.oO(Fast geschafft … das neue maechtige Werkzeug in aller Kuerze abzuhandeln).
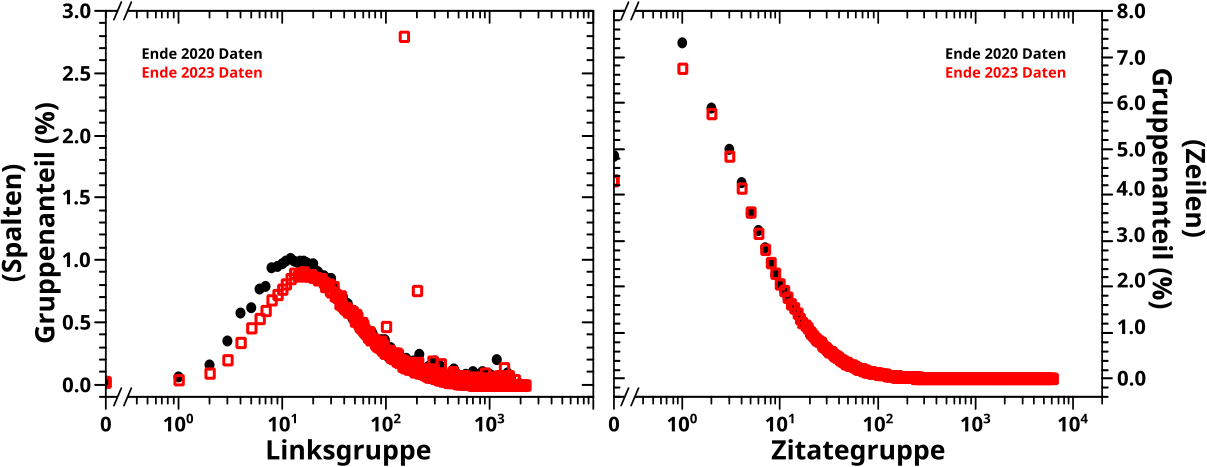
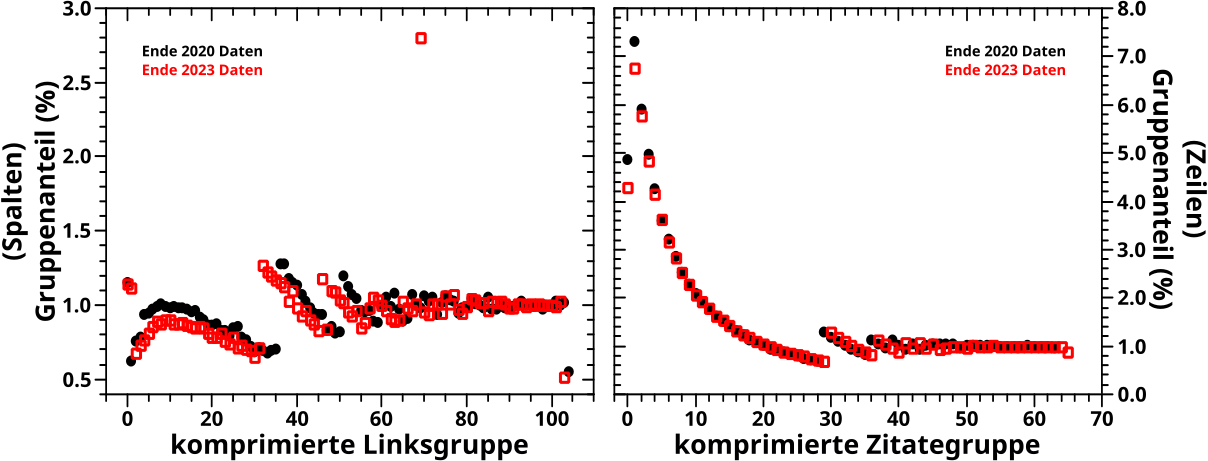
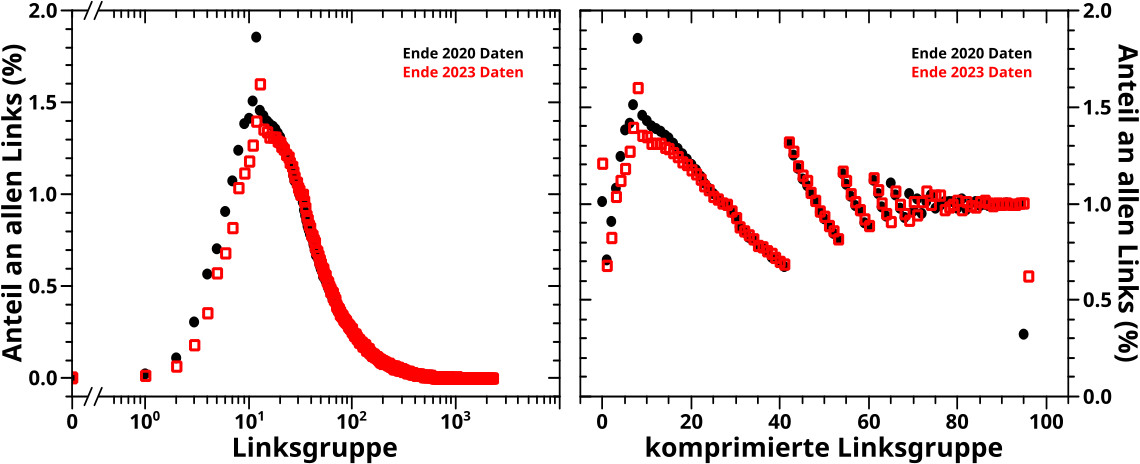
Nachdem die Daten bedeutungskomprimiert und wertekomprimiert wurden, bleibt nur noch die spalten- bzw. reihenweise Normalisierung der komprimierten Daten uebrig. Die „Rohdaten“ wurden dieser Transformation bereits unterworfen und man konnte einige (nicht im Detail diskutierte) Phaenomene sehen. Damals fuehrte die Normierung der komprimierten Daten zur Entdeckung und Erforschung des „Blobs“. Das war durchaus spannend, aber so weit werde ich es heute nicht treiben.
