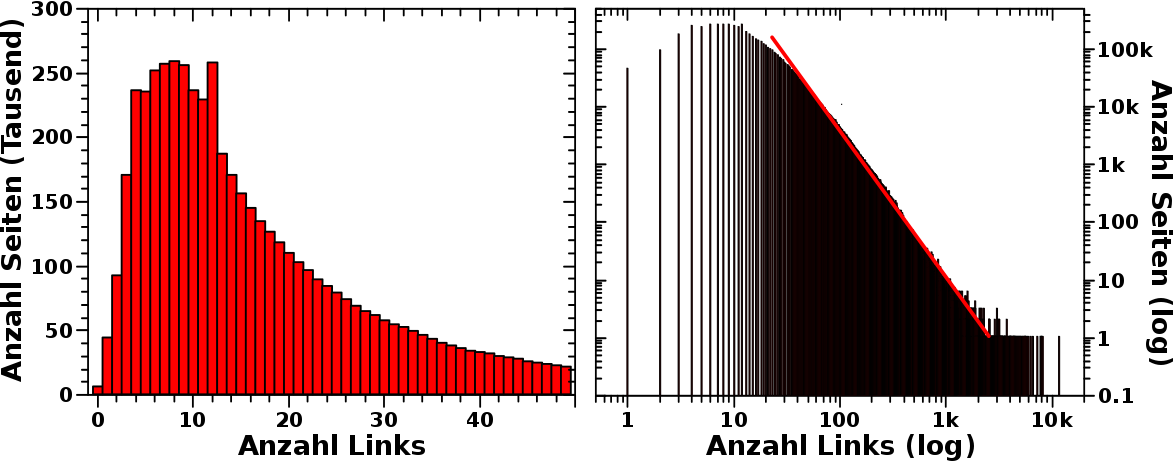
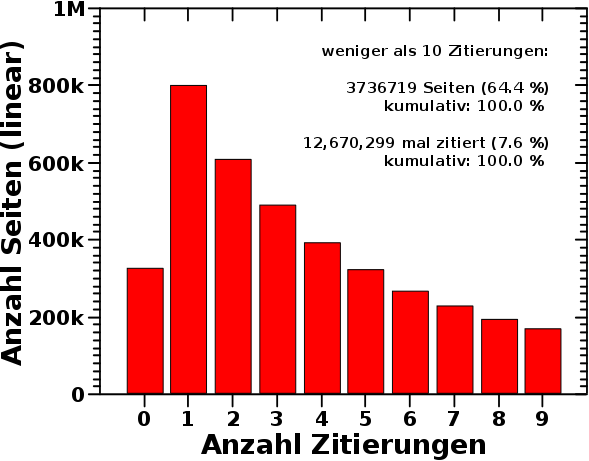
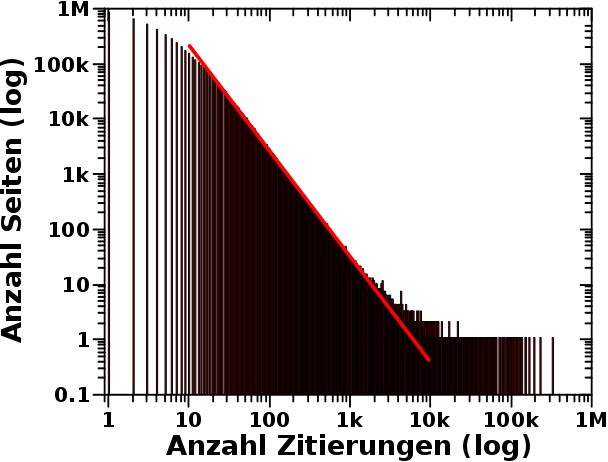
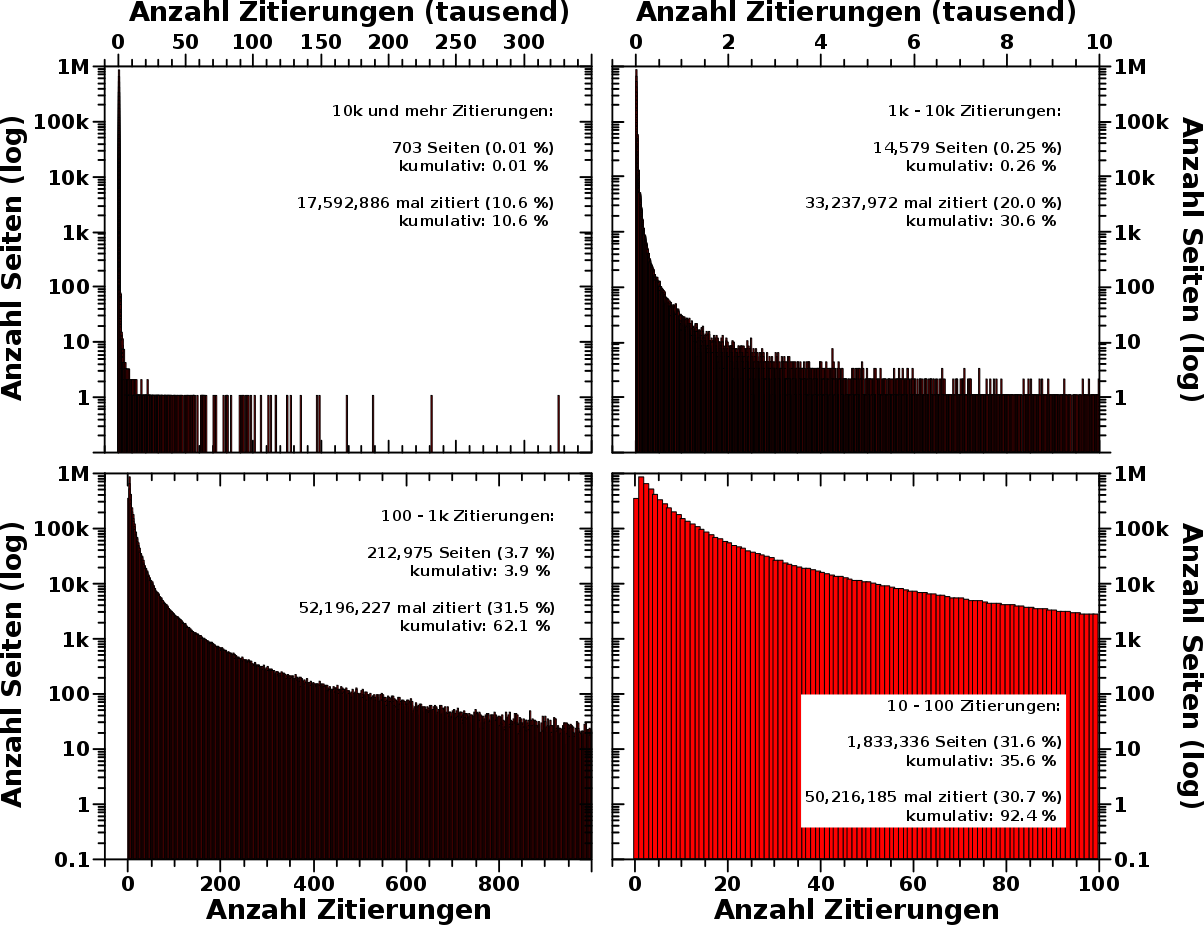
Geburtstagsbeitrag! Und wie so oft zu dieser Gelegenheit lasse ich mich lang ind breit ueber ein Thema aus, was mich im Detail beschaeftigt(e), aber mglw. nicht so richtig interessant ist fuer den Rest der Menschheit.
Beim letzten Mal in dieser Reihe schrieb ich:
Vornamen sind Moden unterlegen … aber Moden sind zyklisch. Wenn man das ueber mehrere Jahrzehnte betrachtet, dann sollte sich da nicht viel aendern. … Das nahm ich zunaechst an, wusste aber auch, dass dies ein schwacher Punkt ist. Deswegen schaute ich mir die Aenderung der 13 meistvergebenen Vornamen in den letzten 140 Jahren mal genauer an und muss sagen, dass diese Annahme so nicht ganz richtig ist. Moden scheinen traditionelle Namen zwar nicht zu verdraengen, aber gesellschaftliche Entwicklung schon.
