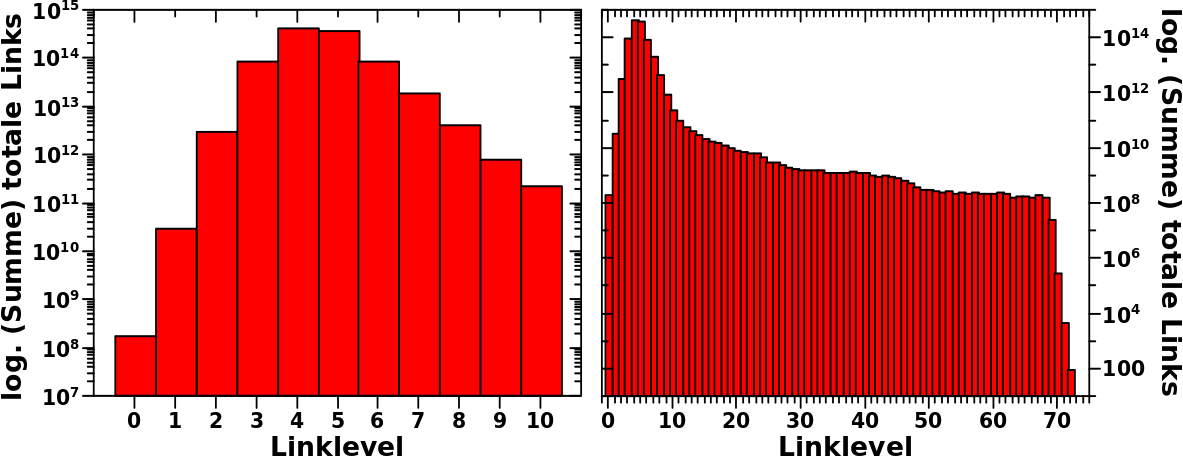
Die Gesamtverteilung der totalen Links pro Linklevel (siehe die erste Grafik hier) ist zusammengesetzt aus 5,798,312 Einzelverteilung. Im Allgemeinen gleichen die Einzelverteilungen der Gesamtverteilung insofern, dass der Anstieg zum Maximum sehr schnell ist und Selbiges bei LL4 oder LL5 erreicht wird. Danach geht die Anzahl der totalen Links pro LL wieder runter, aber es bleibt ein langer „Schwanz“ zu hohen Linkleveln mit kleinen Zahlen fuer diese Grøsze.
Interessiert haben mich nun grobe Abweichler. Also Seiten, deren Maximum viel frueher oder viel spaeter auftauchten. Hier zwei Beispiele in denen die Verteilung nicht als Balkendiagramm sondern als durchgehende Linie dargestellt wird, damit man mehr sieht:
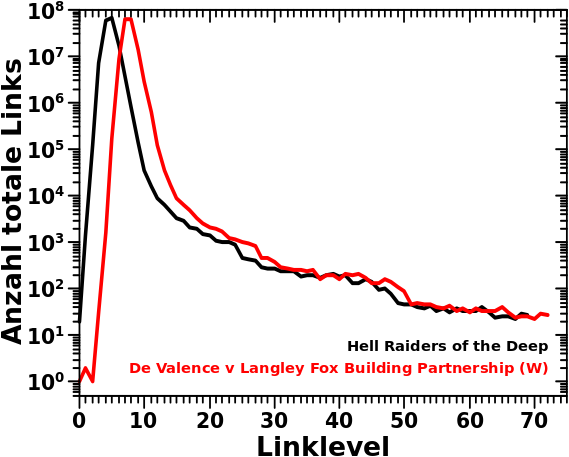
Die Daten fuer die schwarze Linie habe ich ganz zufaellig (ehrlich!) aus den fast 6 Millionen Datensaetzen herausgegriffen. Hier ist der Link zur entsprechenden Seite — Hell Raiders of the Deep. Das Maximum liegt bei LL5.
Die Daten fuer die rote Kurve habe ich mitnichten zufaellig herausgesucht. Dem ging eine umfassende Analyse aller individuellen Verteilungen voraus. Der Groszteil der Analyse war natuerlich automatisiert und ging schnell. Aber ein paar Stunden habe ich mit einer detaillierten manuellen Analyse verbracht. Das Maximum der roten Kurve liegt bei LL8 (ja, da ist ein kleiner Unterschied zu LL7) und hier ist der Link zur entsprechenden Seite (und der richtigen Version!) — De Valence v Langley Fox Building Partnership (W). Ich komme weiter unten nochmal darauf zurueck.
Zwei Dinge fallen an den beiden Kurven auf.