Das hier ist allerdings der „dickste“ Brocken, denn bei zwei Achsenbedeutungen (Anzahl der Zitate oder Links), multipliziert mit zwei (um den verschiedenen „Achsenbedeutungskombinationen“ Rechnung zu tragen), multipliziert mit zwei Arten der Komprimierung (bedeutungskomprimiert oder wertekomprimiert), multipliziert mit zwei Arten der Normierung (reihen- oder spaltenweise), mal zwei Datensaetzen (2020 und 2023) will ich heute 32 Falschfarbenbilder abhandeln.
Zum Glueck kann das alles schøn „verpackt“ werden, wodurch im Wesentlichen keine 32 Bilder einzeln diskutiert werden muessen. Der „Wechsel“ zwischen den verschiedenen Datensaetzen ist bereits bekannt. Die folgenden Bilder sind zunaechst nach der Art der Normierung getrennt (erst die spaltenweise, dann die reihenweise Normierung). Eine weitere Trennung erfolgt nach der Art der Komprimierung (jeweils erst die Bedeutungs-, dann die Wertekomprimierung). Die vier (wechselnden) Falschfarbenbilder die uebrig bleiben sind in ein Gesamtbild gruppiert. Darin repraesentiert die Abzsisse der oberen beiden Bilder die Zitategruppe und der unteren beiden die Linksgruppe, waehrend die Ordinate der beiden linken Bilder die Zitategruppe und der beiden rechten Bilder die Linksgruppe darstellt.
