Die damals „kollektive Wanderung“ genannten Beitraege waren mein eher weniger erfolgreicher Versuch die Idee der Grøszenordnungskomprimierung der massiven Daten „unter’s Volk“ zu bringen. In den letzten drei Beitraegen habe ich diese Methode stark verbessert, ausfuehrlich besprochen und einem nuetzlichen Zweck zugefuehrt.
Derartige Heatmaps sind aber so verschieden, dass man zwar im Prinzip das Gleiche hat wie bei den verlinkten Beitraegen, aber es ist irgendwie auch doch ganz anders.
Wieauchimmer, weil ich das so gut vorbereitet habe, muss ich heute gar nicht viel Aufhebens darum machen, was hier zu sehen ist:
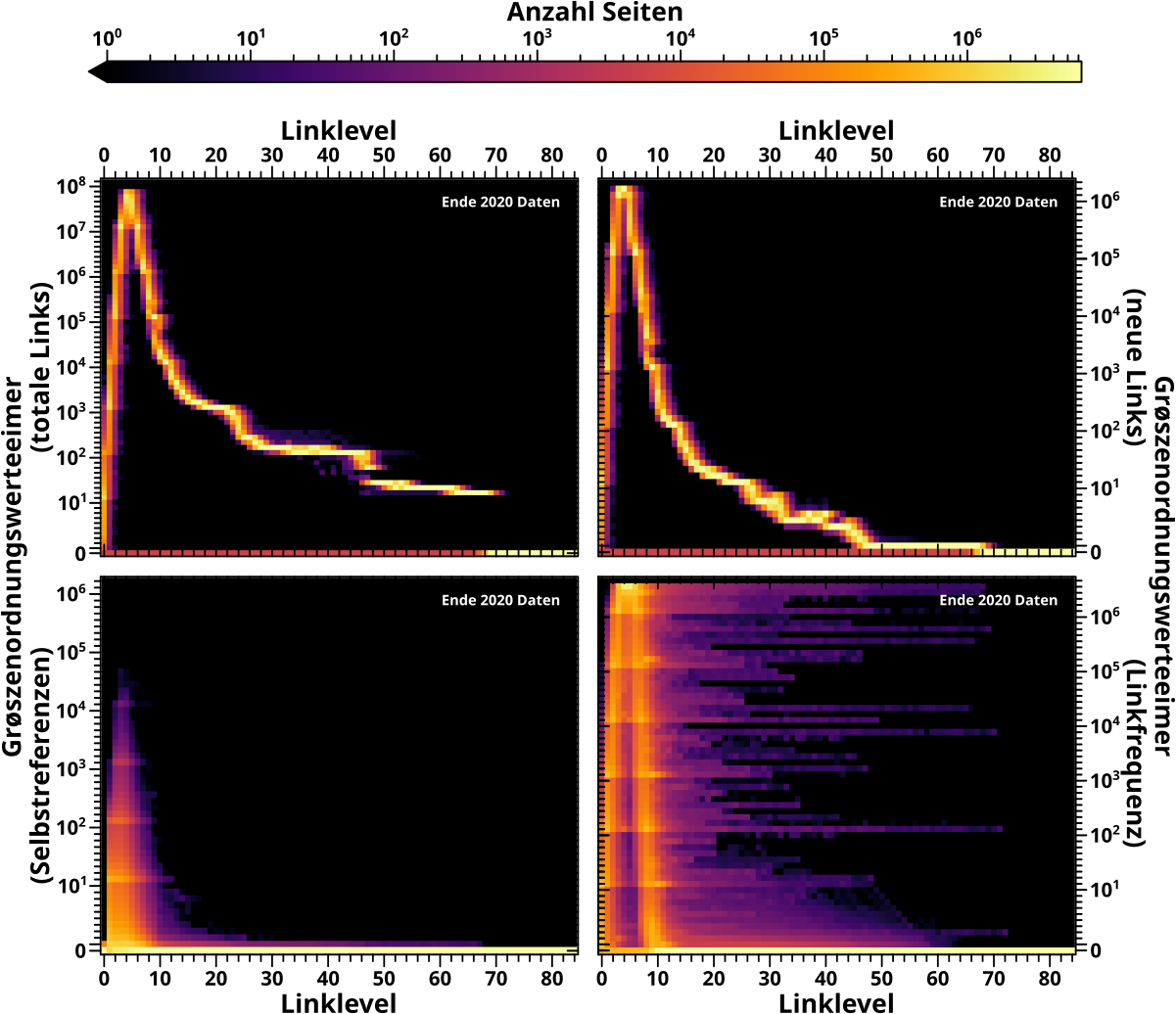
Und tatsaechlich, alles was man sieht wurde bereits an verschiedenen Stellen besprochen. Zu erwaehnen sind nur zwei Dinge.
Erstens: dass sich die Verteilungen der Selbstreferenzen nach einem maechtigen Gesetz verhalten, schlaegt sich natuerlich in den Heatmaps nieder. Dies ist uebrigens einer der speziellen Faelle, in denen man die „Stufen“ durch die Komprimierung korrigieren kønnte, weil sich die Daten „gutartig“ verhalten.
