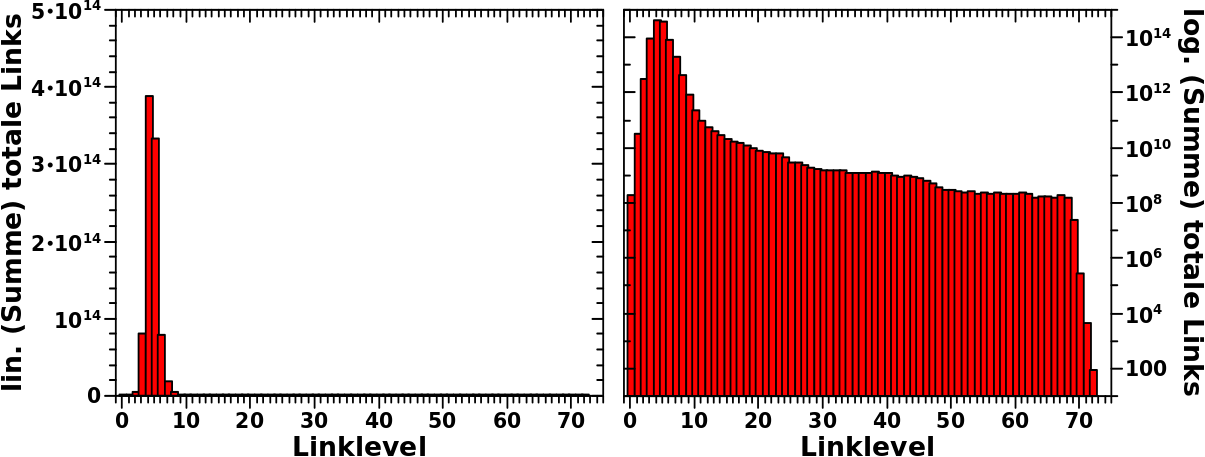
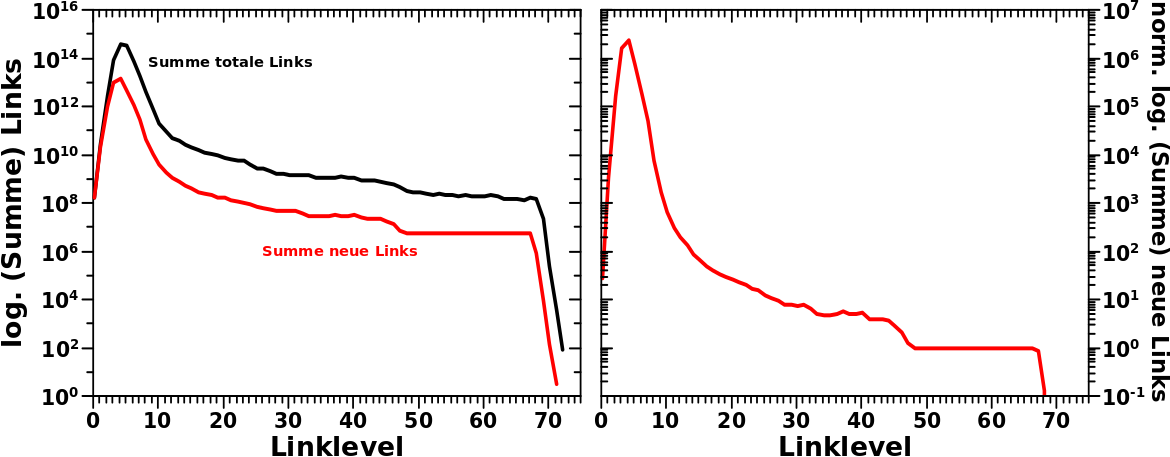
Bei den Betrachtungen zu den totalen Links pro Linklevel musste ich zunaechst eine Erklaerung finden, warum der Anstieg der totalen Links am Anfang so sehr viel staerker ist als erwartet.
Dies fuehrte letztlich dazu, dass ich den Zusammenhang zwischen der Anzahl der Zitierungen die eine Seite auf sich vereint und der Anzahl der totalen Links der selben Seite untersuchte. Die Quintessenz dieser Untersuchungen drueckt sich so klar in diesem schøne Ergebniss aus.
Das mache ich selbstverstaendlich nicht nochmal, denn das waere nicht sinnvoll. Der Grund ist, dass wenn ich nur eine Seite und nicht deren Linknetzwerk betrachte, alle Links auf dieser Seite neu sind. Dies ist natuerlich unabhaengig von der Anzahl der Zitierungen dieser Seite.
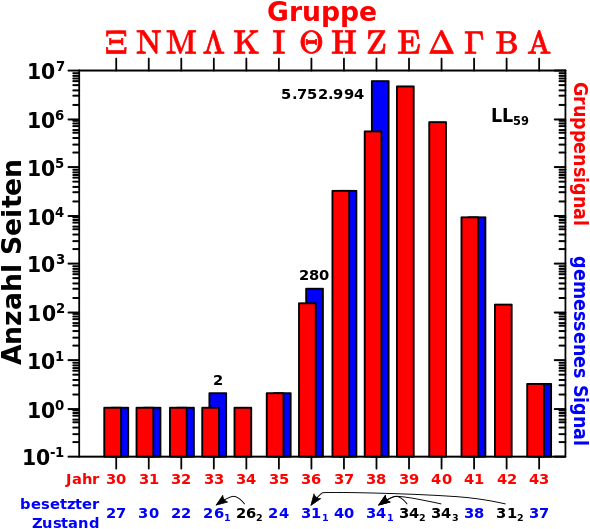
Danach schaute ich mir die „Spaetzuender“ an. Dies waren Seiten, bei denen das Maximum der indivduellen Verteilung der totalen Links pro Linklevel deutlich vom Maximum der Summe der Verteilung abweicht.