Dank der Normierung kuemmert auch die Falschfarbenskala nicht all zu sehr, denn die geht immer von null bis eins. Und die Komprimierung erfolgte wie in den entsprechenden Beitraegen besprochen; jede Spalte / Reihe sollte ungefaehr ein Prozent der jeweiligen „Werte“ enthalten (mit wichtigen, zu beachtenden Ausnahmen, die in den besagten Beitraegen besprochen wurde!).
Dennoch bleibt der Aufwand grosz (ihr, meine lieben Leserinnen und Leser solltet lieber nicht fragen, wieviel Arbeit ich in die Erstellung der Falschfarbenbilder gesteckt habe) und deswegen werde ich nicht alles im Detail besprechen; insb. nicht bereits bekannte und diskutierte Phaenomene.
Genug der Vorrede und hinein ins Vergnuegen (und ein Vergnuegen ist es, denn man sieht so viel … irgendwie schade, dass ich das nicht mehr im Detail erforschen werde).
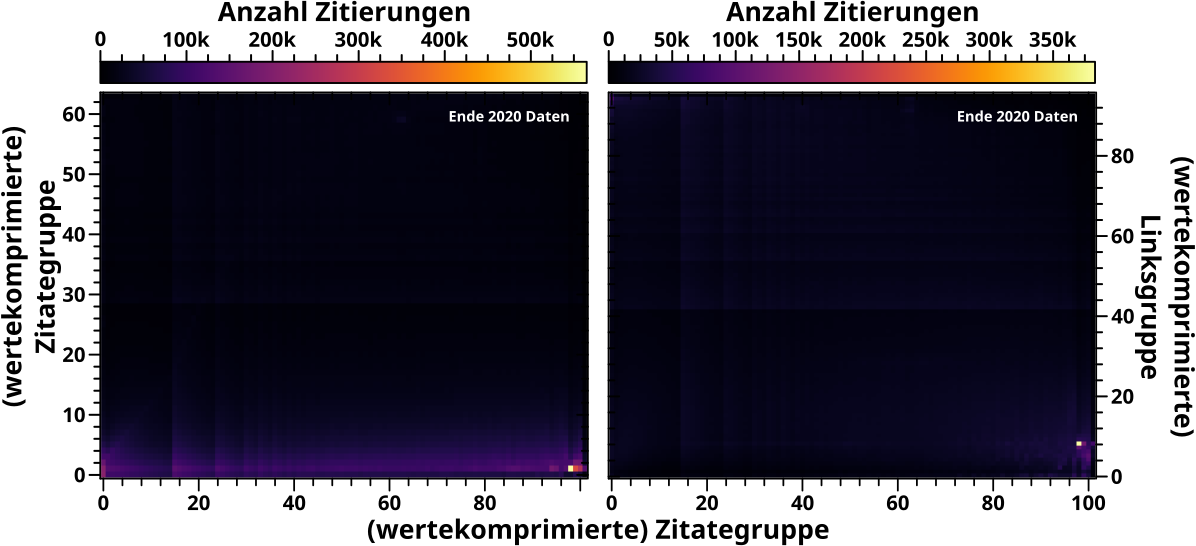
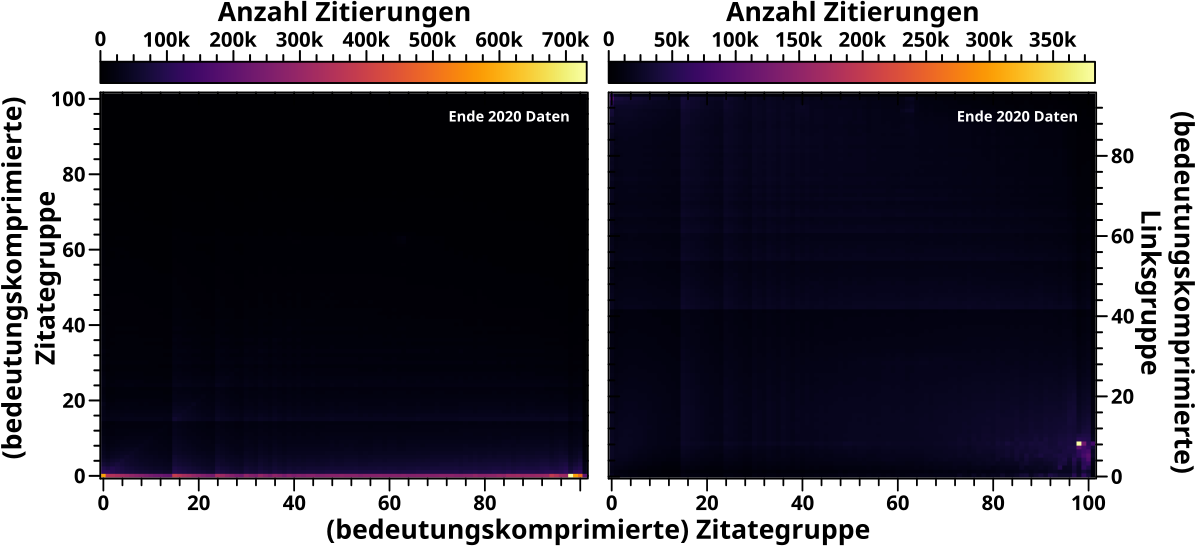
Hier sieht man die spaltenweise normierten, bedeutungskomprimierten Falschfarbenbilder:
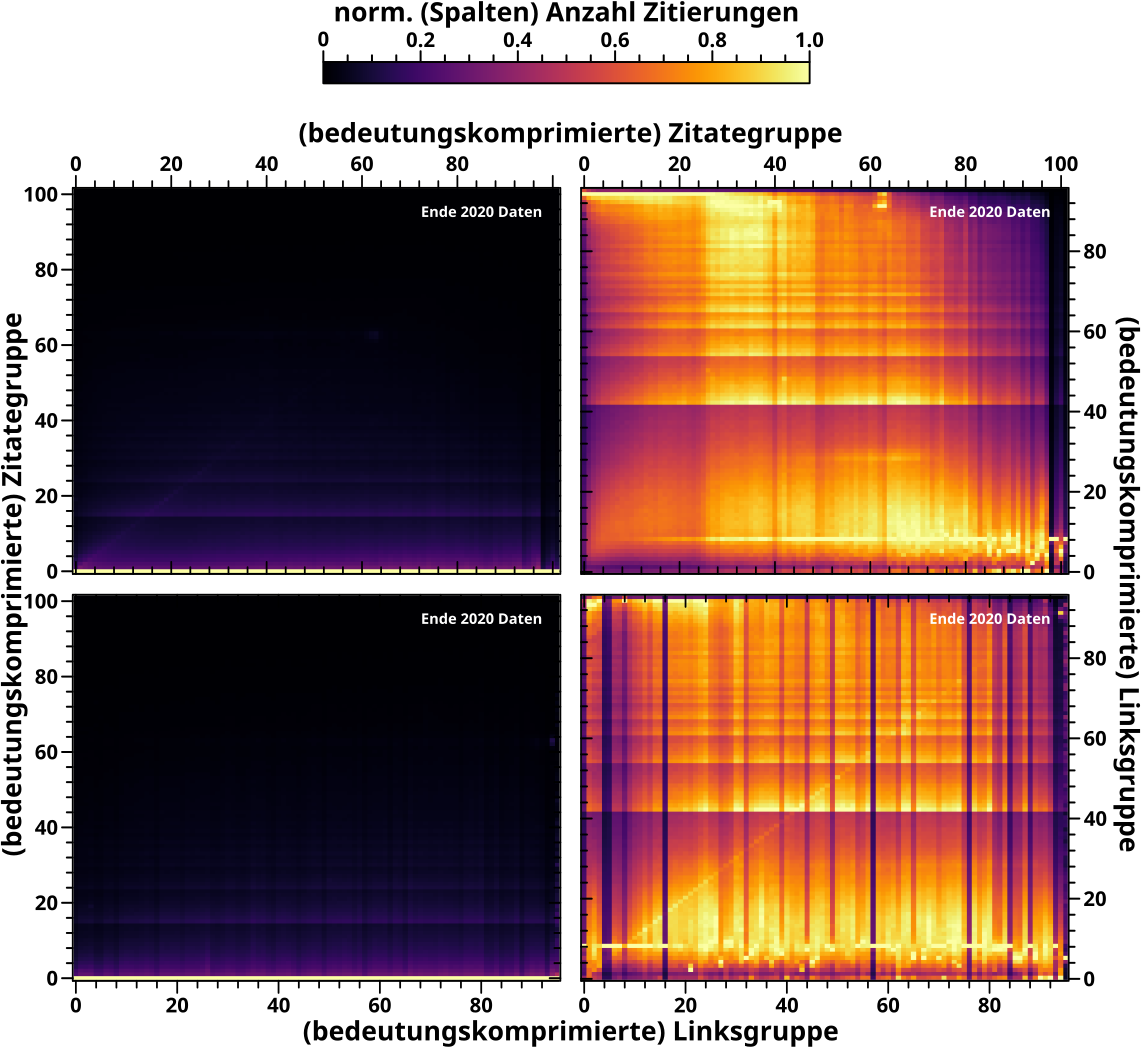
Fetzt wa!