Da mache ich aber mal am besten einen eigenen Beitrag draus. […]
Und darum soll es heute gehen.
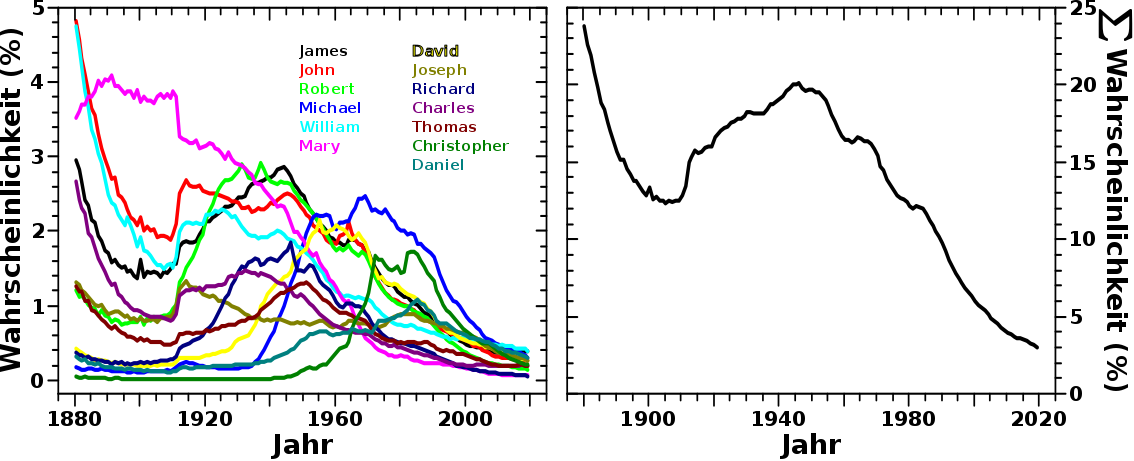
Wenn man sich die Popularitaet besagter 13 Vornamen anschaut, die seit 1880 am haeufigsten in den USA vergeben wurden, erhaelt man das linke Diagramm in diesem Bild:
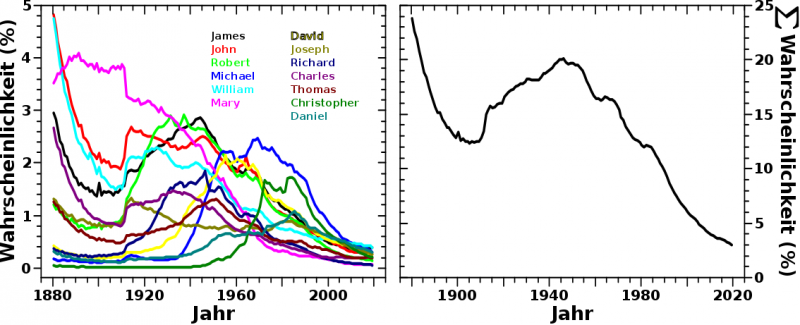
Hier sieht man auch, warum ich erstmal annahm, dass Moden zwar kommen und gehen, dies aber ueber laengere Zeitraeume keinen groszen Unterscheid machen sollte. Sicher, Anfang des 20. Jahrhunderts waren „John“ und „Robert“ viel beliebter als „Michael“ oder „Christopher“ aber die Høhe der einzelnen Kurven aendert sich jetzt nicht so stark … auszer so ab ca. 2000 … mhmmm … das machte mich etwas stutzig und ich schaute mir mal die kumulative Wahrscheinlichkeit fuer diese 13 meistvergebenen Namen an (Diagramm auf der rechten Seite).
