelen nach. Ich dachte, dass es von Interesse ist mal zu schauen, aus wievielen Seiten die Archipele so bestehen … oder anders: Hurra! Eine neue Verteilung:
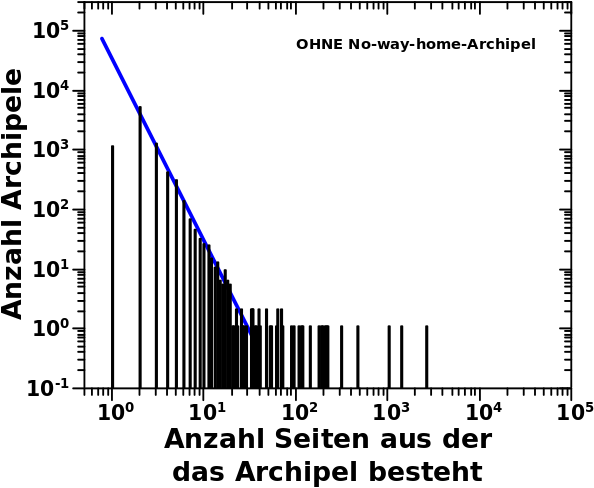
Wait! What! Bei doppellogarithmischer Darstellung verhaelt sich die Anzahl der Seiten pro Archipel nach einem maechtigen Gesetz ueber vier Grøszenordnungen (auf der Ordinate)!? Das ist jetzt schon das dritte Mal (hier war das zweite Mal), dass das passiert. Und wenn ich sowas sehe, dann bin ich mir gleich viel sicherer, dass das was ich rausgefunden habe kein Quatsch ist, sondern ein echter, dem Wikipedianetzwerk zugrunde liegende Mechanismus.
Davon abgesehen gibt es noch zwei andere Sachen die sich lohnen zu erwaehnen. Zum Einen, dass es ueber 1000 Archipele gibt, die aus nur einer Seite bestehen. Das muessen Seiten sein die sich auf LL0 selbst zitieren und wo das dann die einzige Zitierung bleibt. Die passen natuerlich nicht in das maechtige Gesetz, denn davon sollte es einfach nicht genug geben.
Zum anderen gibt es Archipele die aus mehr als 1000 Seiten bestehen. Schon bemerkenswert, nicht wahr. Hierbei wuerde ich ein aehnliches Phaenomen vermuten wie beim hier kurz besprochenen Bakhsh — eine zentrale Seite, die von vielen kleinen, selbst nicht zitierten Seiten jeweils einmal zitiert wird.
Bei den Archipelen die aus ein paar Dutzend bis wenigen hundert Seiten bestehen kønnte ich mir vorstellen, dass das so ’ne Art „abgeschlossene Themengebiete“ sind, fuer die sich die Welt nicht weiter interessiert.
Soweit dazu. Nun das Gleiche aber unter Beruecksichtigung des No-way-home-Archipels (ab hier als nwh-Archipel abgekuerzt), wie beim letzten Mal angekuendigt.
wie gesagt: ohne dieses finde ich 8.258 Archipele. Nun dachte ich zunaechst, dass halt noch eins dazu kommt und erschreckte mich, dass die Zahl aller Archipele dann bei 320.233 lag. o.O
Als ich mal drueber nachdachte fiel mir mein Fehler auf. Die „Insel der Unzitierten“ hat 320.089 „Einwohner“ die alle jeweils eine Insel der Stufe Null des nwhA sind. Das hatte ich uebrigens bei der Einfuehrung des nwhA falsch formuliert. Dort sagte ich, dass das nwhA aus 39 Inseln besteht. Dieser Fehler ist mir untergekommen, weil ich das Konzept der Archipele mehr oder weniger beim Schreiben entwickelte und das Konzept der „Stufen“ dort noch nicht benøtigt wurde. Richtiger haette es heiszen muessen, dass das nwhA aus 39 Stufen besteht. Macht aber nix, so ist das nun mal, wenn man versucht eine Erklaerung fuer ein bisher unbekanntes Phaenomen zu finden. Man tastet sich langsam vor, macht Fehler und behebt diese und am Ende tut man so als ob das alles eine gerade Linie gewesen waere. Letzteres ist ja nicht wahr und deswegen habe ich das hier mal drin gelassen … so wie ein paar meiner anderen Fehler.