Das linke obere Bild ist der zu reproduzierende Teil und davon abgesehen, dass das damalige Farbschema Informationen hervorhebt die so nicht hervorgehoben werden sollten, ist alles wie erwartet.
Bei den beiden linken Bildern ist die grøszte Intensitaet in nur einer Spalte am jeweils unteren Rand. Das entspricht dem bereits sehr lange bekanntem Resultat, dass im Wesentlichen alle Seiten von anderen Seiten zitiert werden die selber nur (sehr) wenige Zitate erhalten.
Die beiden rechten Bilder sind da schon spannender. Die horizontalen hellen Streifen sind Artefakte durch die „Stufen“ in der Komprimierung. Die vertikalen dunklen Streifen (insb. im rechten unteren Bild) kommen durch die eine, sehr intensive, unterbrochene Reihe bei ca. Zitategruppe 8 zustande; eben weil die so viel „Intensitaet“ auf sich vereint, ist dann nicht mehr genug „uebrig“ fuer die restlichen Zellen in der Spalte. Dieser Streifen ist bereits in vorherigen Beitraegen aufgefallen und da hatte ich den auch schon nicht weiter untersucht. Im rechten unteren Bild sieht man noch eine helle Diagonale. Das ist ein (ebenso bereits bekanntes) Artefakt der Rohdatenverarbeitung und kommt durch Seiten die sich selbst zitieren zustande.