Dort scheint die Aussauge „da aendert sich nicht viel“ bis ungefaehr 1980 zu stimmen. Innerhalb gewisser Variation erhalten 15 % der Neugeborenen einen der dreizehn meistvergebenen Namen. Aber mit dem Beginn meiner Generation aenderte sich das … drastisch! … Das letzte Adjektiv ist durchaus angebracht, wenn man mal betrachtet wie stark die aufsummierte Wahrscheinlichkeit fuer die dreizehn (vormals) meistvergebenen Namen herunter geht.
Das ist dan auch der Grund, warum ich schrieb, dass gesellschaftliche Entwicklungen (traditionelle) Namen dann doch verdraengen. Die gesellschaftliche Entwicklung hier kønnte sein, dass die Jugendlichen welche von den sogenannten 69’ern gepraegt wurden. Damit meine ich weniger die Studenten welche „mittendrin“ waren, sondern die (oft deutlich) juengeren, sympathisierenden Jugendlichen, die noch zur Schule gingen. Ab Mitte der 70’er Jahre fingen diese an Kinder zu haben. Besagte Zeit hat das Vertrauen in und das Gehorchen von (traditionellen) Autoritaeten nachhaltig geschwaecht. Es ist nicht all zu weit hergeholt, dass sich das auch in der Namensgebung ausgedrueckt hat, denn die (damals) „frischen“ Eltern fuehlten sich nicht mehr so stark daran gebunden, den Sohn nach dem Opa zu benennen.
ABER: man kønnte durchaus argumentieren, dass die Entwicklung schon ab ca. dem den 50’er Jahren (schwer zu verorten ob Anfang, Mitte oder Ende) losging, wenn auch zunaechst zøgerlich. Dies kommt ziemlich genau zusammen mit der Etablierung des Individualismus (insbesondere in den USA), als „Gegenstueck“ zum sog. Kommunismus, im kalten Krieg. Im oberen Diagramm macht sich das nicht so bemerkbar innerhalb der (natuerlichen) Variation vor ca. 1980. Es ist aber deutlicher zu erkennen, wenn man sich anschaut, wie vieler Vornamen es bedurfte um 50 % der neugeborenen Kinder eines Jahres zu benennen:
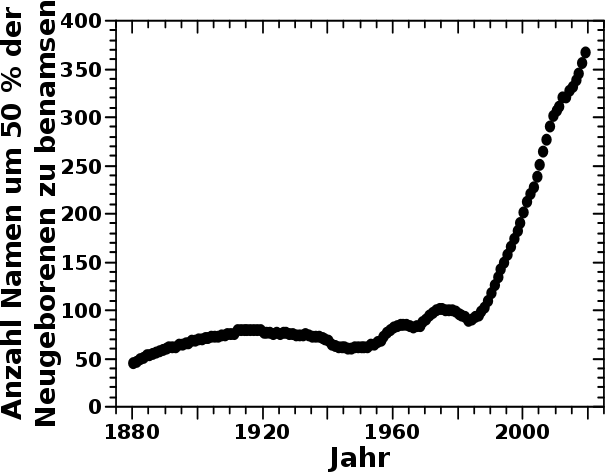
Das ist zwar keine gerade Linie, aber dennoch bis ca. den 50’er Jahren eine ziemlich flache Kurve. Es brauchte nur ca. 75 Namen (plusminus ein paar) um besagte 50 % aller Kinder zu benennen. Ab den 50’er Jahren steigt die Kurve kontinuierlich und ab den 60’er Jahren uebersteigt es die vorherigen, etliche Jahrzehnte vorherrschenden (kleinen) Schwankungen. Mit dem Start der 80’er Jahre „geht dann die Post ab“.
