Via „Spaetzuender“ (auch als „grobe Abweichler“ bezeichnet) bin ich damals auf die Idee gekommen, mir mal anzuschauen auf welchen Linkleveln eigentlich die meisten Seiten das Maximum in der Kurve einer gegebenen Grøsze von Interesse haben.
Fuer die Anzahl der totalen Links ist das hier reproduziert:
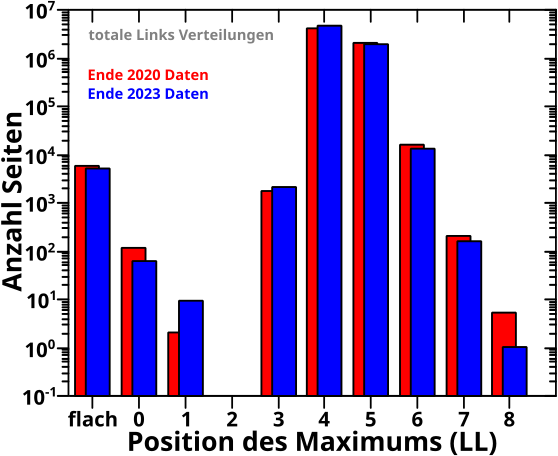
Wie erwartet gibt es zwischen den 2020-Daten und den 2023-Daten keine wesentlichen Unterschiede; insb. veraendern sich die Grøszenverhaeltnisse der Balken von Linklevel zu Linklevel nicht. Das ist also als reproduziert anzusehen.
Die blauen Balken bei LL1 und LL9 sehen zwar deutlich grøszer / kleiner aus, aber man beachte die logarithmische Ordinate. Da sind im ersten Fall also nicht mal 10 Seiten dazu bzw. im zweiten Fall deutlich weniger als 10 Seiten „abhanden“ gekommen … die viel kleinere Erhøhung bei LL4 entspricht fast einer Million Seiten. Logarithmische Achsen sind schon was Feines, nicht wahr! Die halten irrelevante Information von einem weg … man muss aber auch aufpassen, dass andere irrelevante Information nicht ueberinterpretiert wird.
Ansonsten gibt es nur eine Sache zu sagen und das ist ein wichtiger Unterschied im Vergleich zum damaligen Diagramm. Dort war naemlich der Balken bei LL0 zu hoch und es stellte sich dann heraus, dass es ueber 5-tausend Seiten OHNE Links gibt die da drin mitgezaehlt wurden … und nur ca. 100 Seiten mit einem echten Maximum der totalen Links auf LL0. Erstere haben eine flache totale-Links-per-Linklevel Verteilung; ohne Links als Ausgangspunkt kommt man nicht auf andere Seiten mit mehr Links … es startet also alles bei Null und bleibt auch dabei. Das wurde von meinem Algorithmus faelschlicherweise als „Maximum“ auf LL0 interpretiert.
Wieauchimmer, solche Seiten werden jetzt richtig erkannt und auf die „flach“-Position auf der Abzsisse gesondert dargestellt … und das gilt fuer alle Diagramme in diesem Beitrag.
Nun zu den neuen Links. Die Verteilung der Maximaspositionen der entsprechenden Kurven hatte ich damals der gleichgearteten Verteilung der totalen Links gegenuebergestellt. Das wiederhole ich heute nicht, denn es ist nur von Interesse ob Erstere reproduziert werden. … Und ich wuerde mal sagen …
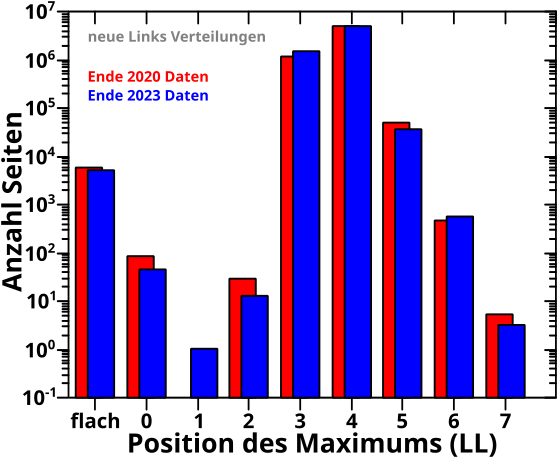
… das man das so sehen kann. Ich muss das nicht weiter besprechen, denn ich wuerde nur das weiter oben Geschriebene wiederholen. Heraus sticht nur die eine (!) neue Seite mit dem Maximum auf LL1; aber auch das wurde oben schon behandelt.
Nun zu den Selbstreferenzen. Damals wurde ich stutzig, denn der LL0-Balken war zu hoch. Nur durch diesen einen Balken entdeckte ich dann die Archipele! Aber das dauert noch ein bisschen, bevor ich dort angelangt bin.