Wieauchimmer, von diesen 320.089 Seiten gehen nur 124.139 Zitate weg. Dass bedeutet, dass ich hier fast 200k Archipele habe die aus nur einer Seite bestehen. Und selbst die ca. 125k Zitate die weg gehen, haben nur relativ kurze Linkketten. Die Allermeisten stoppen bereits auf der Stufe danach und es bildet sich gerade KEIN groszes, zusammenhaengendes Archipel. Das nwhA besteht also eigentlich aus unheimlich vielen einzelnen Archipelen, die aber alle die definierenden Eigenschaften des nwhA gemeinsam haben.
Gut, gut, das erklaert die hohe Zahl. Aber Moment mal sollte die dann nicht noch grøszer sein? 320.089 + 8.258 = 328.347 und nicht nur 320.233. Hier wuerde ich aber sagen, dass es mitnichten verwunderlich ist, dass die 451.792 Seiten die sich auf dem nwhA tummeln ’ne Verbindung zu den meisten anderen Archipelen haben. Fast alle von Letzteren „verschmelzen“ dann mit den vielen Archipelen des nwhA und das „fehlt“ dann in der Zaehlung.
Lange Rede kurzer Sinn: mit Zitaten zu den anderen Archipelen scheint das alles schon richtig zu sein.
Und nun das Gleiche wie oben nochmal … diesmal nicht als Balken-, sondern als Punktdiagramm, denn ich wollte obige Resultate zum Vergleich nochmal rein bringen und das waere zu unuebersichtlich geworden in der ueblichen Darstellung:
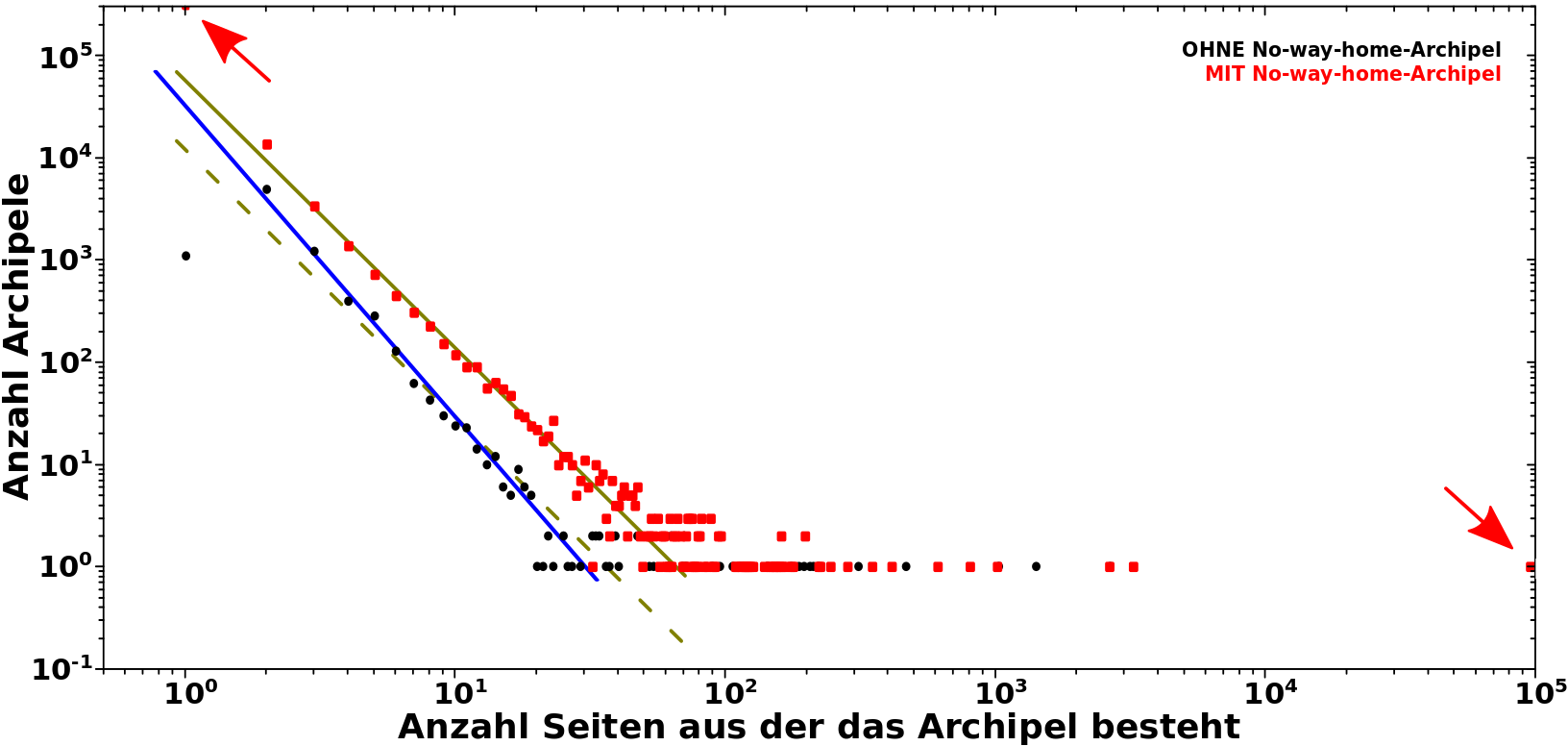
Der rechte Pfeil zeigt auf ein Archipel, welches aus fast 100k Seiten besteht. Das wundert mich nicht wirklich. Zum Einen aufgrund des oben erwaehnten „Bakhsh-Phaenomens“; Bakhsh selber hat schon ueber 50k Zitierungen von Seiten bei denen ich mir sehr gut vorstellen kann, dass die nicht weiter zitiert werden. Ein andere Seite dieser Sorte erwaehnte ich auch bereits im diesbezueglich oben verlinkten Artikel: Gmina. Man nehme eine solche Seite und 100 weitere Seiten mit dem gleichen modus operandi, die aber nur nur 1000 Zitaten von unbedeutenden