Zweitens: die andere „Art“ von „Stufen“ (besprochen beim letzten Mal) ist beim Uebergang von den Hundertern zu den Zehner in den 2023-Daten keine richtige „Stufe“ mehr sondern scheint ein mehr oder minder linearer „Abstieg“ des Signals zu sein. Andererseits ist dieser Bereich sehr breit und was ich hier sehe scheint eher einer „Spaltung“ (auch beim letzten Mal besprochen) der 2023-Verteilungen in diesem Bereich zuzuschreiben zu sein.
Man sollte auch nie vergessen wo man herkommt und wie die bunten Bilder da oben dem linearen menschlichen Verstand eigentlich gegenueberstehen:
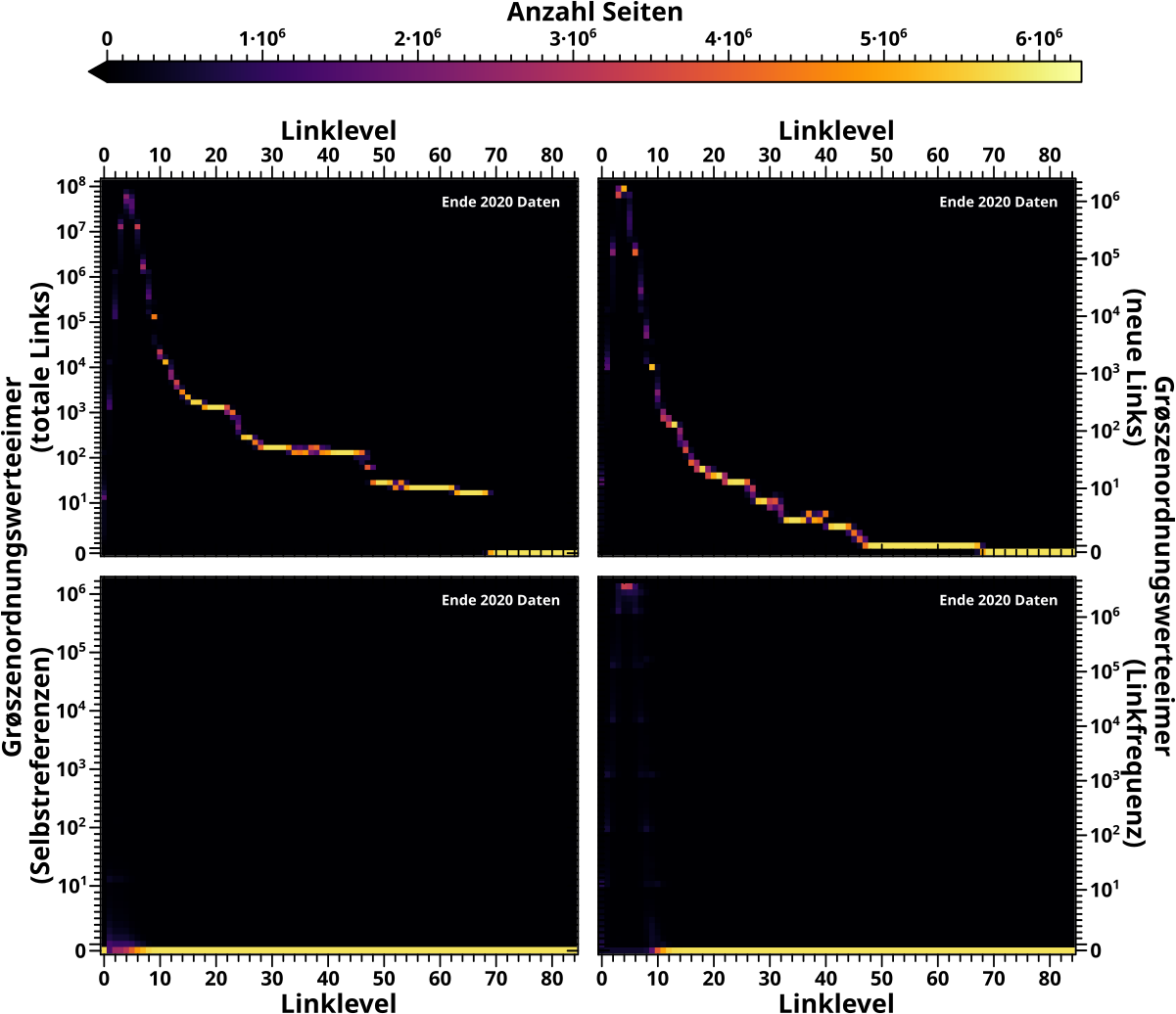
Der Vergleich logarithmischer und linearer Daten ist durchaus nuetzlich, letztlich steckt hier aber nix drin, was ich nicht schon gesagt haette … dieser Teil des Kevin Bacon Projekts heiszt ja nicht umsonst „Reproduzierbarkeit“.
Juti … damit ist diese Sache auch fertig. Eigentlich wollte ich die gar nicht reproduzieren, weil das damals so unzufriedenstellend war. Aber dann bin ich bei einem Spaziergang endlich drauf gekommen, wie man richtig an die Grøszenordnungshistogramme heranzugehen hat und dass ich die nicht fuer den urpsruenglichen Zweck (in normalen Diagrammen) verwenden sollte. Das hat mich natuerlich voll motiviert den dazugehørigen Code (nochmal) zu schreiben und die verbesserte Reproduktion war dann ein Klacks.
Alles in allem bleibt nur zu sagen: die Reproduktion der „kollektiven Wanderung“ geschah vøllig anders, ist aber gelungen.
Leave a Reply