Ach so, beim ersten Bild ist nur ein Frauenname dabei (der 14 Name waere auch ein Frauenname gewesen, aber mir gingen die Farben aus). Ich vermute, dass dies zwei Hauptursachen hat. Zum Einen denke ich, dass Maenner lange Zeit etablierte (darob eines besseren Wortes) Namen bekommen haben um eine „Familientradition“ beizubehalten oder einen Vater zu „ehren“ oder sowas. Kennt man ja aus Film und Fernsehen, mit den vielen Juniors. Von Frauen kenne ich das eigentlich gar nicht. Das Anhaengsel „Junior“ scheint es nur fuer Maenner zu geben. Dies fuehrt natuerlich zu mehr Vielfalt bei den Frauennamen und somit insgesamt weniger Frauen die den gleichen Namen haben (Ausnahme: „Mary“).
Zum Zweiten ist das mglw. auch ein Defizit in den Daten, denn ich habe insgesamt weniger Frauen in den Daten, es wurden also weniger Maedchengeburten gemeldet. Das wundert mich ueberhaupt nicht, denn Hausgeburten waren noch sehr sehr lange der Standard:
In the United States […] around 1900, when close to 100% of births were at home. Rates of home births fell to 50% in 1938 […].
Es gab also keine automatische Datenaufnahme. Und hier spielt dann der bereits beim letzten Mal erwaehnte historische Sexismus rein. Die Geburt eines Jungen wurde auch bei einer Hausgeburt gemeldet, denn dieser sollte ja mal der Erbe werden und das musste rechtlich abgesichert sein.
Fuer das urspruengliche Problem (Laenge der Wikipediatitel) spielt das aber aus zwei Gruenden keine Rolle. Zum Ersten ist die Verteilung der Laenge der Frauen und Maennernamen so gleich, dass man (beinahe) deckungsgleich sagen kønnte. Zum Zweiten ist die Meldung von der Geburt eines Maedchsen dann trotzdem immer noch ein gleichverteilter Prozess. Das bedeutet, dass die Wahrscheinlichkeit fuer die Meldung eines bestimmten Maedchennamens gleich bleibt, auch wenn die totale Anzahl gemeldeter Maedchengeburten geringer ist.
Ach so … der Titel dieses Beitrags wird ersichtlich, wenn man bedenkt, dass ca. 20- bis 30-jaehrige uns im 2. Weltkrieg von den Nazis befreiten. 20 bis 30 Jahre vorher war aber „John“ beliebter als „James“. Das kehrte sich erst ab den 30’er Jahren um. Der Unterschied war nun aber auch nicht so grosz … deswegen ist der Titel des Film zu 85 % richtig … tihihihi.
Es passt dann aber, dass James Dean als _DER_ Filmstar der 50’er bis heute bekannt ist.
Nun wollte ich aber wissen ob diese Veraenderungen einen bleibenden Effekt haben und wie stark dieser ist.
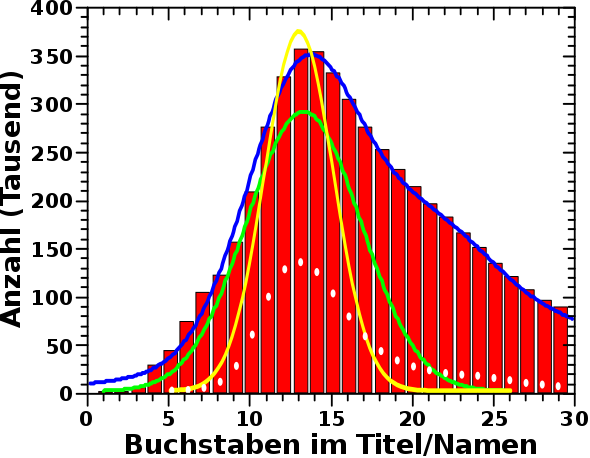
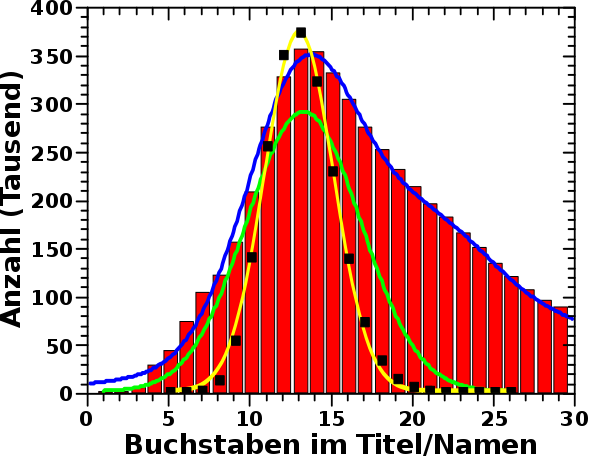
Bei meinen urspruenglichen Betrachtungen, bzgl. der Verteilung der Laenge der Wikipediaartikel und wie das Maximum erklaert werden kønnte, habe ich alle Vornamen, und wie oft diese in den letzten 140 Jahren vergeben wurden, aus allen Jahren zusammengezaehlt und die Waehrscheinlichkeit fuer meinen Namensgenerator nach diesen „totalen Zahlen“ berechnet. Ich erstellte 1 Million Frauen- und 1 Million Maennernamen und das (normalverteilte) Resultat ist im verlinkten Beitrag zu finden.