Seiten bekommen, anstatt 50k Zitaten. Da braucht es dann maximal 50 Verbindungen untereinander. Letzteres halte ich fuer durchaus plausibel; 50 individuelle Verbindungen sind nicht so viel oder es kønnte auch nur ueber eine Seite geschehen, die bspw. alle weltweit unterschiedlichen Begriffe fuer „administrative Region“ zusammenfasst. Das Ganze kønnte natuerlich auch ueber viele kleinere (oben erwaehnte) „abgeschlossene Themengebiete“, anstatt ein paar „dicke“ Seiten geschehen. Was ich sagen will: die Existenz eines solch riesigen Archipels finde ich nicht sooo ungewøhnlich.
Der linke Pfeil zeigt auf das genaue Gegenteil; die vielen einzelnen, unzitierten und nicht auf andere Archipele zitierenden Seiten, welche Ein-Seiten-Archipele bilden (plus natuerlich die ca. 1000 Seiten, die nur soch selbst zitieren, aber die fallen hier nicht mehr all zu sehr ins Gewicht).
Das waren aber die eher uninteressanten Sachen. Viel spannender ist der Verlauf der Kurve fuer Archipele mit 100 oder weniger Seiten. Dieser entspricht auch hier wieder einem maechtigen Gesetz, angedeutet durch die olivgruene Linie. Hier passt sogar der Messpunkt fuer besagte Ein-Seiten-Archipele mit rein, was die Gueltigkeit dieses Gesetzes um ueber eine Grøszenordnung auf der Ordinate und nun sogar 2 Grøszenordnungen auf der Abzsisse erhøht.
Es macht den Anschein, dass dieses aber einen anderen Exponenten hat, als wenn ich die Archiple ohne das nwhA betrachte; die blaue Linie hat einen etwas anderen Anstieg. Prinzipiell kønnten hier natuerlich zwei verschiedene Mechanismen am Werk sein. Andererseits ist die Statistik fuer die schwarzen Punkte deutlich weniger gut und wenn ich die olivgruene Linie in diesen Bereich verschiebe (angedeutet durch die gestrichelte, olivgruene Linie), dann haette ich nicht all zu grosze Bauchschmerzen zu argumentieren, dass das durchaus passt.