Zum Ersten ist die Amplitude des Maximums der beiden Kurven (beinahe) die Selbe. Das sollte auch so sein, denn selbst wenn die Spaetzuenderseite mit einer „Verspaetung“ von drei Linkleveln startet, so sind dort doch die selben Prozesse am Wirken wie bei den Hell Raiders of the Deep. Diese Prozesse wurden in den vorhergehenden Artikel in dieser Reihe dargelegt.
Zum Zweiten scheint beim genauen Hinschauen das letzte Stueckchen vom Schwanz vøllig uebereinzustimmen (von der Verschiebung abgesehen). Als ich mir die Zahlen konkret anschaute war dem tatsaechlich so! Die letzten zwanzig Linklevel haben bei beiden Seiten ganz genau die gleichen Werte.
Ich erwaehnte bereits mehrfach, dass da irgend etwas komisch ist zum Ende hin. Auch diesmal muss ich die Diskussion dieses Mysteriums in die Zukunft schieben.
Das waren aber nur zwei individuelle Verteilungen. Von Interesse sind nun die Mechanismen die zu einer solchen Verschiebung fuehren. Dafuer muss man sich aber die Verteilung der Maxima der individuellen Verteilungen der totalen Links aller Seiten anschauen. … Haeh was? … Hoffentlich etwas verstaendlicher: ich evaluierte fuer alle Seiten, bei welchem Linklevel das Maximum der Verteilung der totalen Links liegt. Hier ist das Resultat:
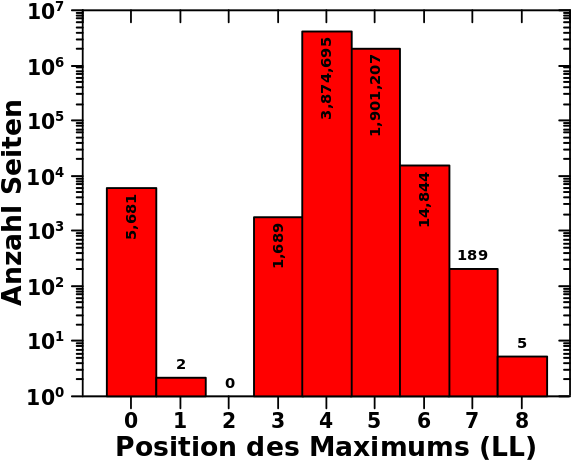
Wie zu erwarten war, lag das Maximum der Maximaverteilung bei LL4 (dicht gefolgt vom Balken bei LL5). Das musste so sein, denn andernfalls haette sich die Gesamtverteilung nicht so ergeben wie sie sich ergeben hat. Das Maximum von ein paar wenigen Seiten liegt entweder links oder rechts direkt daneben. Auch das war zu erwarten. Die 5 Seiten bei LL8 sind das Thema dieses Beitrags und ich bespreche das im Detail weiter unten. Ich denke, dass die Ergebnisse dieser Besprechung im Wesentlichen auch auf die 189 Seiten bei LL7 uebertragen werden kønnen.
Unerwartet sind nun die ueber 5-tausend Seiten die ihr Maximum bei LL0 haben? Was geht hier vor?
In kurz ist dieses Signal hauptsaechlich ein Artefakt von Seiten die keine Links haben (aber die von mindestens einer anderen Seite zitiert werden muessen, denn ansonsten haette ich die rausgeschmissen). Diese fuenftausendsechshunderteinundachtzig Seiten fallen im Wesentlichen unter zwei Kategorien. Die allermeisten sind so Seiten wie Controlled tenancy, Pedanochiton, Zodarion alentejanum oder Khudyakov Mikhail. Die haben tatsaechlich keine Links! (Kleiner Einschub: die letzte Seite wird umgeleitet (und da sind aber trotzdem keine Links) und das bestaetigt, dass Umleitungen tatsaechlich auch bei der Bearbeitung der Rohdaten funktioniert haben.)
Desweiteren fallen darunter Seiten wie Emily Howard die zwar Links haben, aber keine Links zu anderen Wikipediaseiten.
Von den ueber 5-tausend Seiten hatte ich 7 zufaellig herausgepickt und nur Bevonium faellt im Original nicht unter die obigen fuenf. Diese Seite hat naemlich einen Link, aber dieser wird umgeleitet und anders geschrieben. Leider fuehrt dies dazu, dass meine Bearbeitung der Rohdaten eine Verkettung dieser Umstaende nicht beruecksichtigt und, wie in den letzten beiden Artikel beschrieben, den Link herausschmeiszt. Bin ich froh, dass ich diese Fehlerquelle bereits vorher genauer untersuchte. Dadurch wurde ich hier nicht davon ueberrascht.