Hier ist die Reproduktion (sagt man das so?) der Verteilung der Maximaspositionen der Selbstreferenzkurven aller Seiten:
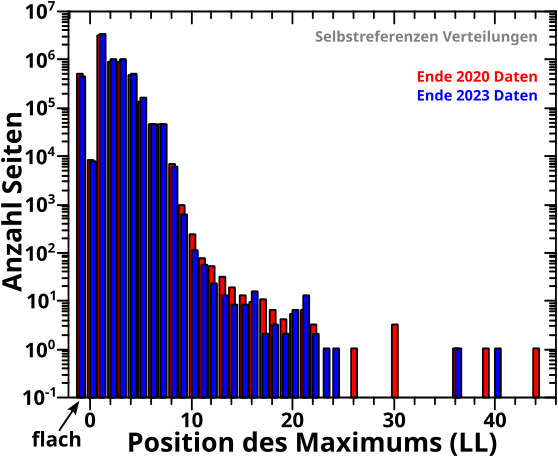
Uff! Der Balkenwald wird dichter. Aber wenn man genau hinschaut, dann sieht man, dass die roten und blauen Balken auch hier wieder im Wesentlichen uebereinstimmen. Mit møglicherweise (!) einer kleinen, møglicherweise (!) systematischen, Abweichung zwischen LL8 und … mhm … schwer zu sagen … ich sag jetzt mal LL19. Bis auf einen Balken sind dort naemlich alle blauen Balken kleiner, es gibt also kein „rauschendes Auf und Ab“ … das kønnte was sein, das lohnt sich also mglw. mal naeher zu untersuchen (ich werde das aber nicht tun) … ich wuerde aber erstmal nicht unbedingt ’ne Wette drauf abschlieszen, dass da wirklich ein echtes Phaenomen hinter ist. „Statistik“ macht manchmal komische Sachen (ich erinnere an dieser Stelle an die wohlbekannte, 5σ sichere, „Entdeckung“ des Θ+-Pentaquarks in den Nullerjahren, die sich dann als falsch herausstellte).
Alles in allem gilt auch hier: Reproduktion (wenn man das so sagt) gelungen.
Als Letztes bleibt die Verteilung der Maxima der Linkfrequenzkurven. Damals war es die erste konkrete Bestaetigung, dass da irgendwie mehr am „São Paulo FC“-Artefakt sein muss (und es war, aber so weit bin ich auch hier noch laengst nicht). Die Reproduktion (ich sag das jetzt einfach so) …
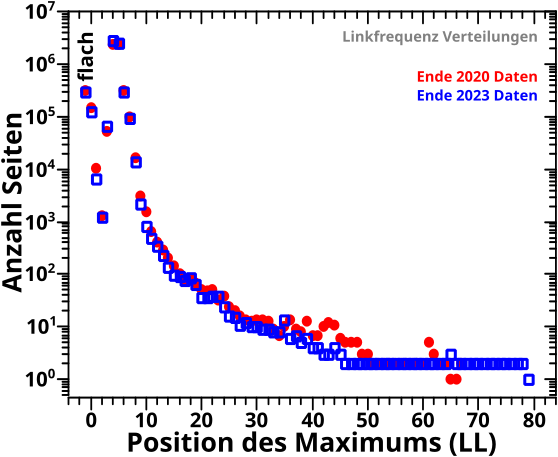
… ist wieder als erfolgreich anzusehen … auch wenn dabei der Balkenwald zu dicht wurde um noch was zu erkennen, weswegen ich (wie so oft) auf ein Streudiagramm fuer das Histogramm zurueckgriff.
Im Wesentlichen hat man das gleiche Resultat wie bei allen anderen Verteilungen: die 2023-Daten reproduzieren die 2020-Daten. Es gibt møglicherweise (!) eine kleine, møglicherweise (!) systematische, Abweichung kurz nach LL40. Die 2020-Daten „beulen“ sich da etwas aus. Aber insgesamt sprechen wir von nur sehr wenigen beteiligten Seiten und ich wuerde hier noch weniger drauf wetten, dass da was ist. Das sollte mal wer untersuchen … lohnt sich mglw.
Puuuh … das war jetzt ’n ganz schøner Ritt. Aber ich habe viel geschafft.
Nun ist’s aber so, dass auch in diesem Fall die Auswerteprogramme neu von mir geschrieben und generalisiert wurden. Deswegen faellt jetzt bei der Analyse eine weitere Sache an, die mir bei den damaligen Betrachtungen ueberhaupt nicht in den Sinn kam: wenn ich die Position des Maximums kenne, dann kenne ich auch den WERT des Maximums und da kann man sich die Verteilungen doch auch mal anschauen. DAS, meine lieben Leserinnen und Leser, verschiebe ich aber auf’s naechste Mal.
Leave a Reply