Aber egal was hier auch im Detail passiert, wenn man das nwhA mit einbezieht, wird bestaetigt, dass die Grøsze der der Archipele sich nach einem maechtigen Gesetz verhaelt. Das festigt meinen „Glauben“, dass der von mir dargelegte Mechanismus der (verallgemeinerten) Archipele richtig ist und gewisse Aspekte des gesamten Wikipedialinknetzwerkes diesem unterliegen. … cool wa!
Ein Thema ueber das man nicht spricht … und (noch) eine Fortfuehrung der hier begonnenen Gedanken. Letztere gehen bei mir ja nun auch schon wieder zwei Dekaden zurueck, ein semi-abhaengiger Aspekt der an sich schon interessant ist … aber darum soll es nicht gehen.
Auch wenn ich hier auf ganz andere Dinge eingehen werde, so liegt die Motivation doch in dem worueber letztlich auch eine andere zur Zeit laufende Miniserie handelt:
[…] ich versuche zu lernen, mit der Absolutheit meiner eigenen Sterblichkeit umzugehen […] [indem ich] schwere Probleme in Teile [zerlege] die ich prozessieren kann … und oft kommen dabei Fragen und Antworten und Ideen und Ueberlegungen bei raus, die ganz unabhaengig vom urspruenglichen (oder eigentlichen) Problem durchaus interessant sind :) .
So ist das auch hier.
Ueberhaupt darauf gekommen bin ich, weil ich neulich ueber einen sehr interessanten Artikel von Ugai, T., et al. mit dem Titel „Is early-onset cancer an emerging global epidemic? Current evidence and future implications“ in Nature Reviews Clinical Oncology, 19, 2002, pp. 656–673 gestoszen bin (zur Zeitpunkt des Schreibens war das leider nicht verfuegbar bei meiner ueblichen Quelle).
„Early onset“ bedeutet in dem Zusammenhang, bevor man 50 ist und das ist von Interesse, denn junge Menschen bekommen _deutlich_ seltener Krebs und wenn sich da was messbar aendert fuer die Menschheit, dann ist es wichtig die Gruende heraus zu finden.
Wieauchimmer, dort fand ich heraus, dass …
[…] prolonged sedentary television viewing time was associated with an increased incidence of early-onset [colorectal cancer] independent of exercise and BMI.
Ich guck zwar nicht all zu viel TV, aber ich zocke viel und sitze auch auf Arbeit den ganzen Tag. Deswegen war ein naheliegender Gedanke: „Verdammte Kacke .oO(Wortspielkasse)“. Meinem normalen Bewaeltigungsmechanismus folgend versuchte ich diesen gigantischen Schreck in kleinere, verstehbare Teile zu zerlegen.
Um diesen ersten Beitrag mit einer positiven Note abzuschlieszen eine gute Nachricht: ich kam zu dem Schluss, dass ich mir darueber nicht wirklich den Kopf zerbrechen muss … aber dazu komme ich erst an spaeterer Stelle … denn der Weg zu dieser Erkenntnis war gepflastert mit voll spannenden Sachen … und darueber geht diese Miniserie.
Nach der vielen Theorie die letzten beiden Male heute nun Messwerte :) … aber der Reihe nach.
Das Ende des letzten Beitrages aufgreifend: waehrend es (beinahe) unvermeidlich schien, dass es eine „Insel der Unzitierten“ geben muss, so galt dies nicht fuer die Existenz des No-way-home-Archipels. In den Daten konnte ich Letzteres aber direkt nachweisen. Kann ich dies auch bzgl. der Archipele der erweiterten Form?
Wie erwaehnt, musste ich zur Klaerung dieser Frage eine schøne rekursive Funktion schreiben. Ich wuerde diese gerne im Detail diskutieren, denn ich finde rekursive Funktionen voll toll und es ist total schade, dass ich die nicht øfter brauche. Ich befuerchte allerdings, dass dies kontrapodutkiv waere. Deswegen muss ich die Diskussion anders aufziehen.
Bisher arbeitete ich derart, dass ich fuer jede Seite wusste, welche anderen Seiten diese zitiert und folgte dem Linknetzwerk einen Schritt nach dem anderen. Hier nun muss ich zunaechst das „Spiegelbild“ zu diesen Daten nehmen, ich musste also fuer jede Seite bestimmen, von welchen anderen Seiten diese zitiert wird. Dann folgte ich dem Linknetzwerk rueckwaerts. Ich schaute also fuer eine Seite von wem diese zitiert wurde und bei den zitierenden Seite schaute ich wer diese zitierte und so weiter. Das ist die Rekursion und die fuehrte ich so lange fort, bis keine neuen zitierenden Seiten mehr auftauchten.
