Jippie! Noch eine Verteilung! … Ich weisz, ich weisz … das sieht immer gleich aus … so ist das nun mal mit dem Wissensgewinn. Man braucht ganz viel Kram der (fuer die meisten Menschen) immer gleich aussieht und (fuer die meisten Menschen) schnell langweilig wird. Erst wenn alles beisammen ist, kann man daraus die coolen Schlussfolgerungen ziehen die dann zum Erkenntnisgewinn fuehren … ich sage da: cool wa! … aber ich raeume ein, dass ich da vermutlich eher zur Ausnahme gehøre.
Das war bei der Entdeckung der Theorie der Elektrizitaet damals vor vielen hundert Jahren nicht anders. Watt und Volta und Ampere haben bestimmt total viele Katzen (und andere Materialien) gerubbelt (aber nicht Galvani! Der hat Frøsche aufgeschlitzt) und alles minutiøs aufgeschrieben, um dann erst nach Jahrzehnten des Datensammelns ihre bahnbrechenden und fundamentalen Beobachtungen (und Theorien) zu verøffentlichen.
Wissenschaft wird immer als so glamourøs dargestellt — sexy Wissenschaftler in ihren coolen Laboratorien mit den abgefahrenen Geraeten und Instrumenten und dem krassen Code, die dann in supersozialen Zusammenkuenften angeregt ueber die neuesten Ergebnisse diskutieren. Das ist ja alles komplett richtig, dabei darf aber nicht vergessen werden, dass da auch jede Menge „langweiliges“ Zeug dazu gehørt, ja, dass das sogar die Hauptsache ist, womit sich Wissenschaft beschaeftigt.
Und das war auch ein Grund fuer mich, dieses Wikipediaprojekt (anders als sonst) so genau zu dokumentieren.
Aber ich schwoff ab … und mir faellt gerade auf, dass ich das was ich da eben schrieb tatsaechlich meine (und vermutlich schon immer so empfand) … tihihihihi
Beim letzten Mal praesentierte ich die 50 am meisten zitierten Wikipediaseiten und erkannte, dass diese sich leicht in ein paar wenige Kategorien einsortieren lassen. Das Endresultat war das Folgende.
Diese 50 Wikipediaseiten werden 4,894,941 mal zitiert. Damit vereinen 0.00086 % aller Wikipediaseiten 2.95 % aller Zitierugen auf sich.
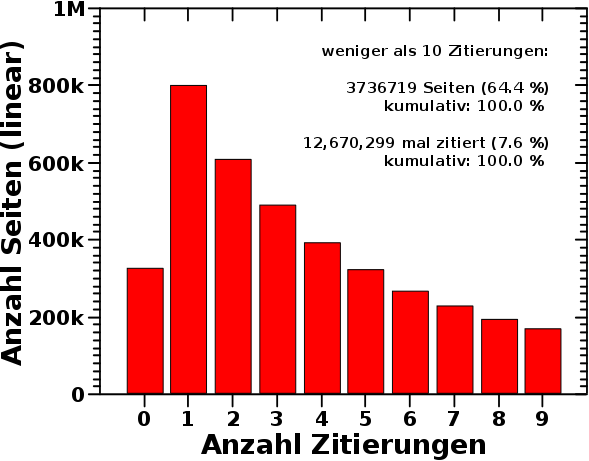
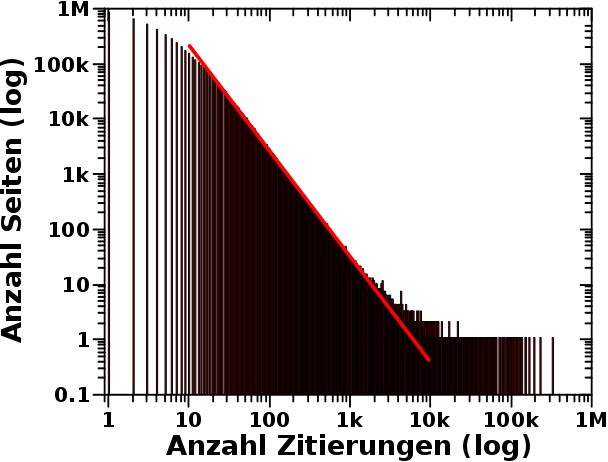
Die natuerliche Frage ist dann, wie das bei den restlichen 5,798,262 Seiten aussieht. Zur Erinnerung: insgesamt betrachte ich 5,798,312 Wikipediaseiten auf denen insgesamt 165,913,569 (jeweils) andere Wikipediaseiten zitiert werden. Und so sieht die Verteilung der Zitierungen aus:
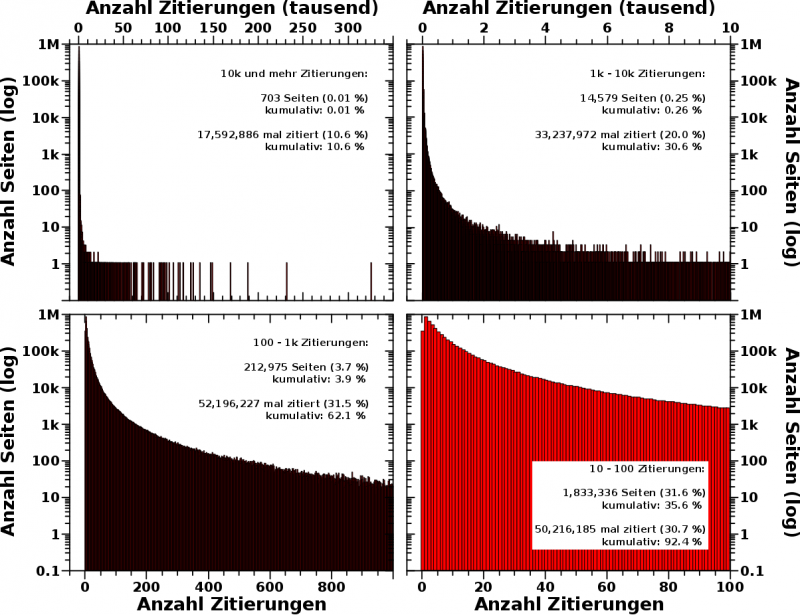
Das ist viel auf einmal, deswegen der Reihe nach. Zunaechst ein paar grundsaetzliche Erklaerungen (die zwar offensichtlich sind, wo es aber auch nicht schadet, die mal gesagt zu haben).