Nun kam oben aber heraus, dass sich die beliebtesten Namen eben doch aendern und ich wollte wissen, ob das einen deutlichen Einfluss auf die Verteilung der Laenge der Namen hat. Deswegen modifizierte ich den Namensgenerator derart, sodass fuer jedes Jahr jeweils 100-tausend Maenner- und Frauennamen erstellt wurden (mit den sich jaehrlich aendernden Wahrscheinlichkeiten). In den Resultaten sah ich einen Trend und dachte mir, dass das schon stimmen kønnte. Weil der Effekt aber relativ klein war, wollte ich nicht ausschlieszen, dass es sich mglw. doch um ein Artefakt handelt und nicht echt ist. Deswegen liesz ich meinen Laptop nochmal 15 Stunden oder so rødeln und erstellte pro Jahr jeweils 300-tausend Frauen- und Maennernamen. Die Statistik wurde dadurch viel besser … und die erwaehnten Resultate wurden reproduziert. Im Folgenden zeige ich die Resultate des 600-tausend Namen pro Jahr Laufes.
Die 140 Verteilungen bzgl. der Laenge der Namen sehen so aus:
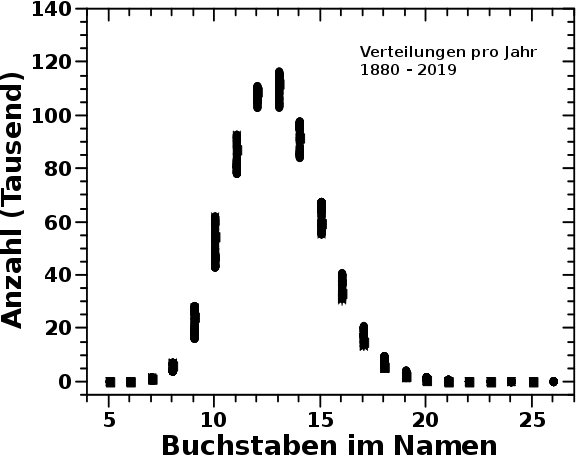
Uffda! Das ist viel auf einmal und muss der Reihe nach betrachtet werden.
Erstens „verschmieren“ sich die Punkte sehr. Das war zu erwarten und faellt in der Physik immer erstmal unter das beruehmte „Rauschen“. Die Frage war nun, ob das Rauschen ein Signal enthaelt? Bspw. liegt die kleinste Anzahl der Namen mit 10 Buchstaben liegt im Jahre 2015 und die grøszte Anzahl im Jahre 1891. Bei den Namen mit 15 Buchstaben hingegen dreht sich das um (høhere Anzahl zu spaeteren Jahren).
Gibt es mglw. ueber die Jahre einen Trend hin zu laengeren Namen? Das waere dann ja genau das was ich wissen will. Weil nur zwei Buchstabenlaengen nicht ausschlaggebend sind, schaute ich mir deswegen die aufsummierte Anzahl alle Namen mit Buchstabenlaengen links bzw. rechts des Maximums an.