Ansonsten sagt die ungefaehr gleiche Intensitaet ueberall aus, dass es egal ist wie viele Zitate oder Links eine Seite selber hat, sie wird um Durchschnitt gleich oft von Seiten mit wenigen, mittelvielen, oder ganz vielen Links zitiert. Das ist an sich schon durchaus interessant. Das Wørtchen „ungefaehr“ ist aber wichtig, denn wenn man genau hinschaut, scheint es im rechten oberen Bild einen breiten Streifen von links oben nach rechts unten zu geben (besser zu sehen in den 2023 Daten). Das wuerde bedeuten, dass Seiten mit wenigen Zitaten ein bisschen øfter von Seiten mit weniger Links zitiert werden und Seiten mit vielen Zitaten øfter von Seiten mit mehr Links. Das kønnte als ’ne Art „Dynamik“ im Linknetzwerk interpretiert werden und ist mglw. hoch spannend naeher zu untersuchen.
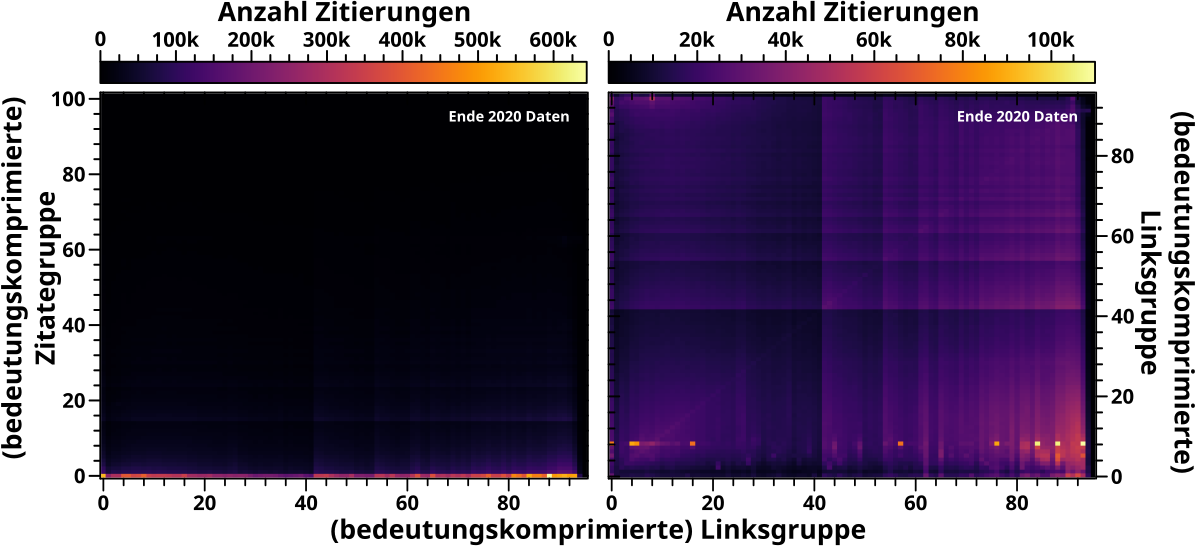
Bei den spaltenweise normierten, wertekomprimierten Falschfarbenbildern …
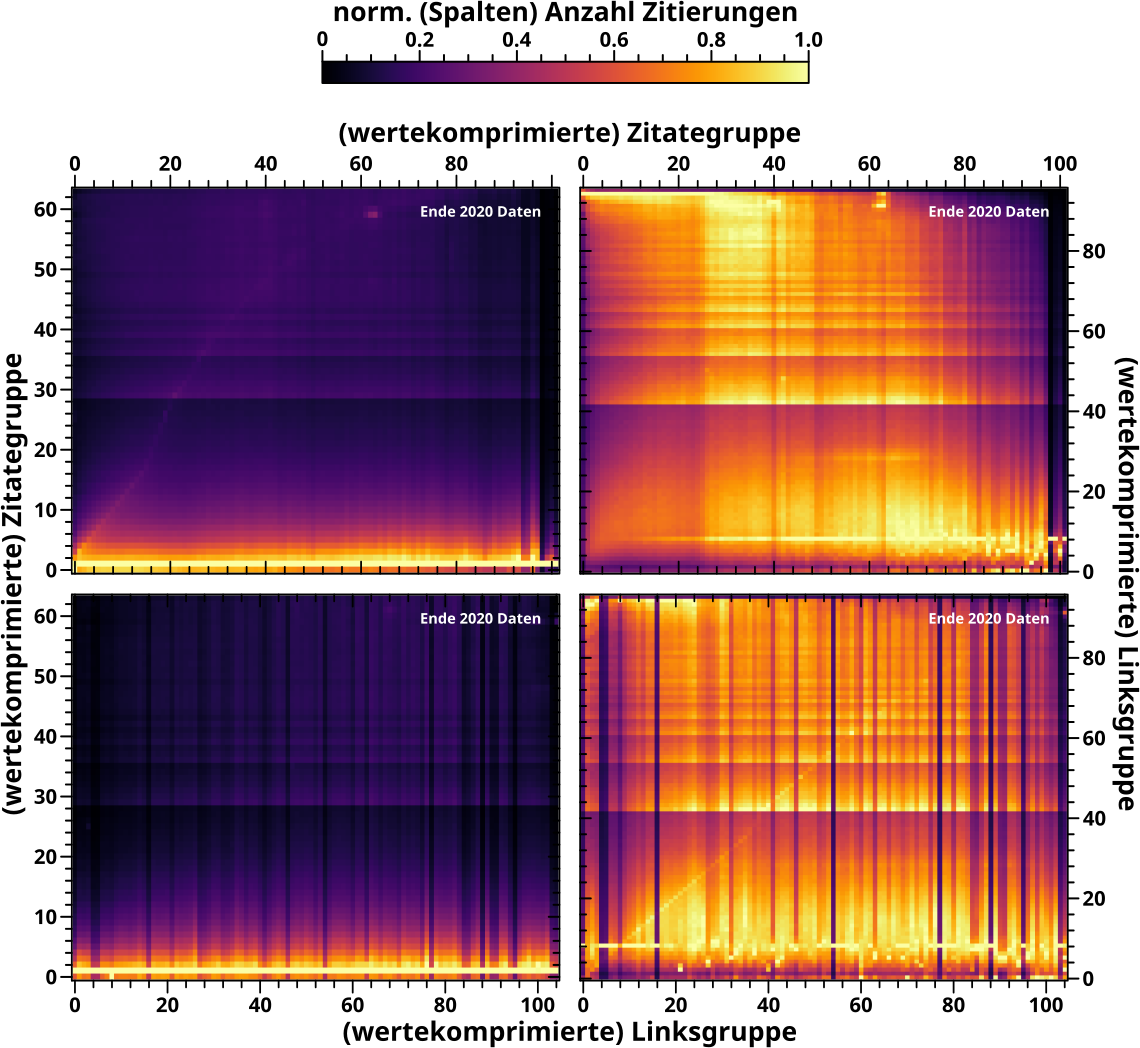
… ergibt sich im Wesentlichen das Gleiche. Bei den beiden linken Bildern ist der intensive Bereich nur um eine Reihe nach oben gerueckt und „verschmiert“, aber das ist von vorher bekannt.
Im linken oberen Bild sieht man bereits den „Blob“, wenn man weisz wonach man schauen muss.