1.: In jedem Diagramm trage ich die Anzahl der Seiten auf, die so oft wie auf der Abzysse angegeben zitiert wurden.
2.: Die Abzysse jedes Diagramms faengt bei null Zitierungen an, ich konzentriere mich aber auf unterschiedliche Gruppen. D.h. dass die x-Achse nach einem bestimmten Wert abgeschnitten und fuer jedes Diagramm unterschiedlich ist. Die Gruppierng ist jeweils angegeben.
3.: Die Ordinate ist fuer alle Diagramme gleich … und logarithmisch. Letzteres bedeutet, dass 10 mal so viele Seiten mit der entsprechenden Anzahl Zitierungen gezaehlt wurden, wenn ein Balken doppelt so hoch ist wie die einzelnen Striche im ersten Diagramm. Entsprechend bei 3-facher Høhe usw.
4.: Das sind rote Balken mit schwarzen Raendern. Weil die Balken so dicht stehen, sieht man in den ersten drei Diagrammen nur die schwarzen Raender … das macht aber nix.
5.: Die angegebenen Zahlen per Diagramm sind wieviele Seiten insgesamt in der jeweiligen Gruppe gezaehlt wurden und wie viele Zitierungen diese auf sich vereinen. Die kumulativen Werte sind entsprechend aufaddiert fuer alle Gruppen bis zu der jeweils im Diagramm dargestellten (bei hohen Zitierungen anfangend).
6.: Semantisch sind die einzelnen Gruppen eigentlich nicht so strikt getrennt. Da gibt es sicherlich jede Menge Ueberlapp. Aber auf Grund mathematischer Notwendigkeiten musste ich Grenzen setzen fuer jede Gruppe und da dachte ich mir, dass das erstmal nicht unvernuenftig ist im Wesentlichen immer eine Grøszenordnung per Gruppe abzudecken.
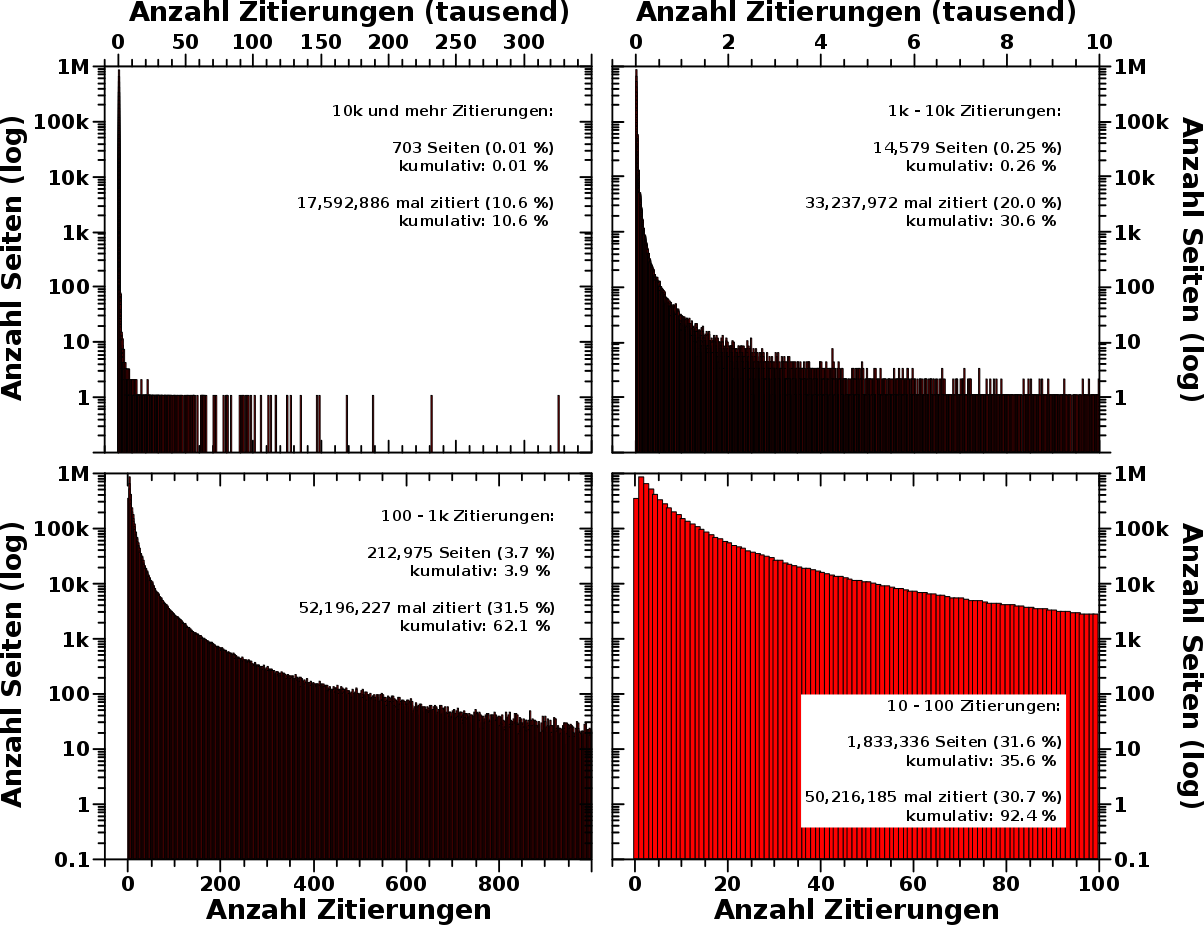
Das erste Diagramm visualisiert die beim letzten Mal diskutierten Extreme — Seiten die zwischen 10,000 und 325,128 mal zitiert wurden. An den Zahlen sieht man ganz deutlich, dass man, wenn man zufaellig einem Link auf Wikipedia folgt, in ca. 10 Prozent aller Faelle auf einer von nur 703 Seiten landet. Das ist eine ziemlich krasse Dominanz dieser wenigen vielzitierten Seiten! Und der lange duenne „Strich“ am linken Ende … nun ja, …
… bei dem sieht man im zweiten Diagramm, Seiten die zwischen 1,000 und 10,000 mal zitiert wurden, dass es sich dabei nicht im einen „Strich“ handelt. Vielmehr versammeln sich dort mehr und mehr Seiten die die gleiche Anzahl von (wenigen) Zitierungen haben. Von rechts kommend macht sich das zunaechst aber gar nicht bemerkbar.