Wieauchimmer, rekursive Funktionen haben einen Nachteil: rein praktisch kann ein Computer eine Rekursion nicht beliebig tief folgen. Jedes Rekursionslevel benøtigt eigene Ressourcen und davon habe ich nicht unendlich viele in meinem Rechner verbaut.
Deswegen schraenkte ich einen Parameter fuer die Analyse folgendermaszen ein: wenn eine Seite von mehr als 69 anderen Seiten zitiert wurde, so wird die Rekursion abgebrochen. Das ist nicht die ganze Wahrheit, 69 ist das Limit fuer zitierende Seiten die ich auf einem gegebenen Rekursionslevel noch nicht „gesehen“ habe. Die Anzahl aller zitierenden Seiten kønnte also betraechtlich høher sein.
Ich denke, dass dies Limitierung plausibel ist, denn wenn eine Seite von mehr als 69 Seiten zitiert wird, so ist es sehr unwahrscheinlich, dass alle diese _nicht_ irgendwie eine Verbindung zum „groszen Auszerhalb“ haben. Letzteres wuerde dann auch die urspruengliche Seite mit der ich startete mit diesem verbinden und damit kønnte die Startseite nicht Teil eines Archipels sein.
Ich testete bis zum Wert 1500 (ab 2000 wird die Rekursionstiefe so grosz, dass ich in oben erwaehnte Ressourcenlimitierung laufe, bzw. laeszt Python das nicht mehr zu um eben dies zu vermeiden). Der „Umschlagpunkt“ ab dem keine weiteren Archipele mehr dazu kamen lag bei 68. Der Wert 69 kommt durch das Abfaerben des juvenilen Humors, des jungen Mannes der bei mir wohnt, auf mich zustande.
Desweiteren liesz ich das No-way-home-Archipel auszen vor. OKOK, das stimmt nicht ganz. Ich nahm es einmal mit in die Analyse rein. Dann dauerte Selbige aber ca. 10 Stunden, anstatt ein paar Minuten. Deswegen habe ich das nur ein Mal gemacht. Ich bespreche die Unterschiede bei den Ergebnissen an anderer Stelle, weil ich denke, dass dies durchaus lehhreich sein kann.
Aber genug der Vorrede und Vorhang auf fuer die Ergebnisse; zunaechst das bereits Bekannte.
Zum ersten Balken der Verteilung der Maxima der individuellen Verteilungen der Selbstreferenzen tragen 474.653 Seiten bei. Davon gehørten 7649 zu Seiten die sich auf LL0 selbst zitieren (von insgesamt 83.435 Seiten mit dieser Eigenschaft) und auf keinem Linklevel mehr als eine Selbstreferenz haben. Somit blieben 467.004 uebrig, die erklaert werden mussten.
Daraufhin unternahm ich Untersuchungen, die zur Entdeckung des No-way-home-Archipels fuehrten. Die grøszte „Insel“ dieses Archipels ist die „Insel der Unzitierten“ mit 320.089 Seiten und insgesamt „wohnen“ auf dem gesamten Archipel 451.792 Seiten.
Damit blieb fuer nur noch 15.212 Seiten ungeklaert, warum diese zum Signal in besagtem ersten Balken beitragen. Dies fuehrte zu den Ueberlegungen bzgl. der Erweiterung/Verallgemeinerung des Archipelkonzepts. Hier kommen dann endlich die neuen Ergebnisse.
Ohne jeglichen Einfluss des No-way-home-Archipels finde ich fast 30-tausend Untergruppen. Wenn diese zu den grøsztmøglichen, zusammenhaengenden (Ueber?)Gruppen zusammen gezogen werden, bleiben noch 8.258 Archipele. Hurra! Die Existenz von (konzeptuell erweiterten/verallgemeinerten) Archipelen ist bewiesen. Nun wird es spannend, ob ich damit auch das erklaeren kann, was ich erklaeren will.