So richtig _deutliche_ Abweichungen fand ich nicht, und die Seiten bei denen die Position des besagten Maximums am meisten abweicht, waren entweder „Rohrkrepierer“, „komische Seiten“ oder eine unguenstige Verkettung von Artefakten, welche aus der Datenaufbereitung stammten. Im verlinkten Artikel wurde dies alles genau beschrieben.
Im Gegensatz zu Ersterem, ist es durchaus sinnvoll, sich die Verteilung der Position(en) der Maxima der individuellen Verteilungen der _neuen_ Links pro Linklevel anzusehen. Hier ist das Ergebnis:
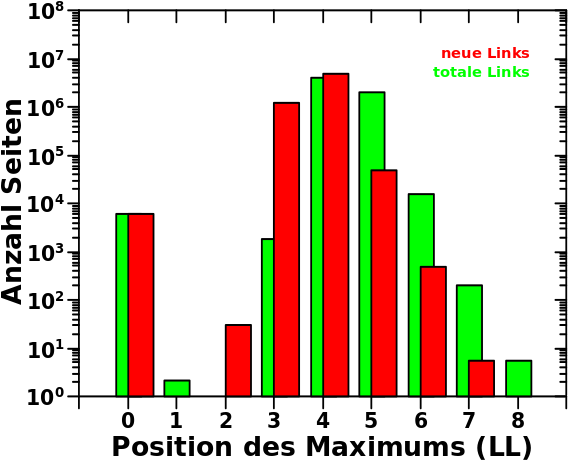
Zum Vergleich in gruen (nochmals) das Gleiche aber fuer die totalen Links … Wortspielkasse. Man erkennt, dass es keine groszen Unterschiede gibt.
Schon aus den Verteilungen der Summe der neuen bzw. totalen Links, konnte man vermuten, dass auch hier das Maximum um ein Linklevel nach „unten“ (bzw. nach links) verschoben sein wird.
So weit so gut. Verschiebt man nun deswegen die rote Verteilung gedanklich um eins nach rechts faellt aber auf, dass die Balken fuer die neuen Links rechts von LL4 alle grøszer sind als die der totalen Links. Das sieht man eigentlich (mal wieder) nur wegen der logarithmischen Ordinate. Aber man sieht es und dieser „Effekt“ ist systematisch und echt und bedarf deswegen einer Erklaerung. Diese folgt sofort.
Zunaechst einmal ist zu beachten, dass ein Balken nur aussagt, wieviele Seiten das Maximum der gegebenen individuellen Verteilung auf dieser Position haben — mehr nicht. Und auch wenn dies den lang und breit diskutierten Trends folgt, so unterliegen die individuellen Verteilungen fuer neue und totale Links natuerlich … ich sag jetzt mal Schwankungen.
Damit kann der „Effekt“ erklaert werden (aber man muss mit den genauen Werten arbeiten, denn wenn man rundet geht das Rechenstueck nicht auf). Im ersten „Maximumsbalken“ fuer neue Links auf LL3 „versammeln“ sich 1.103.028 Seiten. Im ersten „Maximumsbalken“ fuer die totalen Links auf LL4 hingegen 3.874.695 Seiten. Die Diskrepanz ist ziemlich grosz und bedarf einer eigenen Erklaerung. Aber es verwundert mich ueberhaupt nicht, denn hier ist definitiv noch das „Gebiet der vielzitierten Seiten mit vielen Links“ (siehe das schøne Ergebnis weiter oben). Deswegen bin ich hinreichend sicher, dass diese auch hier wieder die Erklaerung sind.
Wieauchimmer, besagte Diskrepanz muss woanders „aufgefangen“ werden, denn ich untersuchte ja ein und dieselben Seiten. Letzteres bedeutet, dass fuer beide Betrachtungen das Integral unter der „Kurve“ den selben Wert ergeben muss (die Anzahl aller Seiten). Auch wenn es gar nicht so aussieht, so findet sich das Meiste davon im zweiten „Maximumsbalken“ gleich danach (4.643.436 zu 1.901.207). Die ca. 30-tausend Seiten die noch fehlen sind dann ueber die anderen Balken (auch links vom Peak!) verteilt.
Ich habe das so genau diskutiert, weil ich zeigen wollte, dass man manchmal (oft?) sehr genau hinschauen muss und Rundungen nicht aufgehen. Haette ich die Zahlen auf hunderttausend (also die erste Stelle nach dem Komma) gerundet, dann sieht es naemlich ueberhaupt nicht so aus, als wenn das passt. Tut’s aber … zum Glueck.
Aber letztlich sind das alles Einzelheiten. Aber Einzelheiten gehøren zur „Data Science“ oft genug dazu :).
Zum Abschluss sei noch gesagt, dass ich (trotz des oben gesagten) nicht nochmal genau hinschaue, was denn das fuer Seiten sind, deren Maximum der Verteilung der neuen Links (z.B.) vier Linklevel ueber (oder unter) dem Maximum der allermeisten Seiten liegt. Ich bin mir sehr sehr sicher, dass ich im wesentlichen wieder nur auf die selben Effekte stosze wie bei den totalen Links und welche ich oben (nochmals) auffuehrte.