In dieser Gruppe geschieht auch noch nicht so viel; nur eine Seite mit 8056 Zitierungen und nur vier Seiten mit 4880 Zitierungen. Aber ab 2000 und weniger Zitierungen zaehlt die Verteilung dann schon haeufiger 10 oder mehr Seiten und um ca. 1000 Zitierungen geht der Zaehler in die Zwanziger. Das ist das Truegerische an einer logarithmischen Darstellungen da sieht das mehr aus.
Zaehlt man diese beiden ersten Gruppen zusammen, dann hat man ca. 15-tausend Wikipediaseiten. Die Chance auf einer von diesen zu landen betraegt zusammengenommen fast ein Drittel! Ach du meine Guete! Bei beinahe jedem dritten Klick lande ich auf einer von nur 0.26 % aller Wikipediaseiten. Und drei (oder dreizehn) Wikipediatabs sind bei mir ganz schnell mal offen.
In der naechsten Gruppe, 100 bis 1,000 Zitierungen, befinden sich 3.67 % aller Wikipediaseiten und mit den vorherigen Gruppen zusammen ziehen diese nur ca. 4 % aller Seiten ueber 60 % aller Zitierungen auf sich.
Bei der Anzahl von Seiten pro Haeufigkeit-der-Zitierung erreichen wir ab ca. 500 (und weniger) Zitierungen die Hunderter um bei ca. 150 Zitierungen dann auch schon tausende Seiten zu zaehlen.
Bei der letzten Gruppe, 10 bis 100 Zitierungen, ist aus dem duennen Strich des ersten Diagramms eine hohe „Wand“ roter Balken geworden. Wir zaehlen am rechten Rand ca. 2500 Seiten und erreichen die Zehntausender bei 49 Zitierungen und die Hunderttausender bei 12 Zitierungen. Kumulativ vereinen diese ca. 35 % aller Seiten ueber 90 % aller Zitierungen … tja … das ist auf der Wikipedia wie im richtigen Leben: wir wissen wenig, aber darueber reden wir die ganze Zeit.
Und das ist dann auch des Pudels Kern der sogenannten Relevanzdiskussion der dtsch. Wikipedia. Diejenigen die Relevanzkriterien befuerworten haben die Fakten auf ihrer Seite, ganz konkret im Sinne des Wortes „Relevanz“. Ich persønlich finde es aber viel zu toll, dass ich Bacon, Ohio auf der Wikipedia finden kann. Dies auch dann, wenn ich die aller-aller-aller-allermeisten dieser Seiten niemals sehen werde.