Von den 15.212 Seiten die zitiert werden, aber keine Selbstreferenzen haben, befinden sich 9995 auf diesen Archipelen. Streng genommen muesste ich noch schauen, ob die Zitierungen auch wirklich von niedrigeren „Stufen“ kommen. Aber rein logisch muss das ja so sein, denn wenn sie von høheren Stufen kommen wuerden, dann muessten diese Seiten ja Selbstreferenzen haben. Deswegen spare ich mir das Schauen an dieser Stelle mal ausnahmsweise.
Das ist alles was ich aus den ganzen langen Ueberlegungen und den vielen Stunden die ich mit der Analyse dazu zubrachte herauskam … so viel geschrieben (nicht nur in diesem Beitrag), fuer nur eine einzige Zahl … das kønnte man als eher mickrige Ausbeute sehen, wenn da nicht die Freude am Erkenntnisgewinn und jede Menge neues, konzeptuelles Wissen ueber das Linknetzwerk an sich waeren … aber dazu mehr an anderer Stelle (wie es z.Z. aus sieht als Weihnachtsbeitrag).
Und selbst mit dieser Zahl bleiben 5217 Seiten uebrig … da dachte ich zunaechst .oO(verdammt) … um dann erleichtert fest zu stellen, dass ich ja noch gar nicht solche Seiten in Betracht gezogen hatte, die keine Links haben, aber zitiert werden.
Seiten ohne Links kennen wir schon von den „ganz fruehen Aussteigern“ aber nicht alle von denen werden zitiert, weswegen ich nicht einfach die Zahl von dort nehmen kann. Ist letzteres der Fall, dann sind die schon bei den „Bewohnern“ der „Insel der Unzitierten“ gezaehlt worden. Aber siehe da, 5202 Seiten werden zitiert, haben aber keine Links … hurrah … oder eher: AAARGHAGAHGRHG … da bleiben naemlich immer noch 15 Seiten uebrig.
An dieser Stelle dachte ich zunaechst: .oO(15 von fast 500k … da ist der erste Balken ja (fast) komplett erklaert und das „fast“ ist ein sehr sehr sehr kleines „fast“ … das kann ich getrost alles in den Fehler schieben … auszerdem habe ich mit den Archipelen so viel gelernt, eigentlich kønnte ich hier auch aufhøren).
Aber ein Teil meines Wesens ist, dass ich erst „aufgebe“, wenn ich wirklich nicht mehr weiter weisz. Und hier hatte ich zwar zunaechst keine Idee, aber das Beduerfniss, da noch laenger drueber nachzudenken, auch wenn es nur noch 15 Seiten waren, die einer Erklaerung bedurften.
Und ich gruebelte und gruebelte und kam einfach auf keinen plausiblen Mechanismus fuer diese 15 Seiten.
Dann ging ich auf einen Spaziergang … und wie so oft auf Spaziergaengen scheint die Bewegung auch mein Gehirn in Gang zu bringen, denn pløtzlich hatte ich eine Erklaerung parat.
Bei diesen 15 kønnte es sich um Seiten handeln, die von „Auszen“ zitiert werden (also zu keinem Archipel gehøren), die mindestens einen weiterfuehrenden Link haben (also nicht unter die obigen 5202 Seiten fallen, fuer die das nicht gilt) aber wo die Linkkette dann schnell ins Leere fuehrt. Also weitere „fruehe Aussteiger“ aber nicht auf LL0 wie oben, sondern auf LL1-3.
Und tatsaechlich! Diese 15 Seiten werden alle aus dem groszen Wikipedialinknetzwerk (und auch von Archipelen, aber nur Ersteres ist relevant) zitiert. Manche sogar mehrfach. Desweiteren haben alle nur einen Link und alle diese Links fuehren zu Seiten die keine weitern Links haben. … YEEEEEEEES!!! … I AM AWESOME!
Tja, und damit ist das Signal im ersten Balken komplett erklaert und das Mysterium ist keins mehr! Toll wa!