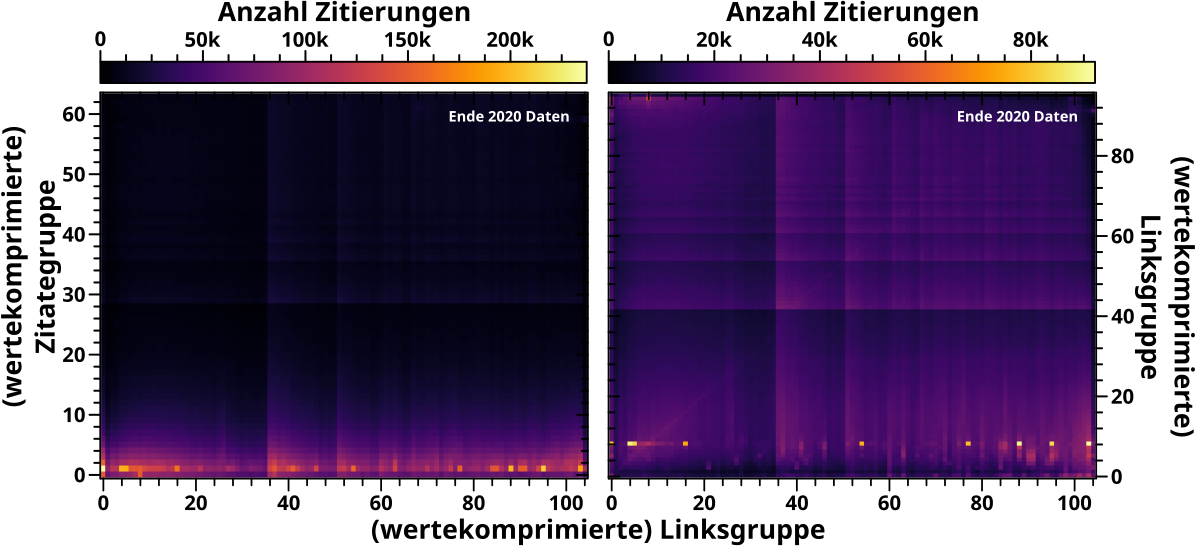
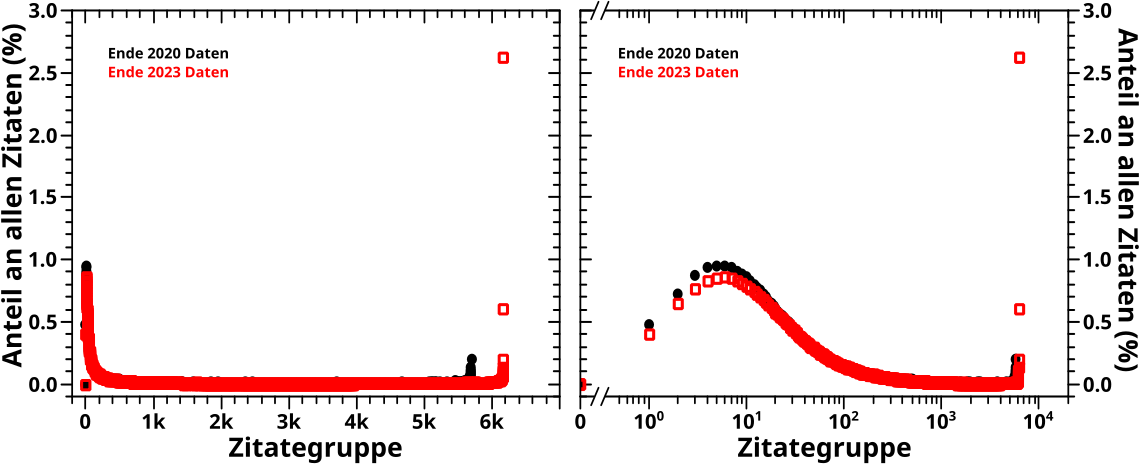
Damit kann ich zu den reihenweise normierten Falschfarbenbildern uebergehen. Zunaechst wieder die Bedeutungskomprimierten:
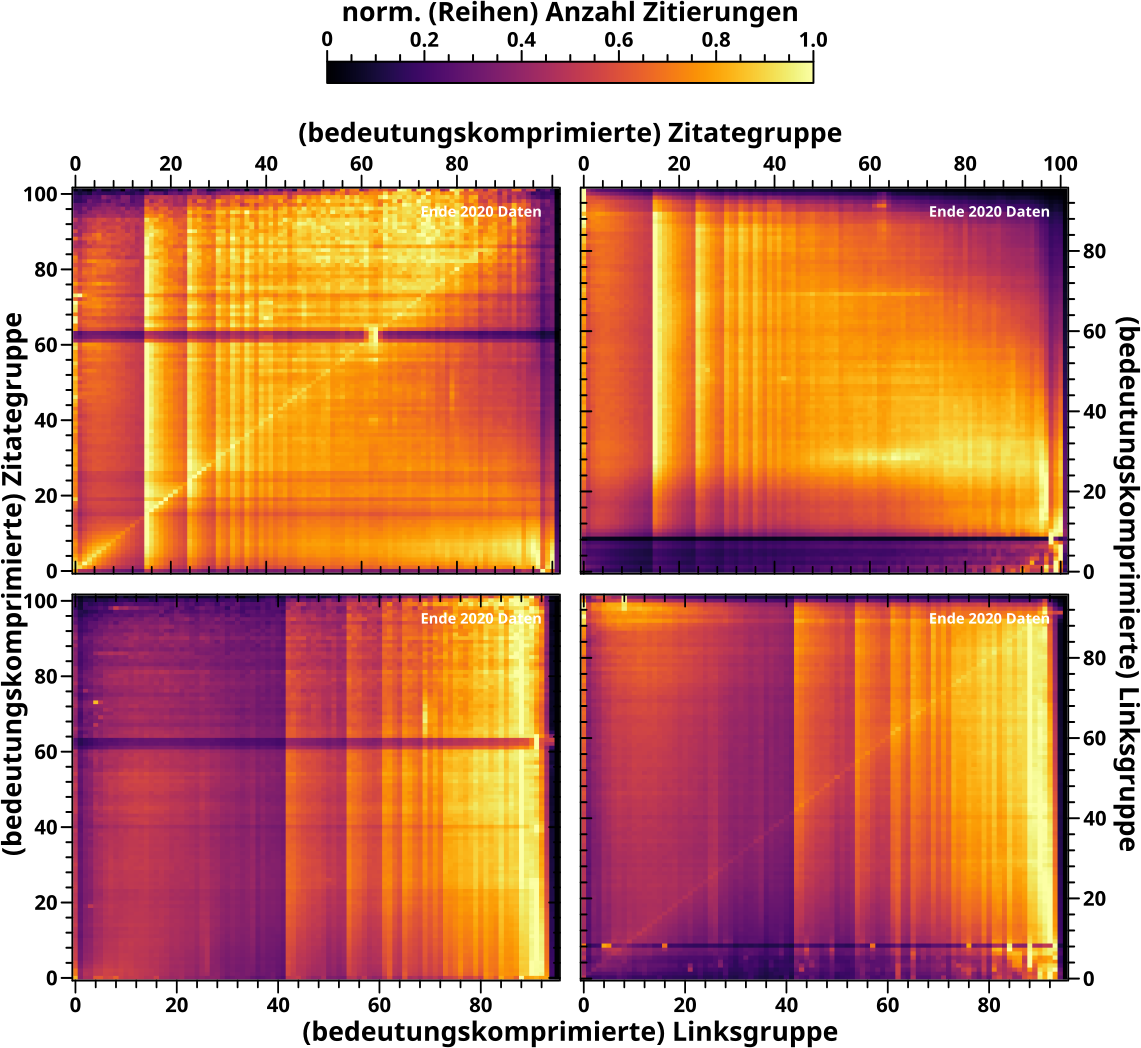
Das linke obere Bild ist wieder das was zu reproduzieren war und im Vergleich sieht man, warum die neue Farbpalette so viel besser ist. Wichtig: man sieht den „Blob“ ganz deutlich. .