Und hier kommt dann die zweite Beobachtung dazu. Jede individuelle Verteilung laeszt sich mit einer Normalverteilung beschreiben. Das ist gut, denn wenn es tatsaechlich eine „Umverteilung“ hin zu laengeren Namen gibt, dann sollte sich die Position des Maximums der jaehrlichen Gaussverteilung zu grøszeren Werten verschieben. Und diese beiden Resultate sind hier zu sehen:
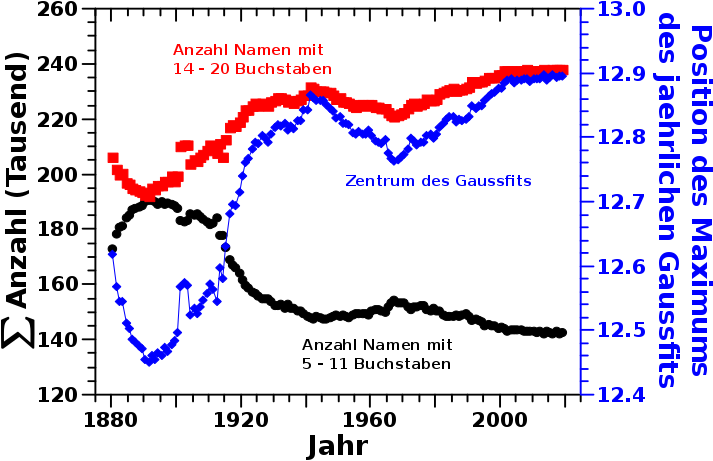
Zwischen der letzten Dekade des 19. Jahrhunderst bis ca. zu den 40’er Jahren des 20. Jahrhunderts wurden kuerzere Namen (schwarze Punkte) unbeliebter. Dies ging einher mit erhøhter Popularitaet laengerer Namen (rote Quadrate). Beide Kurven scheinen aber nur auf den ersten Blick symmetrisch. Wenn man genauer hinschaut sieht man, dass die Popularietat laengerer Namen im besagten Zeitraum linear ansteigt und der Anstieg ziemlich kontant ist. Der Rueckgang der Popularitaet kuerzerer Namen hingegen verlaeuft in zwei Phasen. Zunaechst „zøgerlich “ bis ca. 1912 um danach umso staerker vonstatten zu gehen.
In den schwarzen Kurven betrachte ich aber nur die Daten links und rechts vom Maximum (Namen mit 12 und 13 Buchstaben). Die Beobachtung liesze sich erklaeren, wenn sich die Zunahme der laengeren Namen zunaechst aus besagtem Maximum „speist“. Dass Namen also nicht einheitlich bspw. einen Buchstaben laenger wurden, sondern die ersten 20 Jahre Namen der Laenge 12 (oder 13) staerker durch laengere Namen „ersetzt“ wurden als Namen mit weniger Buchstaben. Wie oben erwaehnt verschieben beide Prozesse die Position des Maximums. Ein „Schaufeln der Daten“ vom Maximum nach rechts sollte aber eine langsamere Aenderung zur Folge haben, denn der Anteil links vom Maximum ist ja „noch da“ und muss bei der Anpassung mit einer Normalverteilung beruecksichtigt werden.
Und das ist dann auch genau was ich in der blauen Kurve sehe. Die Position des Maximums der jaehrlichen Gausskurve verschiebt sich nach rechts, aber bis ca. 1912 ist die Aenderung dieser Aenderung langsamer als danach (bis ca. 1930, wenn dieser Prozess sich allgemein deutlich verlangsamt).