Vor einer Weile liesz ich mich darueber aus, dass die Rolle der Kirche zu Galileis Zeiten mitnichten bøse, garstig und rueckwaertsgewandt war. Vielmehr hat diese in weltlichen (!) Fragen mittels der damaligen (!) „wissenschaftliche Methode“ gearbeitet und die Wissenschaften sogar aktiv unterstuetzt. Nur in geistlichen Fragen liesz sie sich nicht reinreden. Mittlerweile denke ich, dass das (unter den damaligen Umstaenden!) durchaus gerechtfertigt war. Fuer die Kirche war ein Galilei der was in spirituellen Dingen erzaehlt ungefaehr so wie wenn mir ein Koch sagt, dass Impfen zu Autismus fuehrt. Im besten Fall nervig, im schlimmsten Fall den øffentlichen Frieden (zer)størend.
An anderer Stelle liesz ich mich ueber Newton, und wie dieser eigentlich gar kein Wissenschaftler im heutigen Sinne war, sondern vielmehr einer der letzten Magier.
Wieauchimmer, Giordano Bruno ist eine weitere mythische Figur. (Auch) von ihm wird gerne behauptet, dass er ein ganz aufrichtiger Wissenschaftler war und fuer die (einzig wahre) Wissenschaft gestorben ist. Junge, Junge, da hab ich neulich was zu gelesen. Naemlich den Artikel von Lawrence S. Lerner und Edward A. Gosselin mit dem Titel „Was Giordano Bruno a Scientist?: A Scientist’s View“ im American Journal of Physics 41, 24, 1973, pp. 24–38 … *hust*.
Ich fand den Artikel schwer zu lesen und den angefuehrten Beispielen schwer zu folgen. Aber die Schlussfolgerung ist diese: Bruno hat NICHT die damaligen wissenschaftlichen Argumente durchdrungen, sondern eher nur nachgeplappert. Die Autoren geben dafuer gute Argumente anhand von Brunos Buechern, im Vergleich mit anderen zeitgenøssischen Quellen. Er war also mitnichten ein Wissenschaftler, auch nicht unter damaligen Gesichtspunkten und wir romantisieren das, weil es uns besser in den Kram passt.
Bruno tat dies um seine eigene, eher religiøs/spirituell ausgerichtete Agenda zu førdern … Uff! … was fuer eine Verkuerzung der Argumente und des Geschehenen, aber letztllich laeuft es darauf hinaus.
Die Autoren schreiben dazu schon in der Zusammenfassung:
Bruno’s “scientific” arguments do not exhibit any understanding of scientific reasoning or purpose. Rather they serve the totally unrelated function of allegorical descriptions of a metaphysical relationship between Man and God […]. Bruno sees Nature as the signature of God, and he believes that this signature can best be perceived through the hieroglyph of the Copernican theory.
Auszerdem war er ein Querulant und Størenfried, der sein Leben lang an keinem Ort verweilen konnte, weil er es sich mit den Leuten immer dermaszen verscherzte, dass sein Leben in Gefahr war. Am Ende konnte er nirgendwoanders mehr hingehen und kehrte in eine Gegend zurueck von der er wusste, dass er dort eingesperrt wird.
Letzteres ist auch der Unterschied zu Galilei. Ich kenne keine einzige Wissenschaftlerin (!) die fuer ihre Wissenschaft gestorben ist (dito fuer die Wissenschaftler). Galilei hat widerrufen, weil ein lebender Mensch sich wenigstens Gedanken machen kann ueber wissenschaftliche Belange und das nehmen ihm zu kurz denkende Menschen heutzutage uebel. Oder anders: Wissenschaftler sind eben gerade KEINE Maertyrer, denn ihnen stehen andere Wege der Wahrheit zur Verfuegung.
Und hier liegt der Hase im Pfeffer, denn der Begriff Maertyrer ist zurecht (fast?) ausschlieszlich dem religiøsen Bereich zugeordnet. Bruno wird nun gemeinhin als Maertyrer der Wissenschaft angesehen … ein Widerspruch in sich und dann auch noch falsch (siehe oben).
Aber ACHTUNG! Das bedeutet NICHT, dass Bruno und seine Buecher irrelevant waren (oder sind). Ganz im Gegenteil! Seine philosophischen Argumente haben spaeter wichtige Wissenschaftler wie Galilei oder Huygens massiv beeinflusst. Bruno spielt in der Entwicklung der Wissenschaft also eine wichtige Rolle. Aber nicht als (Proto)Wissenschaftler, wie es der heutige, weitverbreitet Narrativ ist. Und das wollte ich mal gesagt haben.