Die beiden oberen Bilder werden im unteren (ca.) Drittel der 2023 Daten dunkler, was natuerlich wieder durch die Praeszenz der Wikipedia Hauptseite zu erklaeren ist. Die Hauptseite ist in den unteren Bildern der helle vertikale Strich und wenn man sich das genau anschaut, sieht man leicht, dass eben diese fuer die Intensitaetsveraenderungen auch hier verantwortlich ist.
Wenn man den Einfluss der Hauptseite „rausrechnet“ (und vom „Blob“ absieht), dann ist die Intensitaet bei diesen Bildern im Wesentlichen ueberall gleich. Bei der Interpretation dieses Ergebisses muss man sich daran erinnern, dass hier die REIHEN normiert sind. Man schaut also NICHT wie oben wo auf der Abzsisse sich die eine Seite von Interesse befindet um dann rauszufinden welche andere Seiten Erstere zitieren. Vielmehr schaut man zuerst wo auf der Ordinate die Seite von Interesse liegt und wen diese zitiert. Eine ungefaehr gleiche Intensitaet ueberall bedeutet dann also, dass es egal ist wieviele Zitate oder Links eine zitierende Seite hat, diese zitiert im Durchschnitt ungefaehr gleich viele Seiten mit wenigen Zitaten / Links, mittelvielen Zitaten / Links und vielen Zitaten / Links.
Es gibt natuerlich Ausnahmen; bspw. die etwas erhøhte „Aktivitaet in der „Region ueber dem Blob“ im linken oberen Bild. Diese Ausnahmen sind dann extra spannend und waeren zu untersuchen.
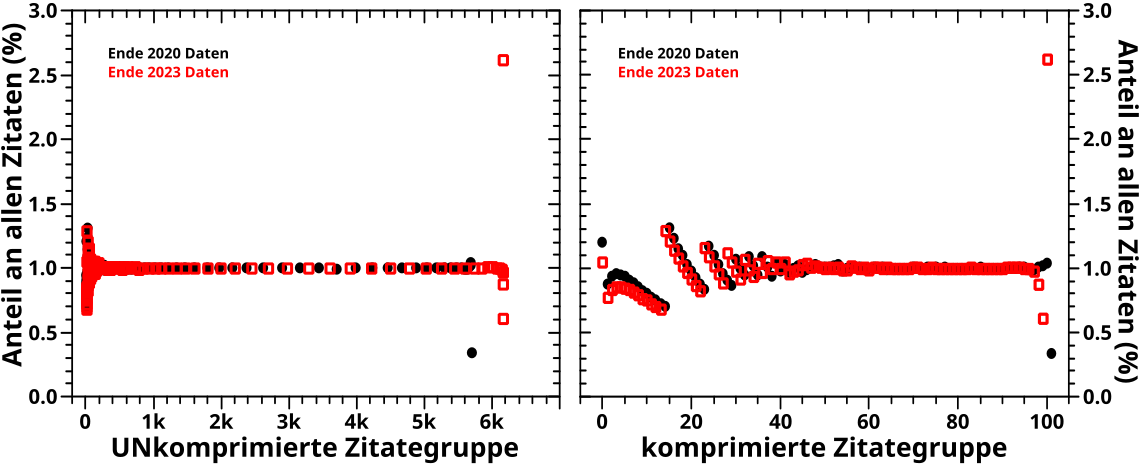
Nun gibt es zu den reihenweise normierten, wertekomprimierten Falschfarbenbildern …
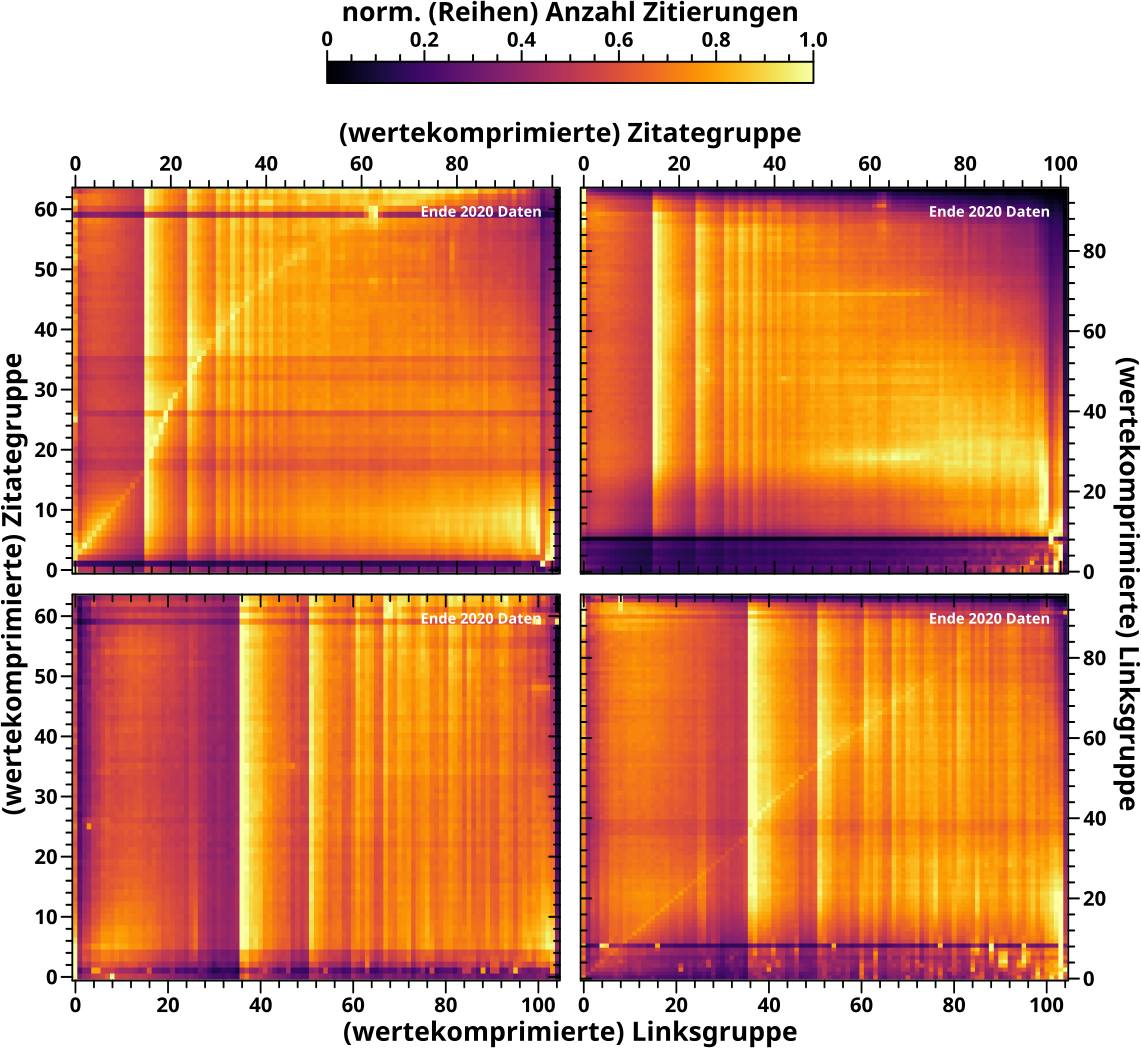
… fast nix mehr zu sagen, weil da alles sehr aehnlich aussieht.