Dies macht sich natuerlich auch in der Amplitude (schwarze Punkte) und Breite (rote Quadrate) der jaehrlichen Gausskurven bemerkbar:
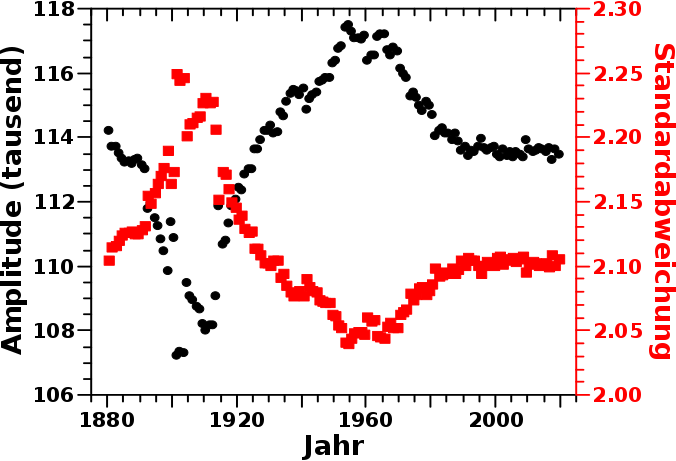
Bis ca. 1912 nimmt die Breite der Gausskurve zu und die Amplitude derselben ab. Genau so wie es nach der obigen Erklaerung sein sollte. Danach „erholt“ sich die Amplitude und die jaehrliche Gausskurve wird wieder schmaler. Letztere Beobachtungen bedeuten, dass es ab ca. 1912 NICHT zu einer gemeinsamen Verschiebung-um-einen-Buchstaben der gesamten Verteilung (oder zumindest des „kurzen“ Teils) kommt. Vielmehr ist es so, dass die Umverteilung vom Maximum (stark?) nachlaeszt und besagtes Maximum ab dann wieder (von links) aufgefuellt wird. Die „primaere Quelle“ des Umverteilungsprozesses „tauscht“ sozusagen den Platz mit der vormals „sekundaeren Quelle“ (und zwangslaeufig vice versa).
Interessant ist, dass die Amplitude auch nach 1940 weiter waechst, waehrend die Breite der Kurve weiter abnimmt. Es kommt also bis ca. 1960 zu einer teilweisen „Rueckbesinnung“. Laengere Namen werden zugunsten von Namen der Laenge 12 (oder 13) „aufgegeben“. Dies gilt auch (aber nicht so stark) fuer noch kuerzere Namen, wie man im Diagramm mit der aufsummierten Anzahl sieht.
Ab ca. den 70’er Jahren nimmt die Popularitaet laengere Namen weiter zu, aber laengst nicht so stark wie Anfang des 20. Jahrhunderts und ab ca. 2000 hat sich der Prozess stabilisiert.
Das hier sind zwar eher subtile Veraenderungen aber diese sind robust. Zwei Sachen (welche mir vermutlich fuer immer verborgen bleiben werde) wuerde ich gerne wissen.
1.: Fand das auch im echten Leben statt (denn die Namen hier sind ja nur simuliert)? Und als Modifikation: wie sieht das in anderen, vergleichbaren, westlichen Laendern aus?
2.: Was sind die Gruende fuer die Veraenderungen? Die Trends sind definitiv keine kurzfristigen Moden. Das zieht sich teilweise ueber Generationen hin. Aber ich spekulierte da bereits oben.
Damit sind diese Nebenbetrachtungen abgeschlossen. Beim naechsten Mal dann endlich wieder mehr zu den eigentlichen Wikipediadaten (denn das ist ja noch lange nicht abgeschlossen).
Apropos, die hier gesehenen Veraenderungen sind zwar robust, aber so gering, dass sich das in den Wikipediatiteln wenn ueberhaupt nur sehr wenig bemerkbar machen sollte. Dies vor allem deswegen, weil bereits das Vorhandensein von Doppelnamen (oder Berufsbezeichnungen) deutlich staerkere Auswirkungen haben sollten. Sowohl von der Menge (weil das 100-tausende sind) als auch vom Effekt (weil die „Verlaengerung“ eines Namens durch diese zwei Prozesse mehr als 10 mal grøszer ist als die oben beobachtete Verschiebung um 0.4 Buchstaben ueber 130 Jahre.
Aber das soll nun genug sein … ein wuerdiger Geburtstagsbeitrag in meinen Augen :)