Auch wenn ich das mitnichten genau untersuchte, so scheint meine Stichprobe doch darauf hinzuweisen, dass dieser Fehler zwar vorkommt, aber nicht die Majoritaet des Signals ausmacht.
Die zweite Kategorie sind 111 Seiten wie bspw. Soldiers without Uniforms oder Rational economic exchange. Auf LL0 findet sich ein Link und der fuehrt (im ersten Fall) zu E.G. de Meyst bzw. (im zweiten Fall) zu Implied level of government service. Auf LL1 findet sich dann wieder nur ein Link, aber dieser zitiert die Ausgangsseite.
Die Situation ist also dadurch gekennzeichnet, dass es Links auf LL0 gibt, aber auf høheren Linkleveln gibt es genau gleich viele Links und alles endet schnell in einer Sackgasse (oder Schleife).
Auch in diesem Fall sehe ich wieder Seiten die nur in dieser Kategorie landen, weil meine Datenbehandlung aufgrund unguenstiger Umstaende Links løscht. Aber weil es insgesamt eh nur 111 Seiten in dieser Kategorie gibt, kuemmer ich mich da nicht weiter drum.
Kurzer Einschub: Die zwei Seiten mit dem Maximum bei LL1 sind Omegatetravirus und Betatetravirus. Das sind Viren, die Motten und Schmetterlinge befallen. Auf LL0 haben beide jeweils zwei Links. Der Erste ist viruses und wird wegen Umleitung und falscher Schreibung rausgeschmissen. Der Andere ist in beiden Faellen Alphatetraviridae. Alphatetraviridae hat nun drei Links von denen einer wieder „viruses“ ist (und wieder rausgeschmissen wird) und die anderen beiden sind „Betatetravirus“ und „Omegatetravirus“. Das ist also ein gegenseitig auf sich selber zeigen mit Zwischenschritt … tihihi.
Nun endlich zu den fuenf Artikeln mit einem Maximum bei Linklevel 8. Ich sage gleich, dass oben erwaehnte Fehlerquellen vermehrt auftreten. Aber ich fange mit der Seite an, bei der alles knorke ist (wenn man die richtigen Versionen nimmt): De Valence v Langley Fox Building Partnership (W). Diese hat einen Link zu Langley Fox Building Partnership v De Valence. Von dort fuehren zwei Links zu Chartaprops v Silberman und Kruger v Coetzee. Letzteres hat keine weiterfuehrenden Links und Ersteres hat nur einen Ausgang zu South African law of agency. Dies ist dann eine normale Seiten mit normal vielen Links und das setzt dann die Kaskade in Gang.
Zieht man auf jedem Linklevel bei den richtigen Versionen die oben erwaehnten Fehler in Betracht, so ist auch Prytanis (king of Sparta) ein „Spaetzuender“. Jeweils mit nur einem Link weiterfuehrend geht die Linkkette zu Polydectes, dann weiter zu Eunomus um zu Charilaus und den Ausgangspunkt der Kaskade zu gelangen. Wuerde allerdings Greek language nicht faelschlicherweise rausgeschmissen werden, dann waere es mitnichten ein Spaetzuender.
Duer Copy propagation gilt das Selbe, auch wenn es etwas schwerer nachzuvollziehen ist, wo die Fehler passieren. Auf LL0 ist ein „gueltiger“ Link zu LL1. Auf LL1 gibt es derer zwei, aber einer fuehrt zurueck und auf LL2 dann wieder nur einer. Die Kaskade beginnt auf LL3.
Bei den anderen beiden Seiten konnte ich nicht im Detail nachvollziehen wo die Fehler passieren. Aber es sieht arg nach dem selben Fehlermechanismus aus und deswegen diskutiere ich das hier nicht weiter.
Wie bereits erwaehnt, kommen die Mehrzahl der 189 Seiten mit dem Maximum auf LL7 vermutlich durch den gleichen Mechanismus zutande.
Zum Abschluss dieses Beitrags das Folgende. Dadurch, dass ich mir hier die Extreme genau anschaue ist zu erwarten, dass von mir gemachte Fehler deutlich sichtbar werden. Dies deswegen, weil diese Seiten von sich aus schon nur wenige Links haben und dann durch meine Fehler die Situation noch „verschaerft“ wird. Fuer die allergrøszte Mehrzahl der Wikipediaseiten hat das aber keinen gravierenden Einfluss. Denn wenn ich von bspw. 31 Links auf einer Seite einen aus Versehen wegschmeisze, dann macht das groszen Unterschied bzgl. der Position des Maximums.
So viele interessante Sachen. Ich bin schon gespannt auf’s naechste Mal.