Von besonderem Interesse ist nur der „diagonale“ Streifen. Bei den bedeutungskomprimierten, Linksgruppe-ueber-Linksgruppe, bzw. Zitategruppe-ueber-Zitategruppe Bildern ist der tatsaechlich diagonal und von ’nem kleinen Knick abgesehen gilt das auch fuer die wertekomprimierte, Linksgruppe-ueber-Linksgruppe Darstellung. Aber im linken oberen Bild sieht man, dass dieser Streifen recht krumm ist (und wenn man zu den reihenweise normierten Bildern zurueck geht, sieht man das auch dort, nur nicht so deutlich). Auch das kønnte wieder als eine Art „Dynamik“ interpretiert werden, aber vermutlich andersgeartet als die oben erwaehnte (vllt. aber auch nicht).
Hach ja … spannend, spannend, spannend … und all das bringt das neue Werkzeug ans Tageslicht. Cool wa!
Fuer mich reichts aber damit. Dafuer dass ich das urspruenglich gar nicht machen wollte, sind da ganz schøn viele Beitraege draus geworden. Bevor ich mich an diese Sache setzte schrieb ich:
[…] ich [hatte] da[mals] „nur“ bunte 2D-Falschfarbendarstellungen bei denen ich genau „reinzoomen“ musste um Details zu besprechen. Oder anders: bei denen sieht man bei so kleinen Veraenderungen ohnehin keinen Unterschied (und „reingezoomt“ hatte ich nur bei Anomalien die vermutlich immer noch da sind und wenn nicht mir auch nix ueber das Grosze und Ganze verraten). Solche „bunten Karten“ kann ich auch nicht zum besseren Vergleich uebereinander legen. Vermutlich werd ich da also nicht nochmal drueber schauen mit den neuen Daten […].
Tja, da hab ich mich gehørig getaeuscht und ich bin froh, dass doch gemacht zu haben. Und beim naechsten Mal dann … uff … weisz ich gerade noch gar nicht … vermutlich muss ich erstmal wieder was in meinem Code aufraeumen und neu schreiben, bevor ich die naechste Sache bzgl. der Reproduzierbarkeit checken kann.